Xin chào, tôi là Kakeya, đại diện của công ty Scuti.
Công ty chúng tôi chuyên cung cấp các dịch vụ như Phát triển phần mềm offshore và phát triển theo hình thức Labo tại Việt Nam, cũng như Cung cấp giải pháp AI tạo sinh. Gần đây, chúng tôi rất vinh dự khi nhận được nhiều yêu cầu phát triển hệ thống kết hợp với AI tạo sinh.
Dành cho những ai gặp khó khăn trong việc trích xuất dữ liệu từ các tài liệu không chuẩn, sự tiến bộ của công nghệ AI OCR đã giúp việc trích xuất dữ liệu một cách chính xác và hiệu quả từ các bố cục phức tạp và chữ viết tay trở nên khả thi. Việc tự động hóa các công việc nhập liệu và kiểm tra dữ liệu, vốn trước đây được thực hiện thủ công, giúp giảm đáng kể thời gian và chi phí, đồng thời ngăn ngừa sai sót do con người gây ra.
Bài viết này sẽ giải thích chi tiết cách AI OCR đơn giản hóa việc trích xuất dữ liệu từ các tài liệu không chuẩn và đóng góp vào việc nâng cao hiệu quả công việc. Nó sẽ trình bày các bước cụ thể, các ví dụ ứng dụng và những điểm cần lưu ý khi triển khai công nghệ này. Việc áp dụng AI OCR có thể giúp công việc của bạn tiến triển một cách mạnh mẽ
Kiến Thức Cơ Bản Về AI OCR Và Ứng Dụng Của Nó Đối Với Các Tài Liệu Không Chuẩn

Nếu bạn muốn tìm hiểu thêm về AI OCR, hãy xem trước bài viết này.
Bài viết liên quan: AI OCR là gì? Giải thích chi tiết về công nghệ mới nhất và các trường hợp ứng dụng trong ngành.
AI OCR Là Gì? Hiểu Về Công Nghệ Và Cơ Chế Của Nó
AI OCR (Nhận dạng ký tự quang học) là một công nghệ tự động nhận dạng thông tin văn bản từ các tài liệu kỹ thuật số như hình ảnh quét và PDF, sau đó chuyển đổi chúng thành dữ liệu văn bản. OCR truyền thống chỉ giới hạn đối với các tài liệu có phông chữ và bố cục chuẩn, nhưng nhờ sự tiến bộ của công nghệ AI, việc nhận dạng ký tự chính xác cao giờ đây có thể thực hiện được ngay cả với các tài liệu không chuẩn, bao gồm chữ viết tay hoặc bố cục phức tạp.
Bằng cách kết hợp công nghệ xử lý hình ảnh, xử lý ngôn ngữ tự nhiên và học máy, AI OCR hiểu nội dung của tài liệu và trích xuất thông tin cần thiết. Đặc biệt, AI OCR sử dụng học sâu (deep learning) đã cải thiện đáng kể khả năng xử lý các tài liệu không chuẩn nhờ việc học từ một lượng lớn dữ liệu.
Lợi Ích Của AI OCR Trong Việc Xử Lý Tài Liệu Không Chuẩn
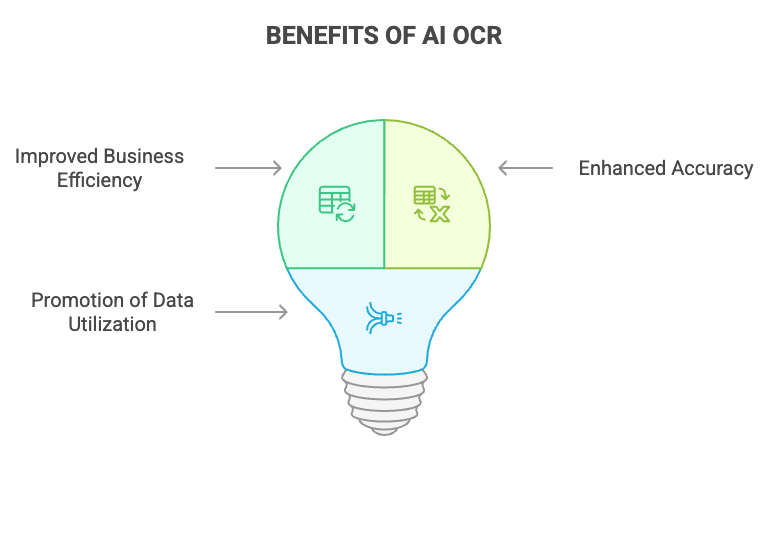
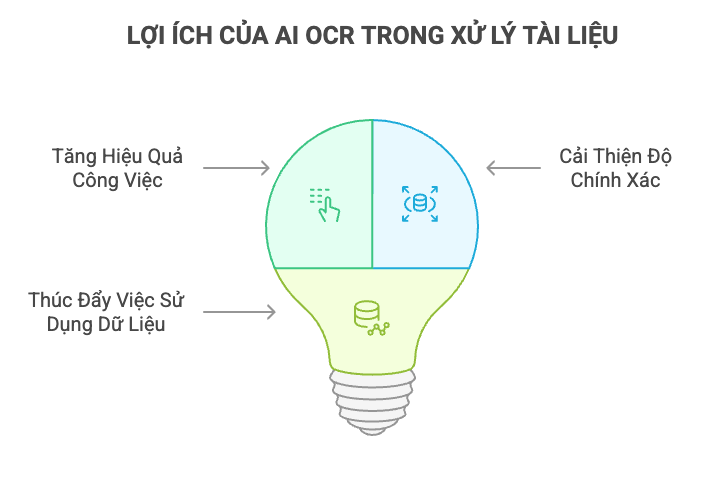
AI OCR mang lại nhiều lợi ích trong việc xử lý các tài liệu không chuẩn.
