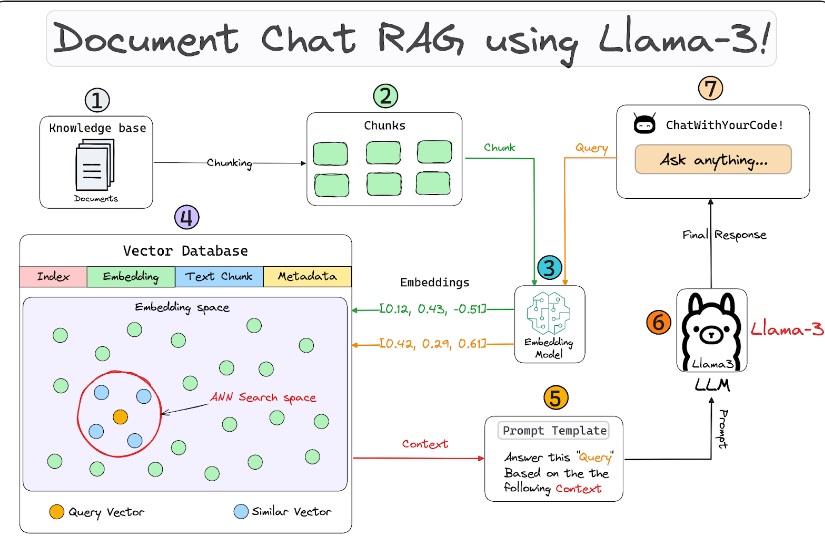
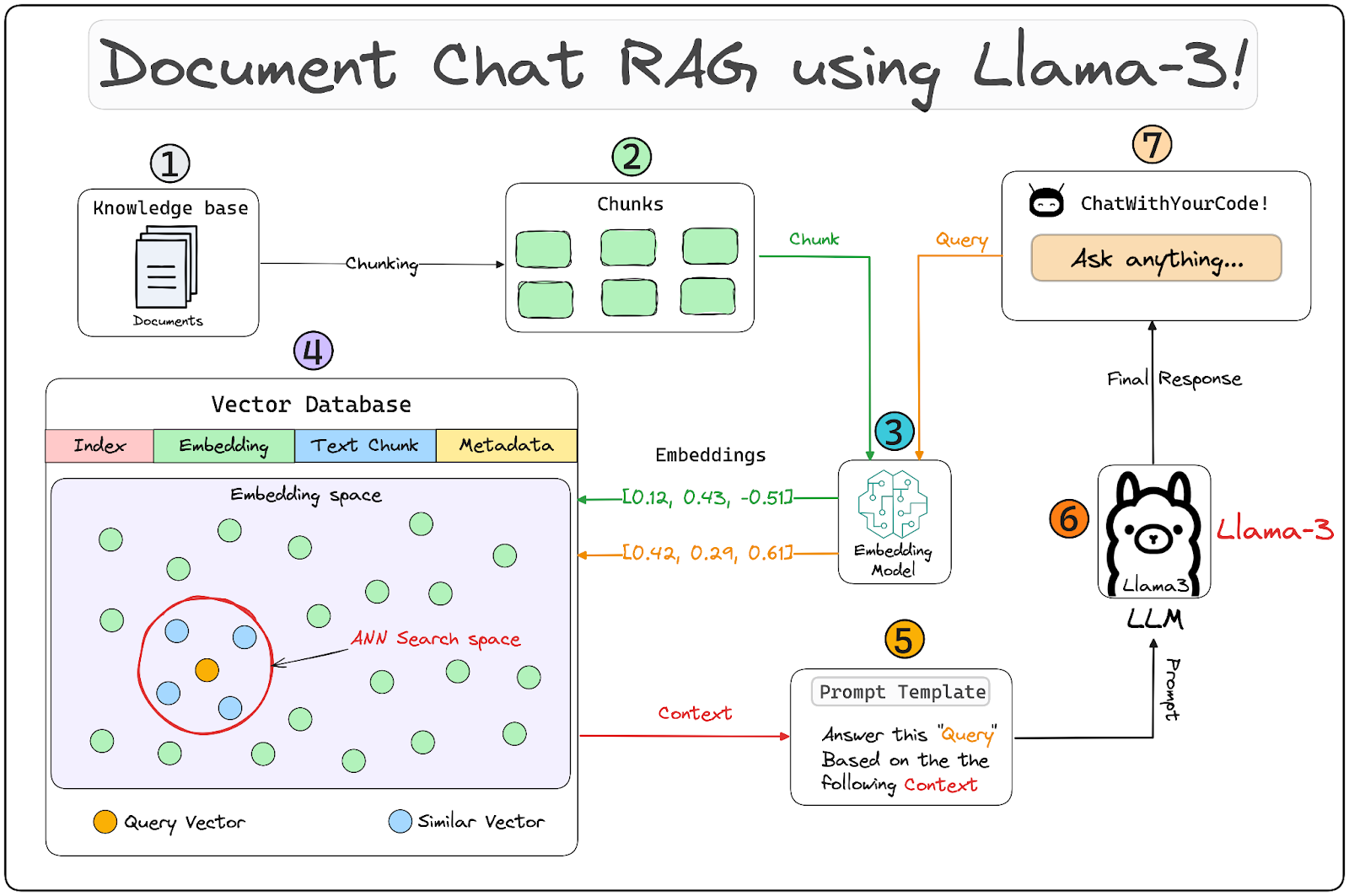
Building a robust RAG application involves a lot of moving parts, the architecture diagram presented below illustrates some of the key components & how they interact with each other, followed by detailed descriptions of each component, we’ve used:
– LlamaIndex for orchestration
– Streamlit for creating a Chat UI
– Meta AI’s Llama3 as the LLM
– “BAAI/bge-large-en-v1.5” for embedding generation
1. Custom knowledge base
Custom Knowledge Base: A collection of relevant and up-to-date information that serves as a foundation for RAG. It can be a database, a set of documents, or a combination of