

Hello, I am Kakeya, the representative of Scuti.
Our company provides services such as offshore development and lab-type development in Vietnam, specializing in generative AI, as well as consulting related to generative AI. Recently, we have been fortunate to receive many requests for system development integrated with generative AI.
Anthropic has announced a new method called “Contextual Retrieval,” which enhances the accuracy of information retrieval in Retrieval-Augmented Generation (RAG).
Contextual Retrieval not only uses traditional keyword matching and semantic search but also deeply understands the context of the user’s query and task to provide more accurate and appropriate information. It is particularly effective for tasks where contextual understanding is critical, such as programming and technical questions.
This article will introduce an overview of Contextual Retrieval.
Before diving into the main topic, for those who want to confirm what generative AI or ChatGPT is, please refer to the following articles.
What is Contextual Retrieval?
Contextual Retrieval is a method that improves RAG’s search accuracy by adding contextual information to the fragments (chunks) of information retrieved from a knowledge base during RAG processes.
In RAG, documents are split into small chunks to create embeddings. However, if the chunks lack sufficient contextual information, search accuracy may decrease.
Contextual Retrieval addresses this issue by adding contextual information to the chunks before creating the embeddings. Specifically, it uses large language models (LLMs) to generate concise contextual explanations for each chunk, which are then added to the beginning of the chunk.
The Mechanism of Contextual Retrieval
Contextual Retrieval consists of the following processes:
- Chunk Splitting: First, the document is divided into meaningful units (chunks). Various methods can be used, such as splitting by a fixed number of characters, sentence boundaries, or headings.
- Context Generation: LLM is used to generate contextual information for each chunk based on the content of the entire document. For example, if a chunk says, “Compared to the previous quarter, the company’s revenue increased by 3%,” LLM analyzes the document and generates context such as “This chunk comes from ACME’s SEC filing for Q2 2023. The revenue for the previous quarter was… and the operating profit was…”.
- Adding Context to Chunks: The generated context is added to the beginning of the corresponding chunk.
- Embedding Creation: Embeddings are created using an embedding model for the chunks with added contextual information.
Example of Chunk Splitting in Conventional RAG vs Contextual Retrieval
- Conventional RAG Chunk Splitting: The document is split into chunks based on a fixed number of characters.
- Chunk 1: “ACME announced its Q2 2023 results. Revenue increased by 10% year-on-year…”
- Chunk 2: “…Compared to the previous quarter, the company’s revenue increased by 3%. This was…”
- Chunk 3: “…due to strong sales of new products.”
- Chunk Splitting Using Contextual Retrieval: The document is split into chunks with added context.
- Chunk 1: “This chunk comes from ACME’s SEC filing for Q2 2023. The revenue for the previous quarter was… and the operating profit was… ACME announced its Q2 2023 results. Revenue increased by 10% year-on-year…”
- Chunk 2: “This chunk comes from ACME’s SEC filing for Q2 2023. The revenue for the previous quarter was… and the operating profit was… Compared to the previous quarter, the company’s revenue increased by 3%. This was…”
- Chunk 3: “This chunk comes from ACME’s SEC filing for Q2 2023. The revenue for the previous quarter was… and the operating profit was… Strong sales of new products contributed to this increase.”
In this way, Contextual Retrieval clarifies which part of the document each chunk refers to and improves search accuracy by highlighting the chunk’s relationships with the surrounding content.
Differences from Conventional RAG
In conventional RAG, embeddings are created solely from the text of the chunk. However, in Contextual Retrieval, embeddings reflect both the text of the chunk and the contextual information from the entire document. This allows for more contextually appropriate chunks to be retrieved in response to search queries
The Mechanism of Information Retrieval in Contextual Retrieval
In Contextual Retrieval, information retrieval is performed through the following steps to efficiently obtain highly relevant information in response to a user’s query.
- Query Analysis: The user’s query is analyzed to extract keywords, phrases, and the intent behind the search.
- Embedding Retrieval: Based on the query analysis results, an embedding vector corresponding to the query is generated.
- Similarity Calculation: The embedding vector of the query is compared with the embedding vectors of the chunks stored in the knowledge base, and their similarity is calculated.
- Chunk Selection: Based on the similarity calculations, the most relevant chunks are selected from the top-ranking ones.
- Information Extraction: Information suitable for answering the query is extracted from the selected chunks.
- Response Generation: A response is generated based on the extracted information and presented to the user.