- Tăng hiệu quả công việc: Tự động hóa việc nhập liệu dữ liệu vốn trước đây được thực hiện thủ công giúp tiết kiệm thời gian và giảm chi phí đáng kể.
- Cải thiện độ chính xác: Ngăn ngừa sai sót do con người giúp cải thiện độ chính xác của việc nhập liệu dữ liệu.
- Thúc đẩy việc sử dụng dữ liệu: Dữ liệu đã được trích xuất có thể được phân tích để góp phần vào việc cải tiến công việc và ra quyết định.
Những Ví Dụ Cụ Thể Về Việc Ứng Dụng AI OCR

Cải Thiện Hiệu Quả Công Việc Thông Qua Tự Động Hóa Việc Xử Lý Hóa Đơn
AI OCR rất hiệu quả trong việc tự động hóa xử lý hóa đơn. Các công ty nhận được rất nhiều hóa đơn hàng ngày, nhưng việc xử lý chúng thủ công tốn rất nhiều thời gian và công sức. Bằng cách triển khai AI OCR, có thể tự động trích xuất các thông tin cần thiết từ hóa đơn (chẳng hạn như số hóa đơn, ngày hóa đơn, tên nhà cung cấp, số tiền hóa đơn, và số tiền thuế giá trị gia tăng) và tích hợp vào hệ thống kế toán.
Ví dụ, phần mềm AI OCR như Docsumo có khả năng trích xuất dữ liệu chính xác cao, giúp việc xử lý hóa đơn diễn ra một cách suôn sẻ. Điều này giúp ngăn ngừa các lỗi nhập liệu thủ công và cải thiện hiệu quả công việc
Trích Xuất Dữ Liệu Tự Động Để Tối Ưu Hóa Quản Lý Hợp Đồng
Quản lý hợp đồng cũng là một lĩnh vực có thể áp dụng AI OCR. Các hợp đồng chứa những thông tin quan trọng như ngày hết hạn hợp đồng, ngày gia hạn, các bên tham gia và số tiền hợp đồng, nhưng việc quản lý thủ công là rất khó khăn. Bằng cách sử dụng AI OCR, có thể tự động trích xuất thông tin cần thiết từ hợp đồng và lưu trữ vào cơ sở dữ liệu.
Điều này cho phép xây dựng một hệ thống tự động thông báo thời gian gia hạn hợp đồng. Kết quả là, hiệu quả và độ chính xác trong quản lý hợp đồng sẽ được cải thiện đáng kể.
Trích Xuất Tự Động Dữ Liệu Hồ Sơ Y Tế Và Báo Cáo Chuẩn Đoán Trong Lĩnh Vực Y Tế
Việc sử dụng AI OCR cũng đang phát triển trong lĩnh vực y tế. Các tài liệu y tế như hồ sơ bệnh án và báo cáo chẩn đoán thường chứa nhiều chữ viết tay và thuật ngữ chuyên ngành, khiến việc số hóa chúng trở nên khó khăn. Bằng cách áp dụng AI OCR, có thể tự động trích xuất các thông tin cần thiết như tên bệnh nhân, ngày sinh, chẩn đoán và đơn thuốc từ các tài liệu này và tích hợp chúng vào hệ thống hồ sơ y tế điện tử.
Điều này giúp giảm bớt gánh nặng công việc cho các nhân viên y tế và việc chia sẻ thông tin y tế trở nên thuận tiện hơn. Việc triển khai AI OCR đóng góp lớn vào việc nâng cao hiệu quả và độ chính xác trong các cơ sở y tế.
