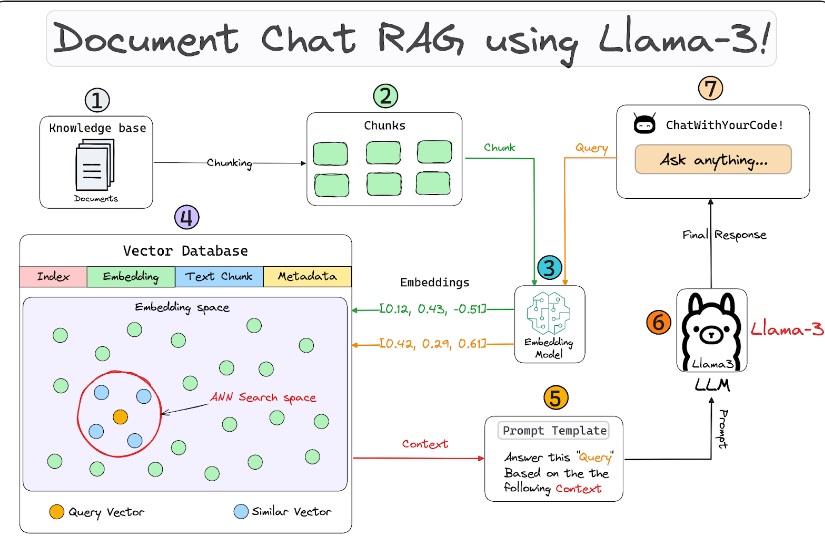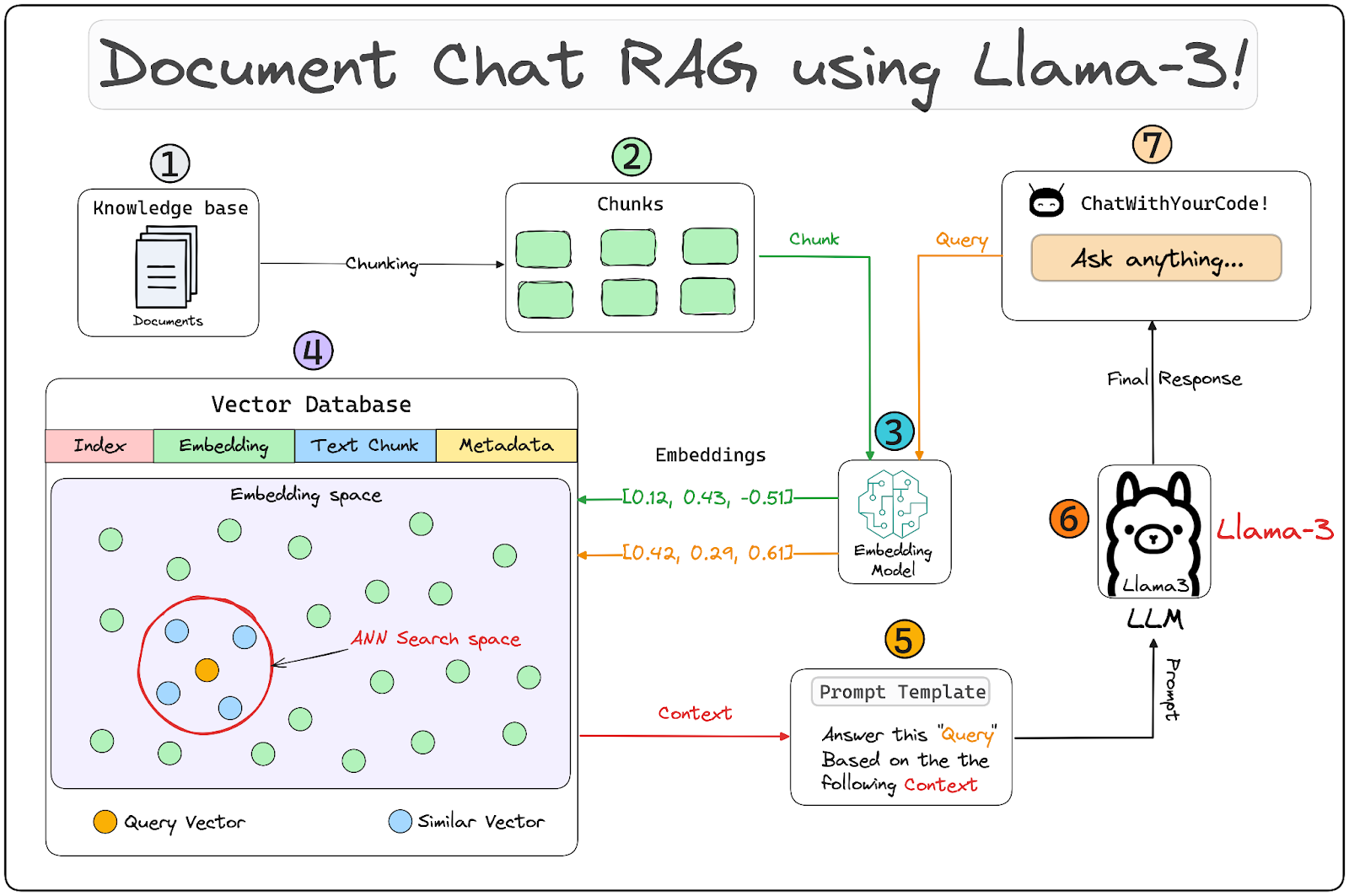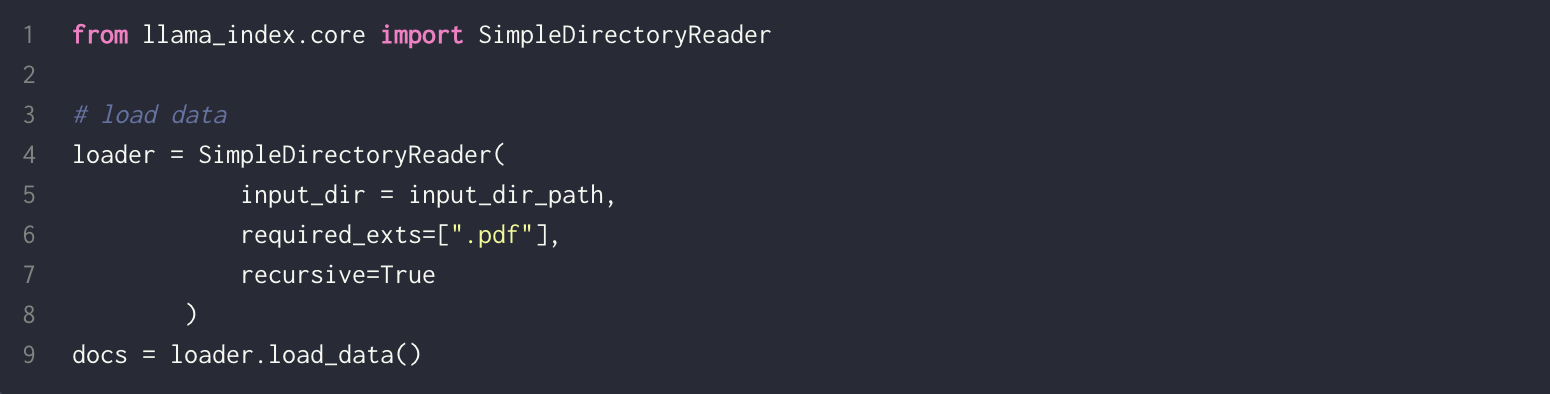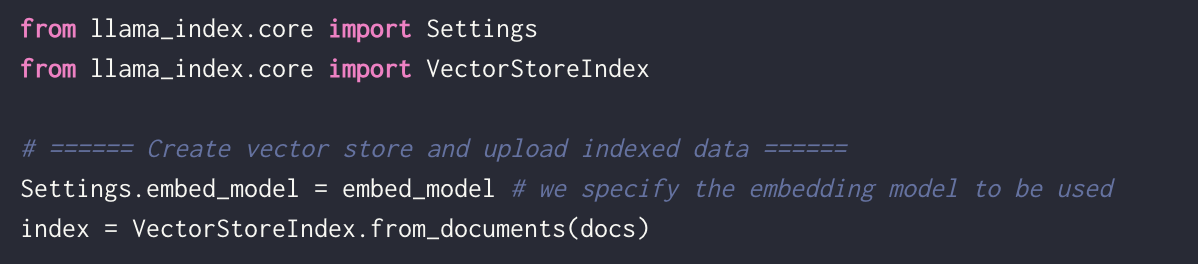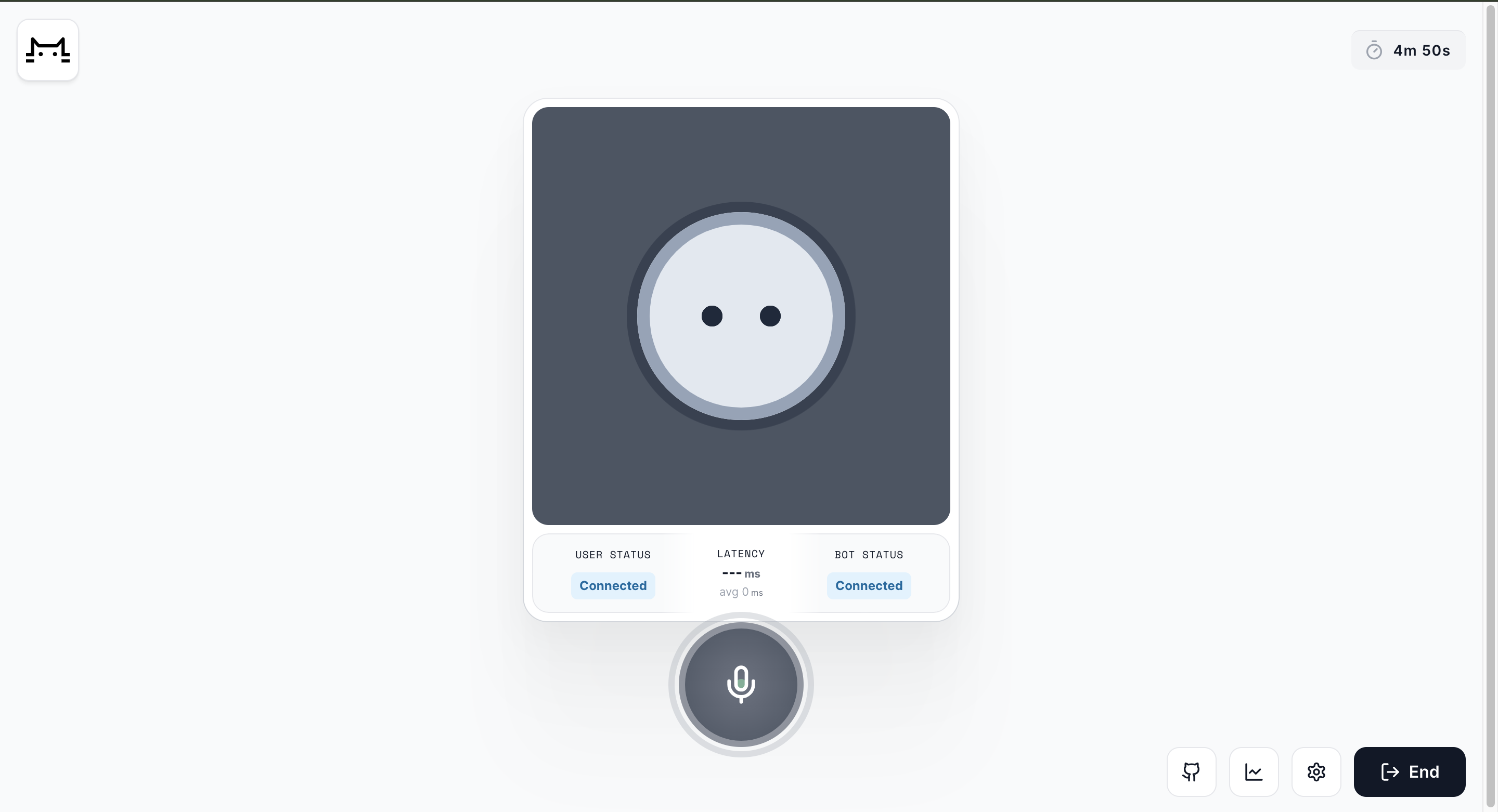
In the ever-evolving field of artificial intelligence, speed is paramount, particularly for voice AI interfaces. Daily, in partnership with Cerebrium, has reached a remarkable milestone by developing a voice bot that boasts a voice-to-voice response time as low as 500 milliseconds. This blog delves into the technological innovations and architectural strategies that have made this groundbreaking achievement possible.
