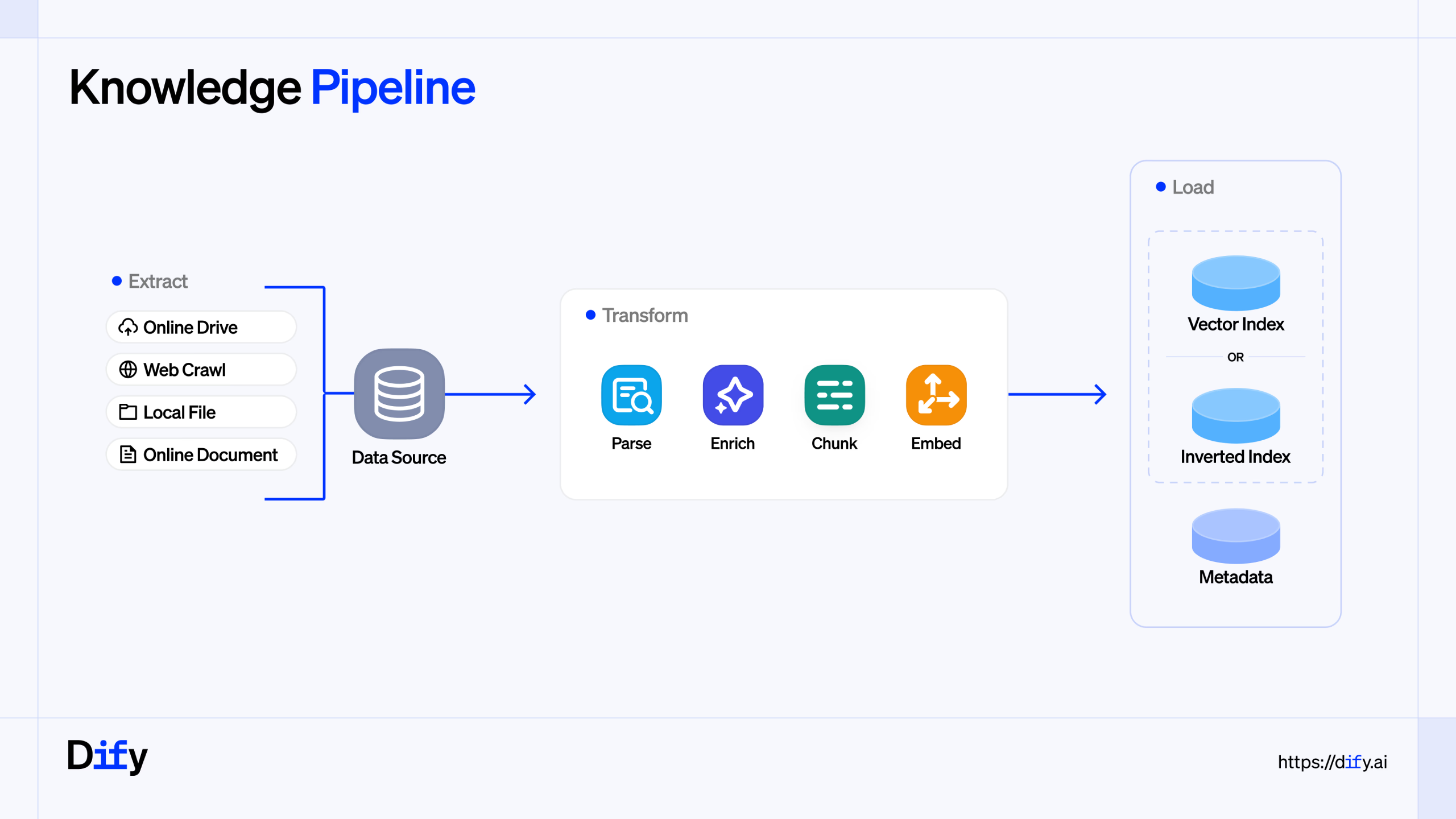
In today’s data-driven world, the ability to transform messy, unstructured enterprise data into valuable, actionable insights is a game-changer. But let’s face it, the process is often a headache. Critical information is scattered across PDFs, PowerPoints, spreadsheets, and various other formats, making it a challenge to create a unified, reliable source of context for Large Language Models (LLMs).
