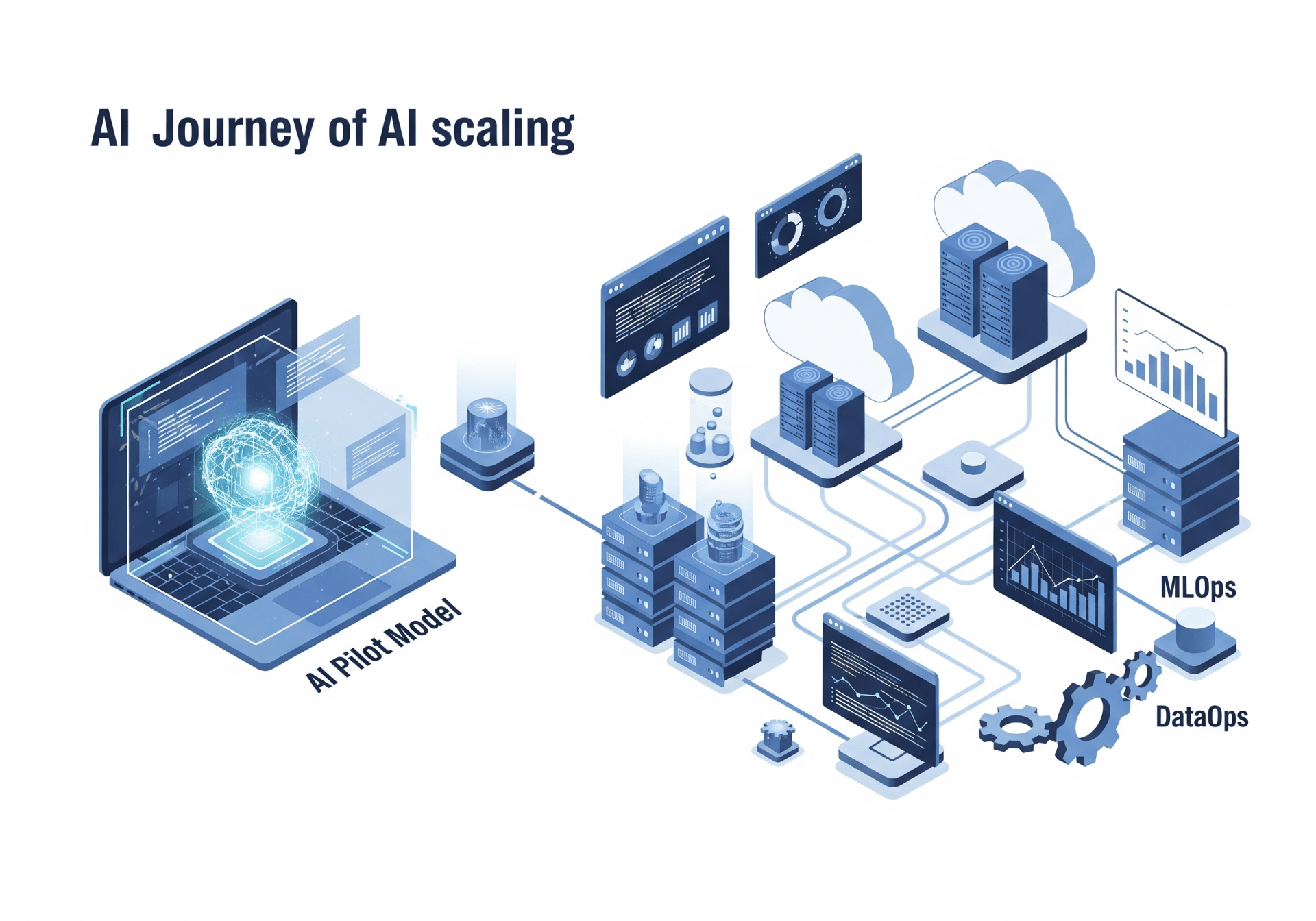
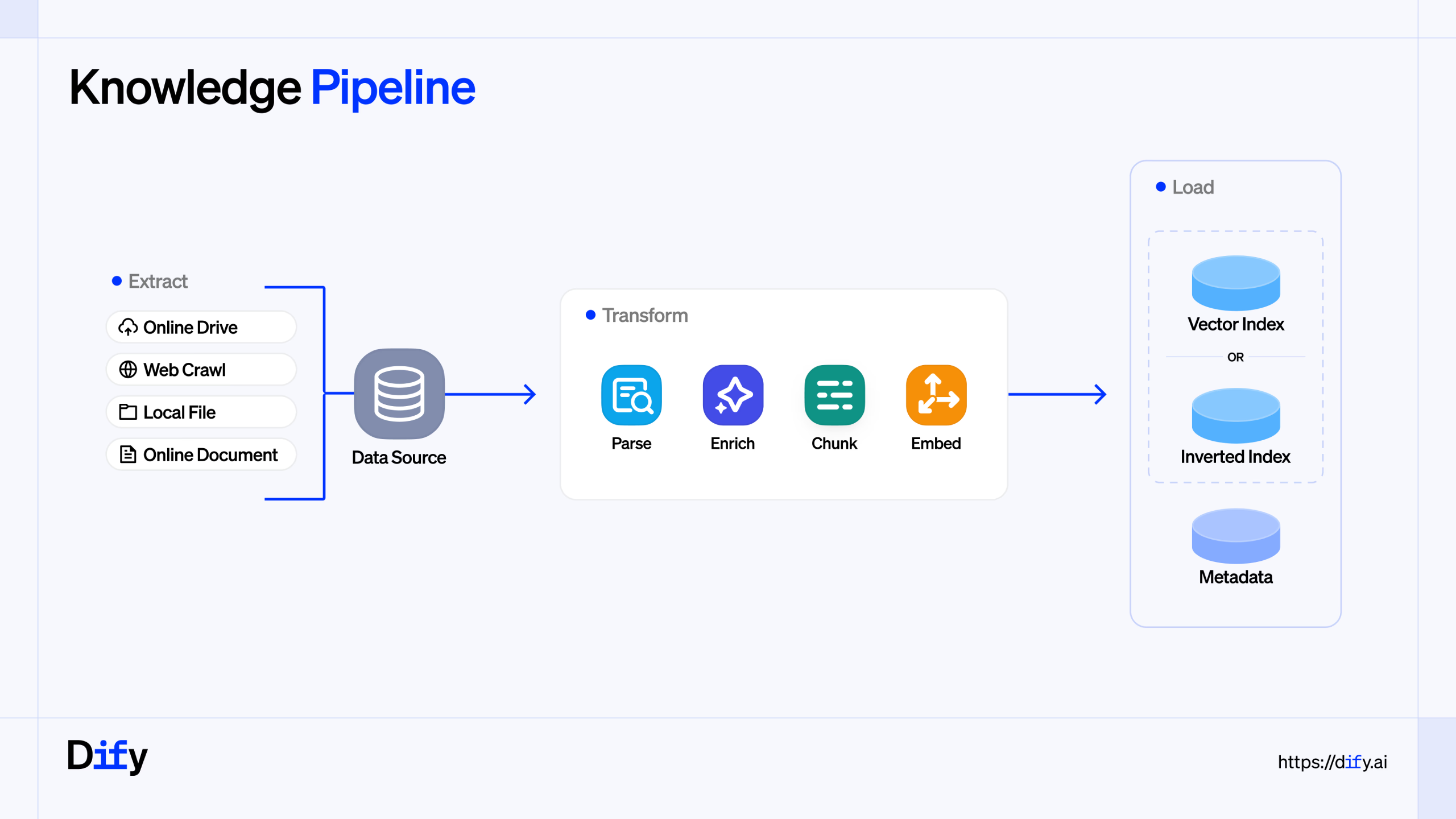
Many organizations have already succeeded in launching generative AI pilots. The real challenge begins afterward: how to turn a successful proof-of-concept into a stable...
Google Stitch: Creating UI Mockups with AI A practical walkthrough and evaluation of Google Stitch for UI mockup creation 1. Main Features Summary 2....
AI tools for developers are becoming increasingly common, but one major issue I often encounter is that AI usually lives outside the IDE.This breaks...