both. In this case it’s a PDF provided by you that will be used as a source of truth to provide answers to user queries.
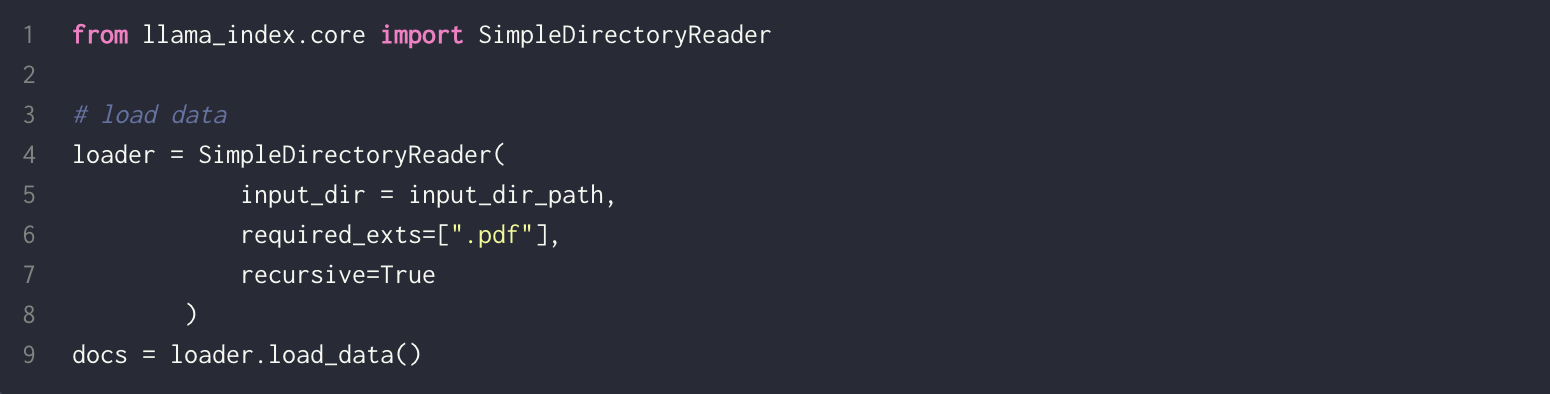
2. Chunking
Chunking is the process of breaking down a large input text into smaller pieces. This ensures that the text fits the input size of the embedding model and improves retrieval efficiency.
Following code will load pdf documents from a directory specified by the user using LlamaIndex’s SimpleDirectoryReader:
3. Embeddings model
A technique for representing text data as numerical vectors, which can be input into machine learning models. The embedding model is responsible for converting text into these vectors.