Các Bước Cụ Thể Để Triển Khai AI OCR

Các Bước Làm Rõ Mục Tiêu Và Yêu Cầu
Trước khi triển khai AI OCR, việc làm rõ mục tiêu muốn đạt được là rất quan trọng. Ví dụ, đặt ra các mục tiêu cụ thể như “Giảm 50% thời gian xử lý hóa đơn” hoặc “Loại bỏ tình trạng bỏ sót gia hạn hợp đồng.”
Ngoài ra, yêu cầu đối với AI OCR cũng cần được làm rõ. Điều này bao gồm việc xác định loại tài liệu cần xử lý, các trường dữ liệu cần thiết, mục tiêu độ chính xác, và yêu cầu tích hợp hệ thống, nhằm xây dựng nền tảng cho việc vận hành suôn sẻ sau khi triển khai.
Cách Chọn Phần Mềm AI OCR Phù Hợp
Phần mềm AI OCR có nhiều loại khác nhau, mỗi sản phẩm có các tính năng và đặc điểm khác nhau. Việc chọn sản phẩm phù hợp với mục tiêu và yêu cầu của bạn là rất quan trọng. Ví dụ, Docsumo hỗ trợ nhiều loại tài liệu không chuẩn như hóa đơn, hợp đồng và biên lai, cung cấp khả năng trích xuất dữ liệu chính xác cao và giao diện dễ sử dụng.
Ngoài ra, nó còn có khả năng tích hợp mạnh mẽ với các hệ thống hiện có, giúp việc vận hành sau khi triển khai diễn ra suôn sẻ. Việc so sánh các tính năng của từng sản phẩm và chọn phần mềm phù hợp nhất với nhu cầu của công ty bạn là chìa khóa thành công.
Chuẩn Bị Dữ Liệu Và Quy Trình Huấn Luyện Mô Hình AI OCR
Để cải thiện độ chính xác của AI OCR, việc chuẩn bị dữ liệu phù hợp và huấn luyện mô hình là rất cần thiết. Đầu tiên, thu thập dữ liệu mẫu của các tài liệu cần xử lý và huấn luyện mô hình AI OCR. Càng có nhiều dữ liệu huấn luyện, độ chính xác nhận diện của mô hình sẽ càng cao.
Đặc biệt, việc chuẩn bị dữ liệu đa dạng, bao gồm cả chữ viết tay và tài liệu có bố cục phức tạp là rất quan trọng. Điều này giúp mô hình AI OCR có thể xử lý các mẫu tài liệu đa dạng và trích xuất dữ liệu với độ chính xác cao trong quá trình vận hành thực tế.
Cách Đạt Được Sự Tích Hợp Suôn Sẻ với Các Hệ Thống Hiện Có
Để tận dụng hiệu quả dữ liệu được trích xuất bằng AI OCR, việc tích hợp với các hệ thống kế toán và hệ thống nghiệp vụ hiện có là điều không thể thiếu. Ví dụ, dữ liệu trích xuất từ hóa đơn có thể được tự động nhập vào hệ thống kế toán, hoặc thông tin từ hợp đồng có thể được đăng ký vào hệ thống quản lý hợp đồng.
Khi chọn phần mềm AI OCR, việc kiểm tra khả năng tích hợp với các hệ thống hiện có là rất quan trọng. Điều này mở rộng phạm vi sử dụng dữ liệu và giúp nâng cao hiệu quả công việc tổng thể.
Những Lưu Ý Và Giải Pháp Cho Các Vấn Đề Khi Triển Khai AI OCR

Các Thách Thức Trong Việc Cải Thiện Độ Chính Xác Đối Với Chữ Viết Tay Và Bố Cục Phức Tạp
AI OCR có thể gặp khó khăn trong việc nhận dạng chữ viết tay và các tài liệu có bố cục phức tạp. Đặc biệt, khi ký tự không rõ ràng hoặc bố cục bị sai lệch, độ chính xác nhận dạng có thể bị giảm. Để nâng cao độ chính xác, việc sử dụng máy quét chất lượng cao và thực hiện xử lý hình ảnh trước là rất hiệu quả.
Ngoài ra, việc huấn luyện mô hình AI OCR với dữ liệu đa dạng có thể cải thiện độ chính xác nhận dạng. Việc cải tiến mô hình liên tục và tăng cường dữ liệu là chìa khóa để nâng cao độ chính xác.