This is where Dify’s Knowledge Pipeline comes in, offering a visual, adaptable, and scalable solution to streamline your data processing workflow.
What is the Knowledge Pipeline?
The Knowledge Pipeline is a feature within the Dify platform that allows you to create a visual workflow for processing your data. Think of it as a canvas where you can drag, drop, and connect different “nodes,” each representing a specific step in the data processing journey. This visual approach takes the guesswork out of the traditional “black box” method of data processing, giving you full control and observability over the entire process.
The primary goal of the Knowledge Pipeline is to convert your unstructured enterprise data into high-quality context that can be used by LLMs. This is a crucial step in building powerful and accurate Retrieval-Augmented Generation (RAG) applications.
Key Features That Make a Difference
The Knowledge Pipeline is packed with features designed to simplify and enhance your data processing efforts:
-
Visual and Orchestrated Workflow: The intuitive canvas experience allows you to visually design your data processing pipeline, making it easy to understand and manage the entire workflow.
-
Enterprise-Grade Data Source Integrations: Connect to a wide range of data sources, including local files, cloud storage (like Google Drive and AWS S3), and online documentation platforms (like Notion and Confluence).
-
Pluggable Data Processing Pipeline: The pipeline is divided into distinct stages—Extract, Transform, and Load—allowing you to customize each step with different plugins to suit your specific needs.
-