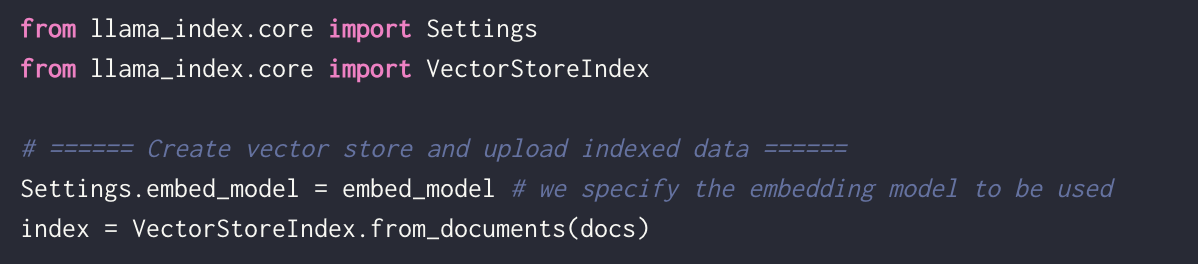
4. Vector databases
A collection of pre-computed vector representations of text data for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, and horizontal scaling. By default, LlamaIndex uses a simple in-memory vector store that’s great for quick experimentation.
5. User chat interface
A user-friendly interface that allows users to interact with the RAG system, providing input query and receiving output. We have built a streamlit app to do the same. The code for it can be found in app.py
6. Query engine
The query engine takes a query string to use it to fetch relevant context and then sends them both as a prompt to the LLM to generate a final natural language response. The LLM used here is Llama3 which is served locally, thanks to Ollama The final response is displayed in the user interface.

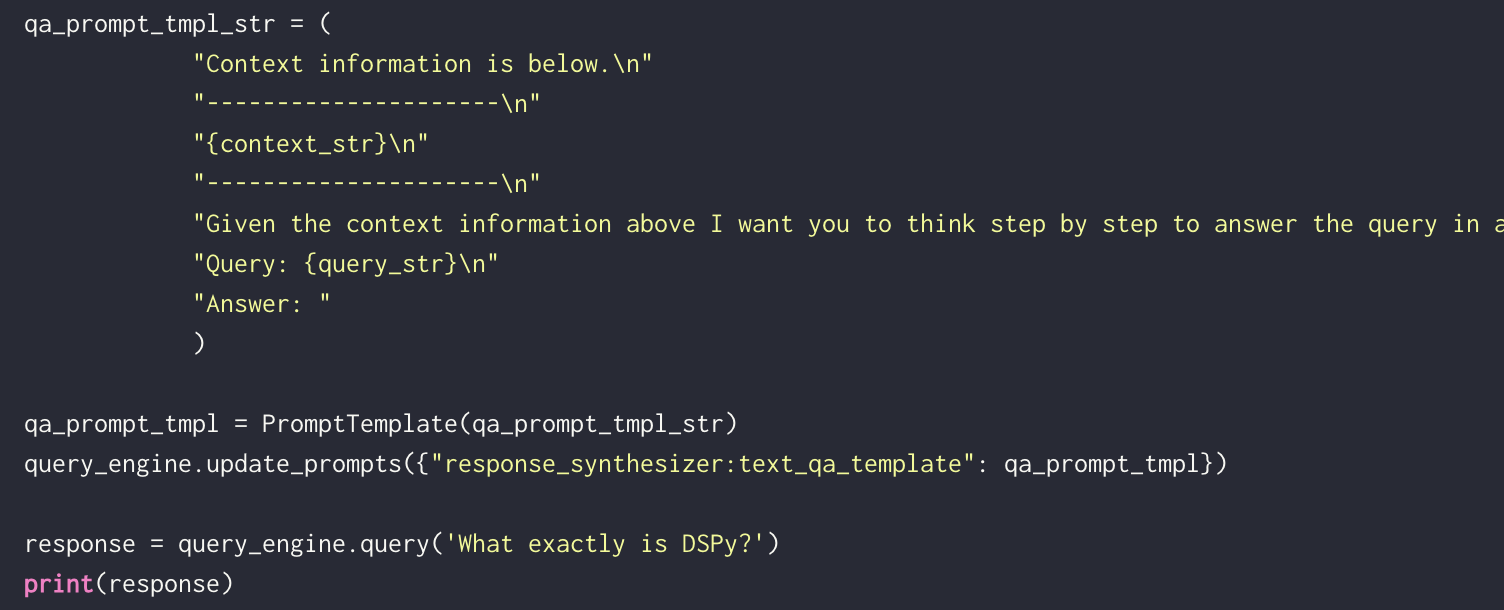
7. Prompt template
A custom prompt template is use to refine the response from LLM & include the context as well:
Conclusion
In this studio, we developed a Retrieval Augmented Generation (RAG) application that allows you to “Chat with your docs.” Throughout this process, we learned about LlamaIndex, the go to library for building RAG applications & Ollama for locally serving LLMs, in this case we served Llama3 that was recently released by MetaAI.
We also explored the concept of prompt engineering to refine and steer the responses of our LLM. These techniques can similarly be applied to anchor your LLM to various knowledge bases, such as documents, PDFs, videos, and more.