OpenAI officially launched GPT-5, the most advanced model in its history. This wasn’t just a routine upgrade—it represented a bold leap toward a unified...
In the rapidly evolving world of artificial intelligence (AI), the ability to push the boundaries of scientific discovery is a tantalizing prospect. Imagine an...
In today’s digital age, approximately 90% of organizational data worldwide is stored in documents—ranging from scientific reports and legal contracts to handwritten notes and...
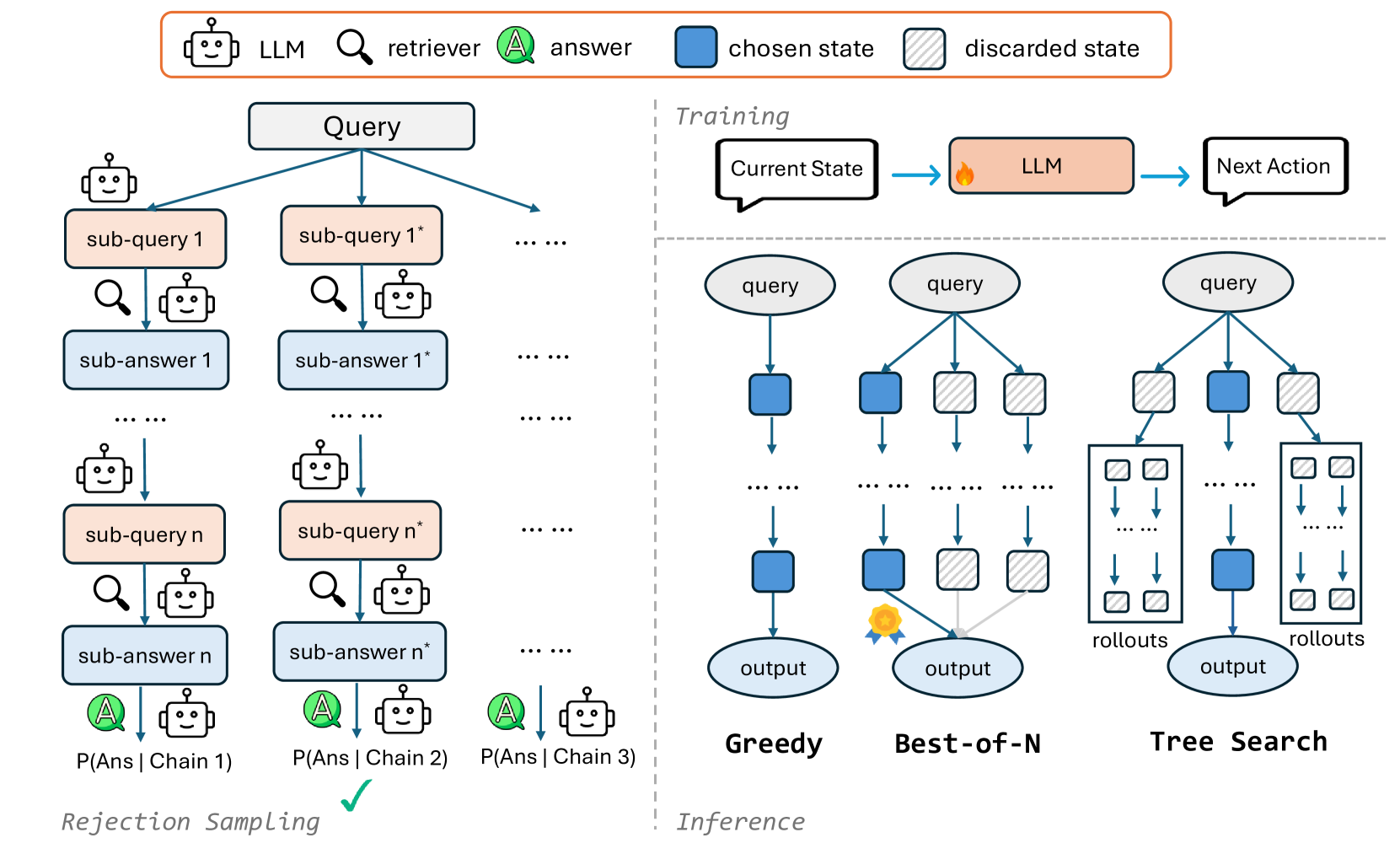
Large Language Models (LLMs) have demonstrated powerful content generation capabilities, but they often struggle with accessing the latest information, leading to hallucinations. Retrieval-Augmented Generation...
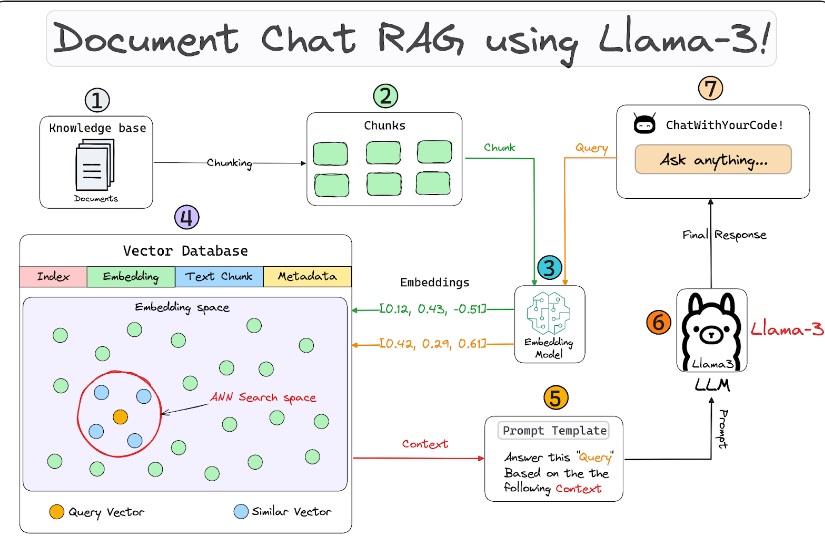
Building a robust RAG application involves a lot of moving parts, the architecture diagram presented below illustrates some of the key components & how...
In today’s information technology world, artificial intelligence (AI) and machine learning (ML) are continuously evolving and contributing to significant changes in how we interact...
GitHub Copilot, a new product from GitHub, is changing the way we code. Described as an “AI pair programmer,” GitHub Copilot uses artificial intelligence...
In the rapidly evolving technological era we’re in today, artificial intelligence (AI) is becoming one of the most talked-about trends. However, developing and deploying...
What is AI? AI is a branch of computer science that focuses on creating systems capable of performing tasks that usually require human intervention....
Imagine that you have launched a Shopify ecommerce store and you’re seeing an increase in sales. You’ve also learned that analyzing the various metrics...