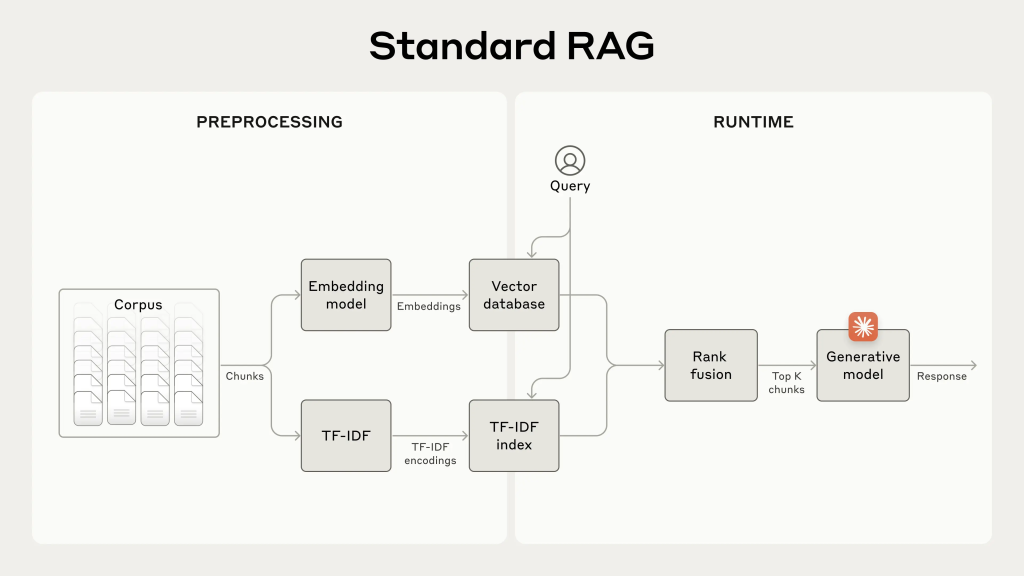
Conventional RAG Mechanism
Source: The figure is edited by the author and published in https://www.anthropic.com/news/contextual-retrieval.
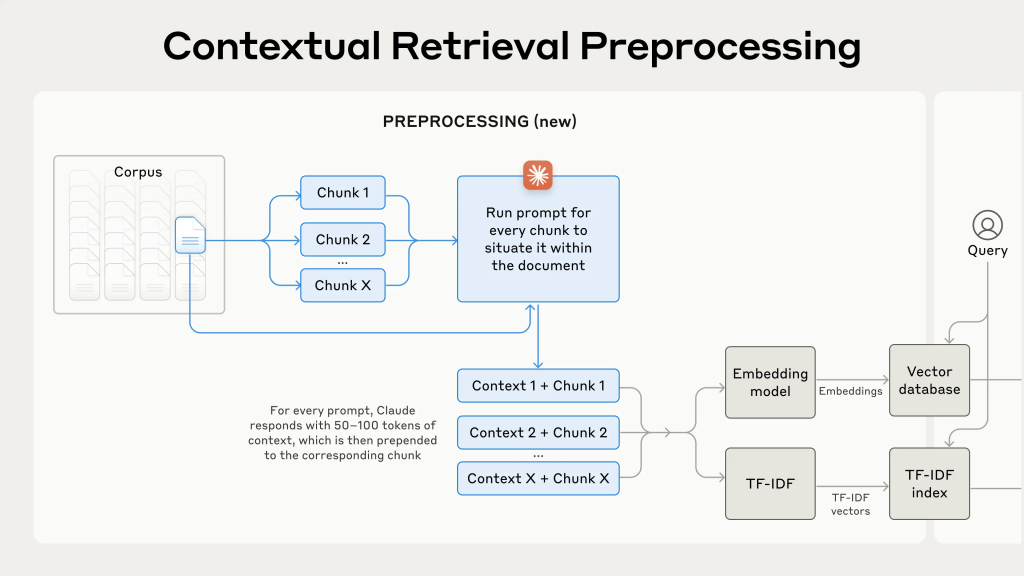
Preprocessing in Contextual Retrieval
Source: The figure is edited by the author and published in https://www.anthropic.com/news/contextual-retrieval.
Contextual Embeddings and Contextual BM25
In Contextual Retrieval, two methods—Contextual Embeddings and Contextual BM25—can be combined to enable information retrieval utilizing contextual information.
- Contextual Embeddings: Embeddings are created for chunks with contextual information added, using an embedding model. This allows for semantic similarity-based searches.
- Contextual BM25: BM25 is a widely-used method for information retrieval that scores the relevance of a document based on the matching between the query’s keywords and the document’s keywords. Contextual BM25 applies BM25 to chunks with added contextual information, allowing for searches that consider both keyword matching and contextual information.
By combining these methods, both semantic similarity and keyword matching are comprehensively evaluated to achieve more accurate search results.
Collaboration Between Contextual Embeddings and Contextual BM25
Contextual Embeddings and Contextual BM25 collaborate through the following approximate process:
- Scores are calculated for the query using both Contextual Embeddings and Contextual BM25.