Multiple Chunking Strategies: Choose from various chunking strategies, including “General Mode” for large batches of documents, “Parent-Child Mode” for long, technical documents, and “Q&A Mode” for extracting structured question-answer pairs.
-
Image Extraction and Retrieval: The pipeline can extract and process images from your documents, enabling you to build multimodal search and retrieval applications.
-
Observable Debugging: Test and debug your pipeline step-by-step, inspecting the inputs and outputs at each node to quickly identify and resolve any issues.
-
Built-in Templates: Get started quickly with a variety of pre-built templates for common use cases, such as processing long documents, extracting data from tables, and enriching content with LLMs.
Sample Usage
Here is a step-by-step guide on how to use the Knowledge Pipeline to process a .docx document file and ingest it into a knowledge base.
Step 1: Start from a Template
Instead of creating a blank pipeline, we’ll start with a pre-designed template to streamline the work.
-
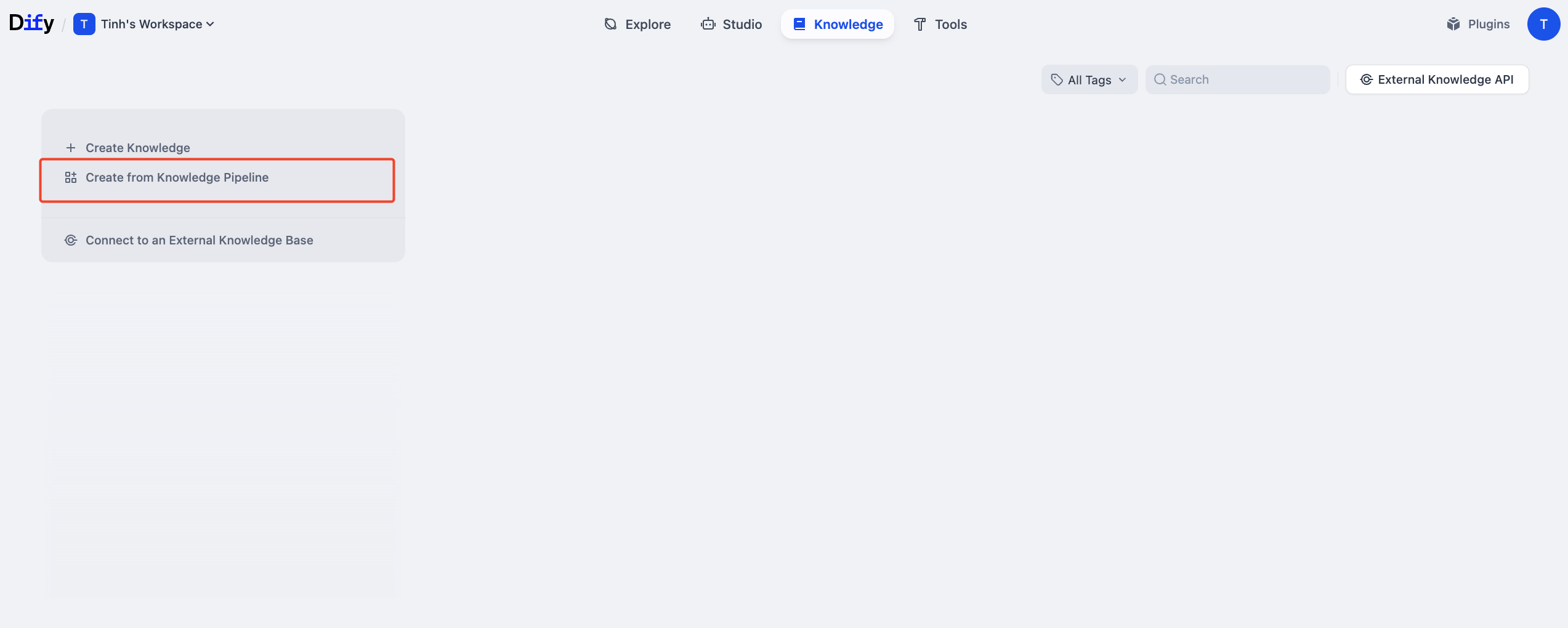
From the main Knowledge screen, select “Create from Knowledge Pipeline”.
-
A list of templates will appear. Choose the “Convert to Markdown” template. This template is ideal for processing Office files like DOCX by converting them to Markdown format before chunking, which helps improve the quality of information processing.

Step 2: Review the Pre-built Pipeline
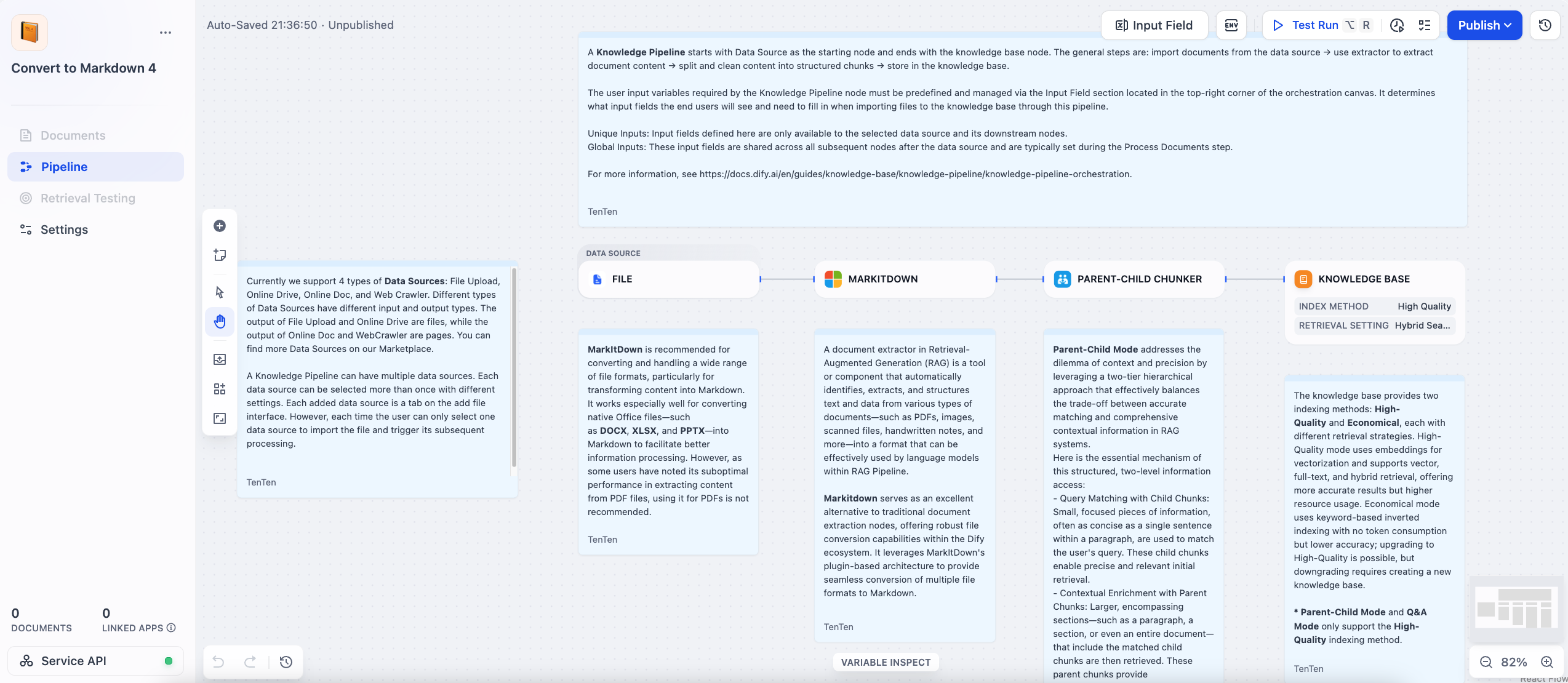
After selecting the template, you’ll be taken to a canvas with a pre-configured pipeline. This pipeline consists of several connected nodes:
-
FILE: The data source node where you will upload your file.