Link for the demo AI voice bot : https://fastvoiceagent.cerebrium.ai
The Importance of Speed in Voice AI
For natural and seamless conversations, humans typically expect response times around 500 milliseconds. Delays longer than 800 milliseconds can disrupt the conversational flow and feel unnatural. Achieving such rapid response times in AI systems requires meticulous optimization across various technological components.
Core Components and Architecture

To construct this high-speed voice bot, Daily and Cerebrium employed cutting-edge AI models and optimized their deployment within a highly efficient network architecture. Here are the key elements:
- WebRTC for Audio Transmission: WebRTC (Web Real-Time Communication) is utilized to transmit audio from the user’s device to the cloud, ensuring minimal latency and high reliability.
- Deepgram’s Models: Deepgram provides fast transcription (speech-to-text) and text-to-speech (TTS) models, both optimized for low latency. Deepgram’s Nova-2 transcription model can deliver transcript fragments in as little as 100 milliseconds, while their Aura voice model achieves a time to first byte as low as 80 milliseconds.
- Llama 3 LLM: The Llama 3 70B model, a highly capable large language model (LLM), is used for natural language processing. Running on NVIDIA H100 hardware, it can deliver a median time to first token latency of 80 milliseconds. (Check our blog about Llama 3 here )
Benefits of Self-Hosting

A significant strategy employed is self-hosting the AI models and bot code within the same infrastructure. This approach offers several advantages:
- Latency Reduction: Running transcription, LLM, and TTS models on the same hardware avoids the latency overhead associated with external network requests, saving 50-200 milliseconds per interaction.
- Enhanced Control: Self-hosting allows for precise tuning of latency-critical parameters such as voice activity detection and phrase end-pointing.
- Operational Efficiency: Efficient data piping between models ensures rapid processing of each conversational loop.
Overcoming Technical Challenges

Achieving low latency requires addressing several technical challenges:
- AI Model Performance: Ensuring that AI models generate output faster than human speech while maintaining high quality.
- Network Optimization: Minimizing the time taken for audio data to travel from the user’s device to the cloud and back.
- GPU Management: Efficiently managing GPU infrastructure to handle the computational demands of AI models.
Looking Forward
The development of the world’s fastest voice bot represents a significant leap in conversational AI, but the journey continues. With ongoing advancements in AI models and network technologies, further improvements in speed and reliability are anticipated. As AI technology evolves, we can expect even more responsive and natural interactions with voice bots, enhancing user experiences across various applications.
Key Takeaway
The collaboration between Daily and Cerebrium has set a new standard in voice AI by achieving unprecedented response times. By leveraging state-of-the-art AI models, optimized network architecture, and self-hosting strategies, they have created a system that meets and exceeds human expectations for conversational speed. This innovation paves the way for new possibilities in real-time voice applications, setting the stage for future advancements in AI-driven communication.
Source link