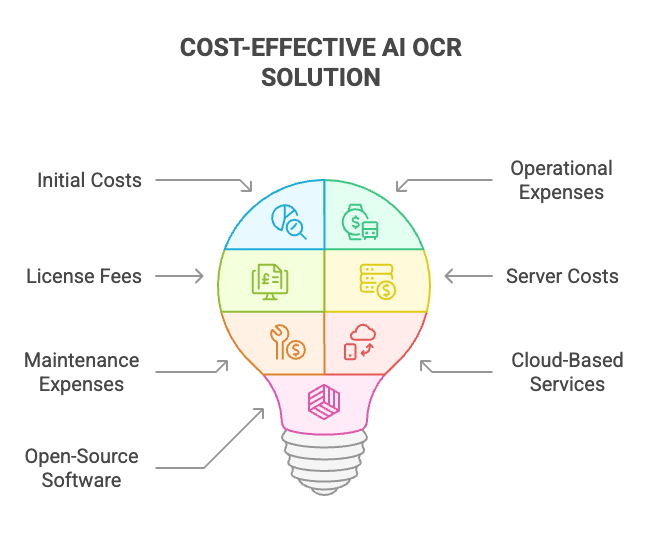
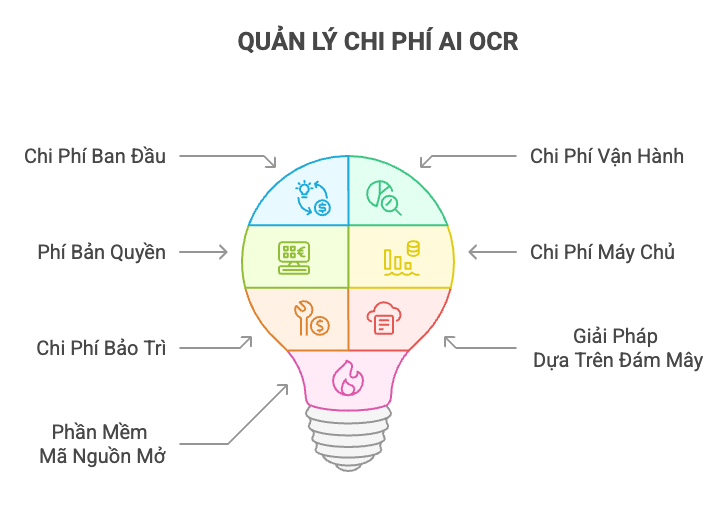
Cách Cân Bằng Giữa Chi Phí Triển Khai Và Chi Phí Vận Hành
Việc triển khai phần mềm AI OCR phát sinh chi phí ban đầu và chi phí vận hành. Cần xem xét các khoản chi như phí bản quyền, chi phí máy chủ và chi phí bảo trì, đồng thời chú trọng đến hiệu quả chi phí.
Để giảm thiểu chi phí, có thể sử dụng dịch vụ AI OCR dựa trên nền tảng đám mây hoặc tận dụng phần mềm AI OCR mã nguồn mở. Việc lựa chọn giải pháp phù hợp với ngân sách và nhu cầu của doanh nghiệp là rất quan trọng, hướng tới việc giảm chi phí trong dài hạn.
Tầm Quan Trọng Của Việc Bảo Vệ Thông Tin Mật Và Thực Hiện Các Biện Pháp Bảo Mật
Các tài liệu được xử lý bằng AI OCR có thể chứa thông tin cá nhân hoặc thông tin mật. Do đó, việc thực hiện các biện pháp bảo mật là vô cùng quan trọng. Khi lựa chọn phần mềm AI OCR, cần ưu tiên các sản phẩm có tính năng bảo mật mạnh mẽ.
Cần thiết lập hợp lý nơi lưu trữ dữ liệu và quyền truy cập để ngăn chặn rò rỉ thông tin. Bằng cách thực hiện những biện pháp này, doanh nghiệp có thể yên tâm ứng dụng AI OCR và thúc đẩy hiệu quả công việc.
Tổng Kết: Trích Xuất Dữ Liệu Từ Tài Liệu Phi Cấu Trúc Một Cách Hiệu Quả Bằng AI OCR

AI OCR là một công cụ mạnh mẽ giúp tối ưu hóa việc trích xuất dữ liệu từ các tài liệu phi cấu trúc. Công nghệ này mang lại nhiều lợi ích như nâng cao hiệu quả công việc, tăng độ chính xác và tận dụng tốt dữ liệu. Khi triển khai, cần làm rõ mục tiêu và yêu cầu, đồng thời lựa chọn phần mềm AI OCR phù hợp.
Ngoài ra, cần chú ý đầy đủ đến các yếu tố như độ chính xác, chi phí và bảo mật. Việc ứng dụng hiệu quả AI OCR sẽ giúp giải quyết các thách thức trong xử lý tài liệu phi cấu trúc và nâng cao hiệu suất công việc.