-
MARKDOWN: This node converts the content from the DOCX file into Markdown format.
-
PARENT-CHILD CHUNKER: This node splits the text using the “Parent-Child” chunking strategy, which helps retain the context of larger sections while ensuring precision when retrieving smaller chunks.
-
KNOWLEDGE BASE: The final node where the processed data is stored.
Step 3: Test Run and Fine-tune the Pipeline
Before publishing, you should run a test to ensure everything works as expected.
-
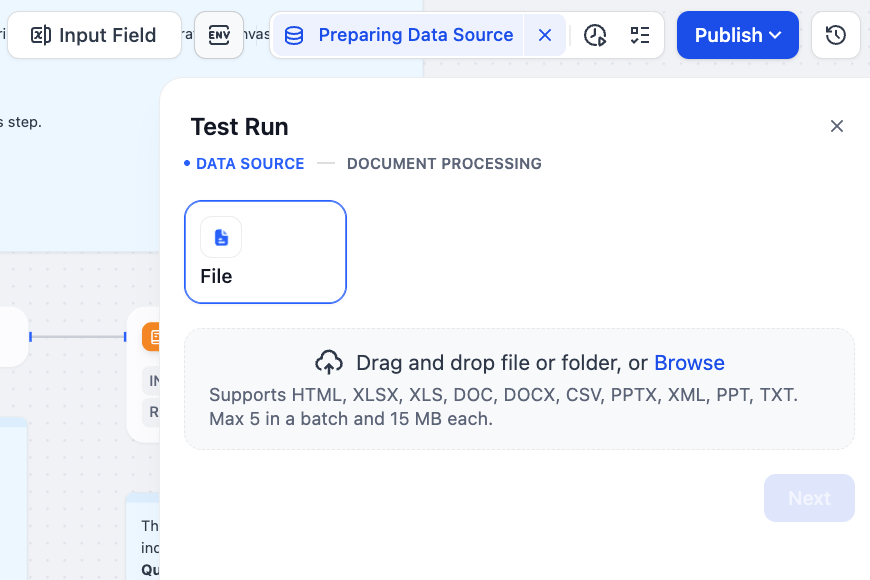
Click the “Test Run” button in the top-right corner.
-
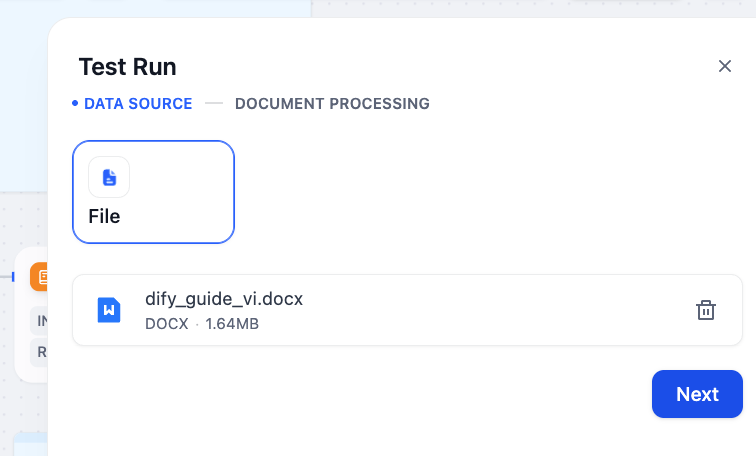
In the “Test Run” window, under the DATA SOURCE step, upload your document (e.g., dify_guide_vi.docx).
