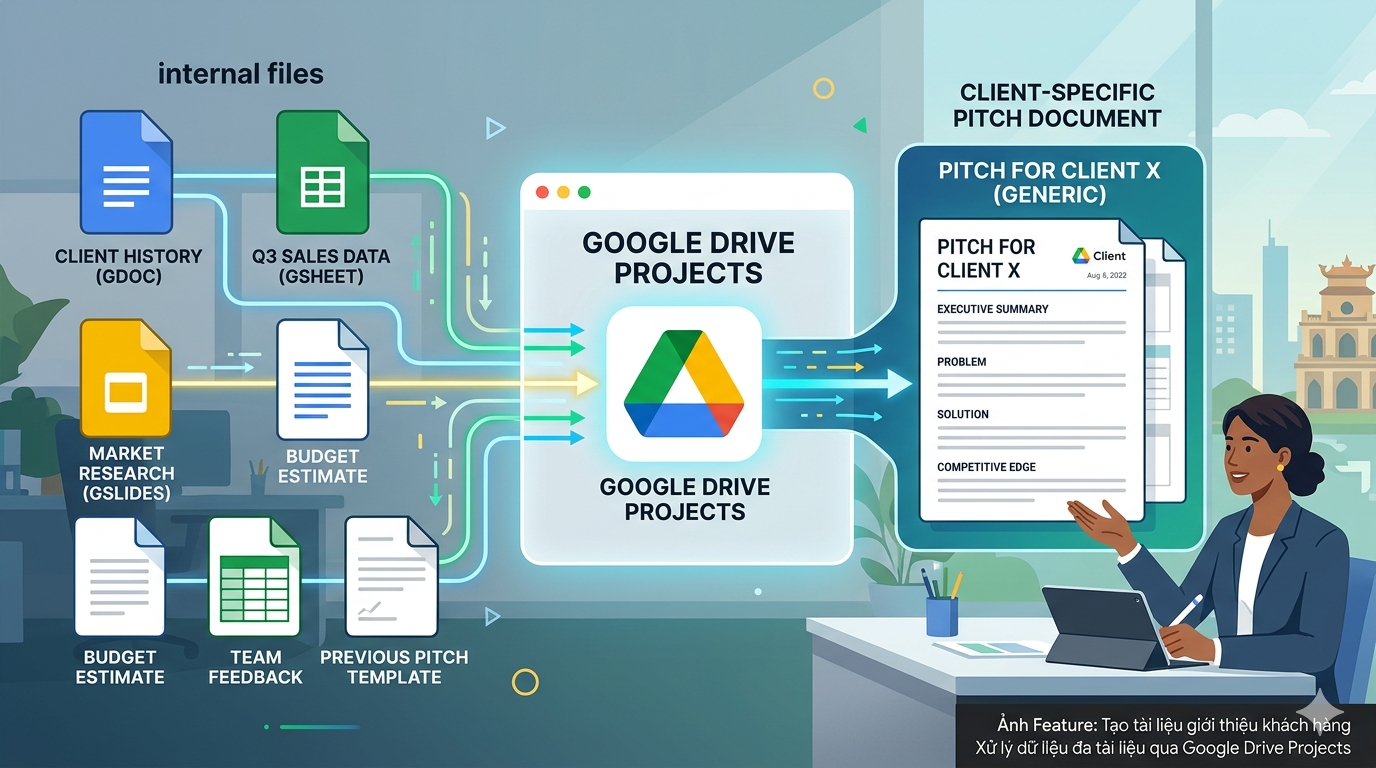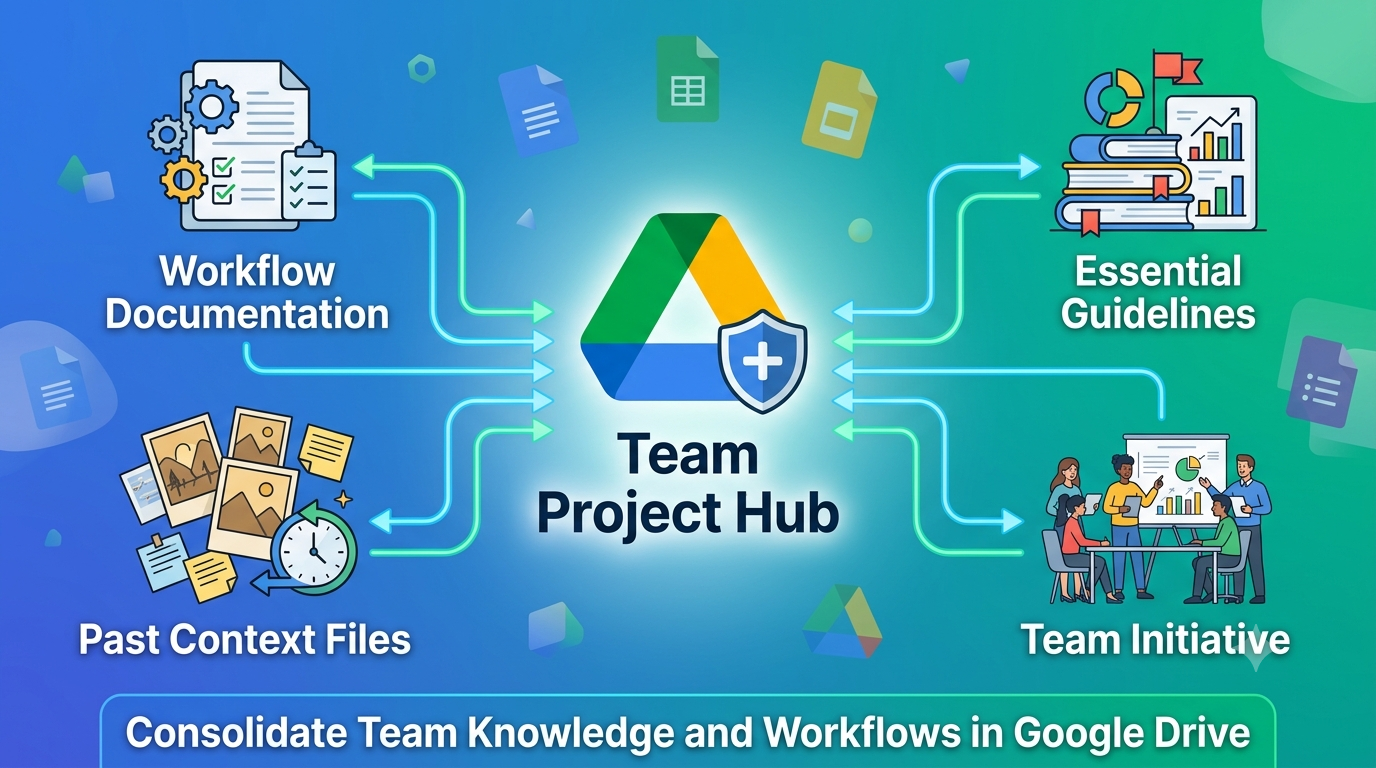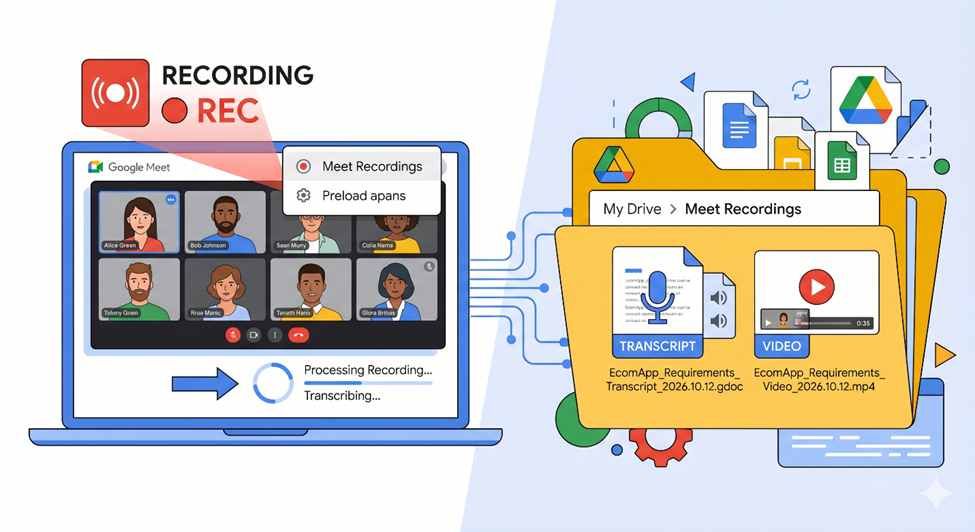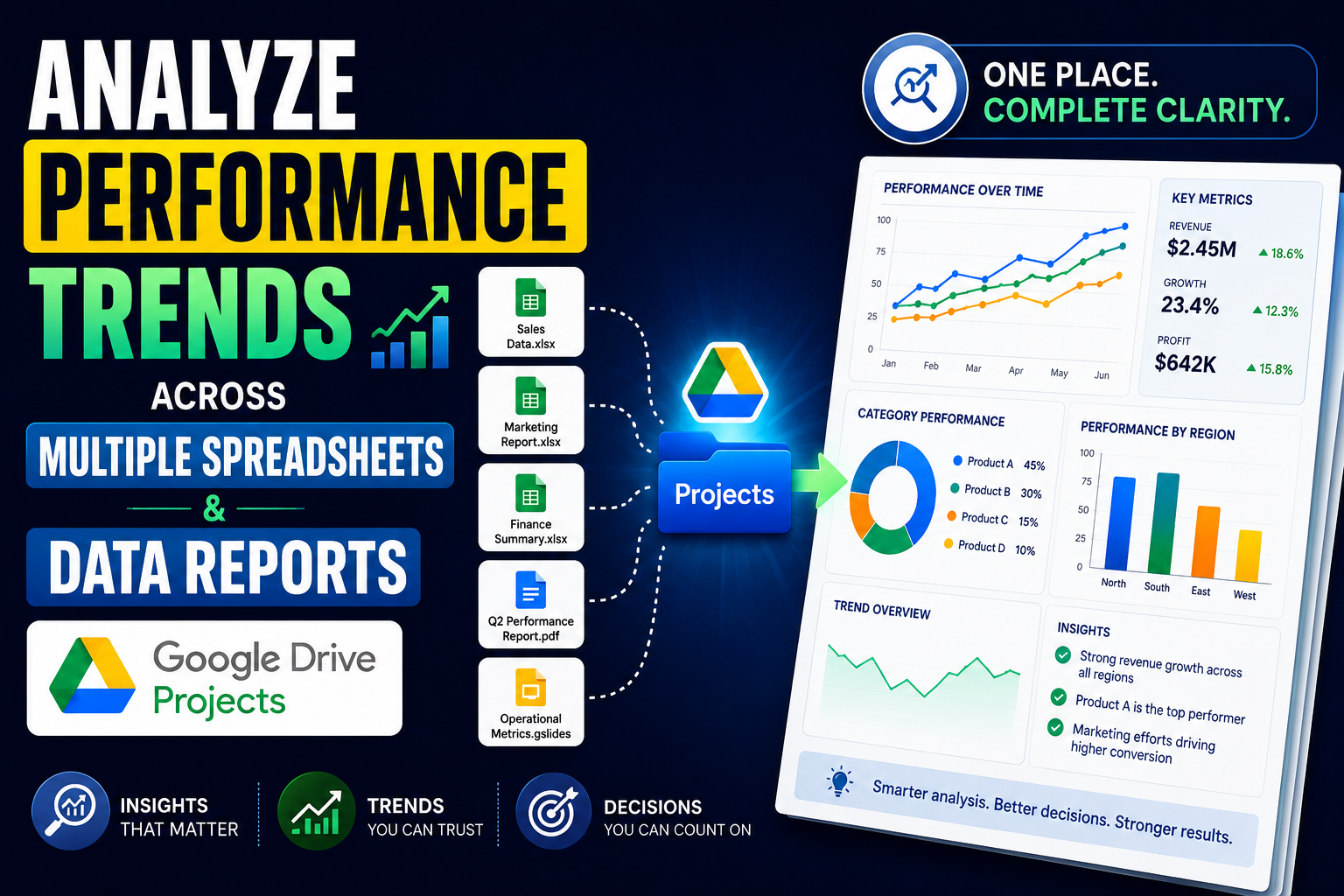
Analyze performance trends across multiple spreadsheets and data reports using Google Drive Projects
Introduction Google Drive Projects with Ask Gemini in Drive let you pin multiple Google Sheets and PDF reports (by quarter or period) as fixed sources, then ask...