- These scores are integrated based on predefined weighting.
- Based on the integrated scores, a ranking of chunks is created.
BM25 and TF-IDF
BM25 is an extended version of TF-IDF (Term Frequency-Inverse Document Frequency). TF-IDF calculates the importance of a word in a document based on the frequency with which the word appears in that document (Term Frequency) and the inverse frequency with which the word appears in other documents (Inverse Document Frequency). BM25 enhances TF-IDF by also considering factors such as document length and the number of terms in the query, thus achieving more accurate scoring.
Benchmark Results
Anthropic evaluated the performance of Contextual Retrieval across various datasets, including codebases, fiction, ArXiv papers, and scientific papers. The evaluation metric used was recall@20, which measures whether the top 20 chunks contain relevant documents.
The results showed that Contextual Retrieval improved search accuracy compared to traditional RAG:
- Using Contextual Embeddings alone reduced the failure rate of retrieving the top 20 chunks by 35% (from 5.7% to 3.7%).
- Combining Contextual Embeddings and Contextual BM25 reduced the failure rate by 49% (from 5.7% to 2.9%).
- Additionally, by incorporating a re-ranking step using Cohere’s re-ranking model, the failure rate for retrieving the top 20 chunks was reduced by 67% (from 5.7% to 1.9%).
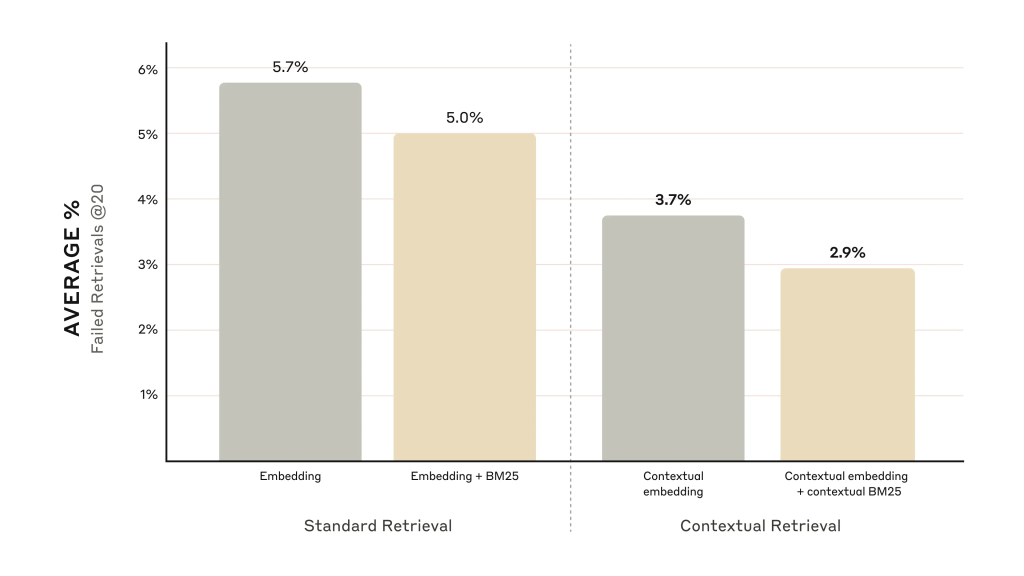
Comparison of failure rates using Contextual Embeddings alone and in combination with Contextual BM25.
Source: https://www.anthropic.com/news/contextual-retrieval
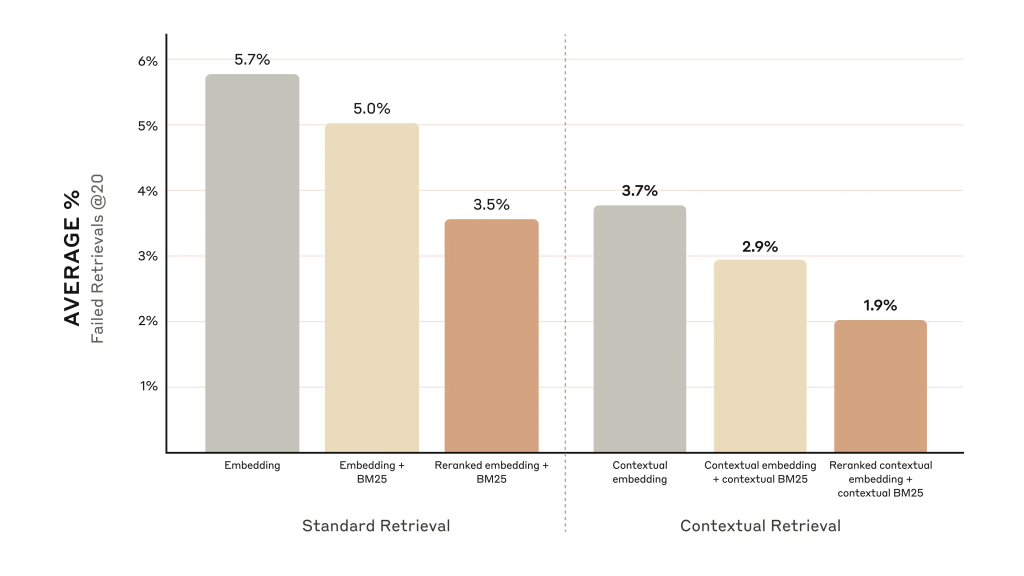
Comparison of failure rates with re-ranking.