-
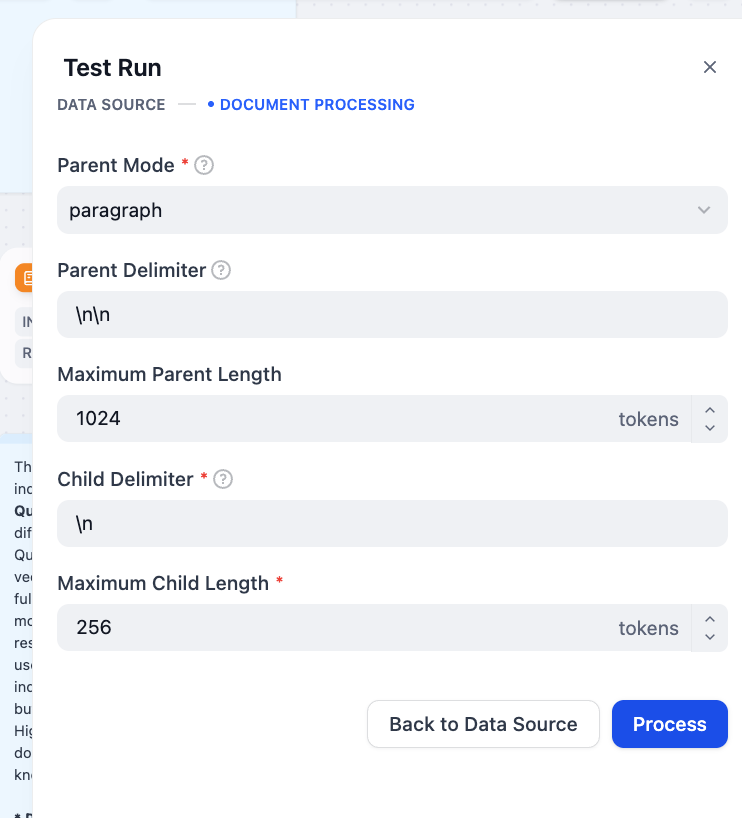
Click “Next” to proceed to the DOCUMENT PROCESSING step. Here, you can adjust the chunking parameters, such as the maximum length for parent and child chunks.
-
Click “Process” and view the output in the RESULT tab. You will see how your document has been divided into smaller chunks.
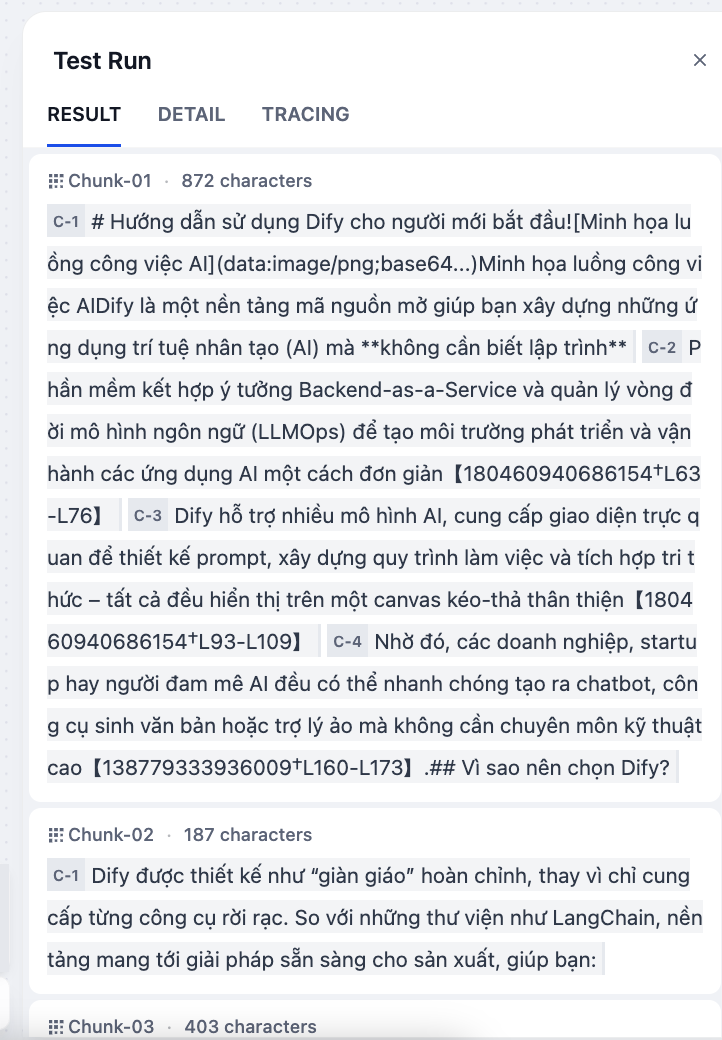
Step 4: Publish the Pipeline
Once you are satisfied with the test run results, it’s time to publish the pipeline for official use.