Source: https://www.anthropic.com/news/contextual-retrieval
Example Implementation of Contextual Retrieval
Prompt Design Example
<document>
{{Content of the entire document}}
</document>
Here are the chunks to be placed within the whole document.
<chunk>
{{Content of the chunk}}
</chunk>
Please describe a concise context to position this chunk within the whole document to improve its searchability. Provide only a concise context, nothing else.
This prompt instructs the LLM to analyze the content of both the entire document and the chunk, generating context that explains which part of the document the chunk refers to.
For example, if the entire document is a company’s annual performance report and the chunk is “Revenue for Q2 increased by 10% compared to the same period last year,” the LLM would generate context like, “This chunk refers to the section of the company’s annual performance report about Q2.”
Example Implementation of Contextual Retrieval
Below is a simplified example of Contextual Retrieval implementation using Python and LangChain. For more details, please refer to the example published by Anthropic.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# Set OpenAI API key
import os
os.environ[“OPENAI_API_KEY”] = “YOUR_OPENAI_API_KEY”
# Initialize the embedding model and LLM
embeddings = OpenAIEmbeddings()
llm = OpenAI(temperature=0)
# Load the document and split into chunks
with open(“document.txt”, “r”) as f:
document = f.read()
chunks = document.split(“\n\n”) # Split by empty lines
# Generate contextual information for each chunk
contextualized_chunks = []
for chunk in chunks:
context = llm(f”””
<document>
{{Content of the entire document}}
</document>
Here is the chunk to be placed within the whole document.
<chunk>
{{Content of the chunk}}
</chunk>
Please describe a concise context for positioning this chunk within the whole document to improve its searchability. Only provide the concise context.
“””)
contextualized_chunks.append(f”{context} {chunk}”)
# Save the chunks with contextual information into a vector database
db = Chroma.from_texts(contextualized_chunks, embeddings)
# Create a RetrievalQA chain
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=llm, chain_type=”stuff”, retriever=retriever)
# Input a query and retrieve the answer
query = “What were the company’s Q2 earnings?”
answer = qa.run(query)
# Output the answer
print(answer)
Code Explanation
- Necessary libraries are imported.
- The OpenAI API key is set.
- The embedding model and LLM are initialized.
- The document is loaded and split into chunks.
- Contextual information is generated for each chunk.
- The chunks with contextual information are saved into a vector database.
- A RetrievalQA chain is created.
- A query is inputted, and the corresponding answer is retrieved.
- The answer is output.
Applications and Future Outlook of Contextual Retrieval
Contextual Retrieval is an effective method for solving issues in traditional RAG, but it also presents some challenges:
- Computation Cost: Since LLMs are used to generate contextual information, the computation cost may be higher compared to traditional RAG.
- Latency: The additional processing required to generate contextual information may lead to slower response times.
- Prompt Engineering: The quality of the contextual information generated by LLMs heavily depends on the design of the prompt. Effective prompt design is essential for generating appropriate contextual information.
Despite being a relatively new technology, Contextual Retrieval is already gaining attention from many companies and research institutions. For example, Google is considering incorporating Contextual Retrieval into its search engine ranking algorithms, and Microsoft is integrating this technology into the Bing search engine.
In the future, Contextual Retrieval is expected to be applied in various fields, including AI chatbots, question-answering systems, and machine translation. Moreover, as LLMs evolve, the accuracy of Contextual Retrieval will continue to improve with enhanced contextual understanding.

Article Author: Tomohide Kakeya
Representative Director of Scuti Inc.
After working in firmware development for digital SLR cameras and the design, implementation, and management of advertising systems, Tomohide Kakeya moved to Vietnam in 2012.
In 2015, he founded Scootie Inc. and has since been developing offshore business operations in Vietnam.
Recently, he has been focusing on system integration with ChatGPT and product development using generative AI. Additionally, as a personal hobby, he develops applications using OpenAI API and Dify.