-
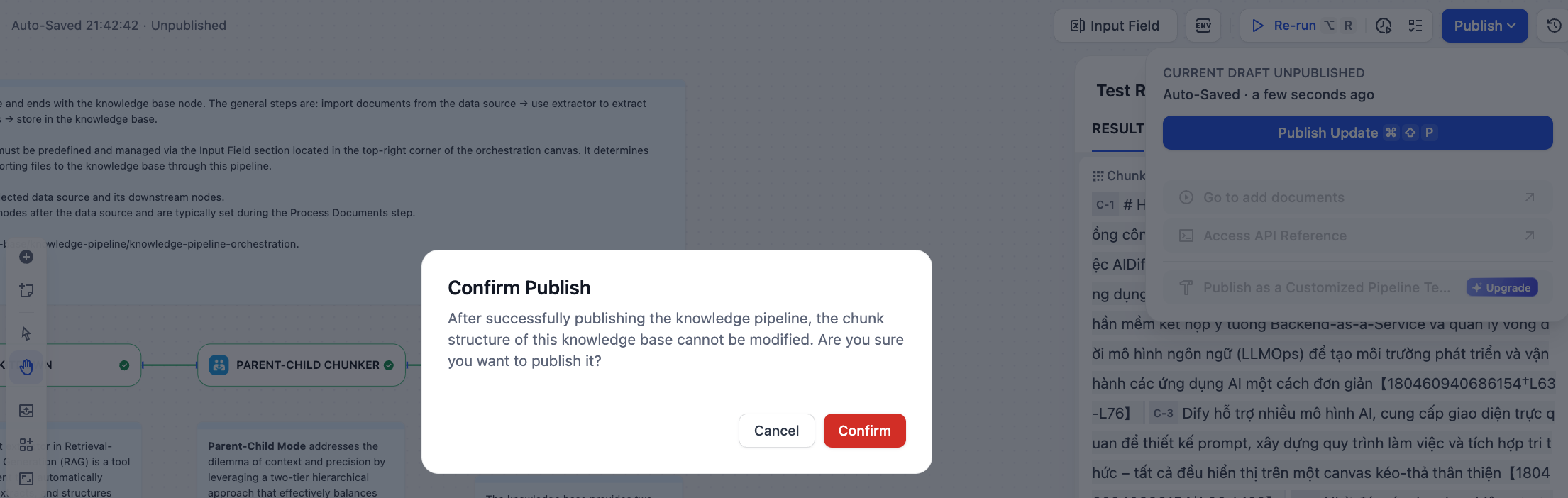
Click the blue “Publish” button in the top-right corner.
-
A confirmation dialog will appear, noting that the knowledge base’s structure cannot be modified after publishing. Click “Confirm” to finish.
Step 5: Add Documents and Use the Knowledge Base
Now your pipeline is live and ready to process files.
-
In your knowledge base, navigate to the “Documents” tab.
-
Click “Add file” and upload the dify_guide_vi.docx file (or any other document).
-
The pipeline will automatically process the file. Once completed, you will see your file listed with an “Available” status.

Your knowledge base is now ready to be linked to your AI applications, providing accurate context directly from your documents.
References:
https://dify.ai/blog/introducing-knowledge-pipeline
https://docs.dify.ai/en/guides/knowledge-base/knowledge-pipeline/readme