Grounding Gemini with Your Data: File Search Tool The true potential of Large Language Models (LLMs) is unlocked when they can interact with specific,...
In today’s data-driven world, the ability to transform messy, unstructured enterprise data into valuable, actionable insights is a game-changer. But let’s face it, the...
1. Introduction Recently, Anthropic released an incredible new feature for its product Claude: subagents — secondary agents with specific tasks for different purposes within...
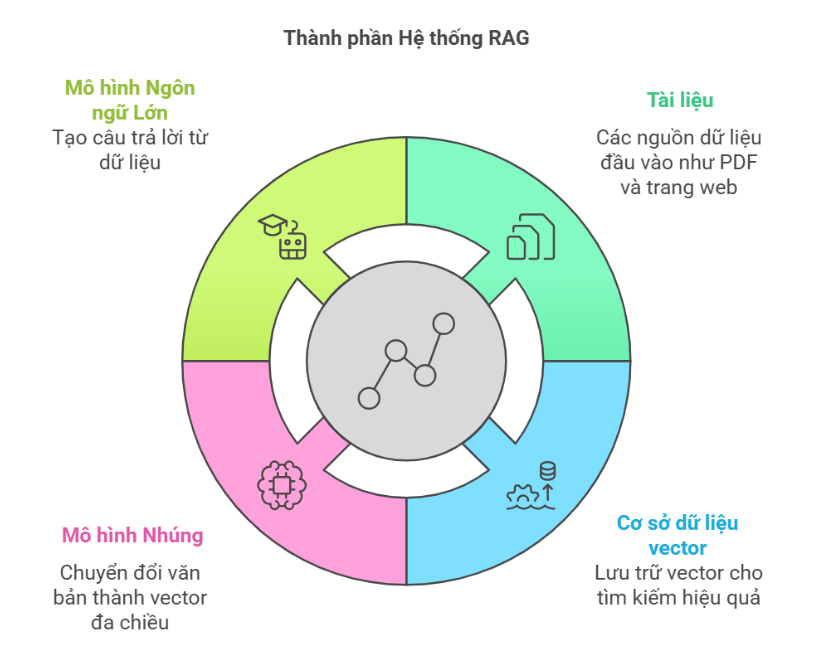
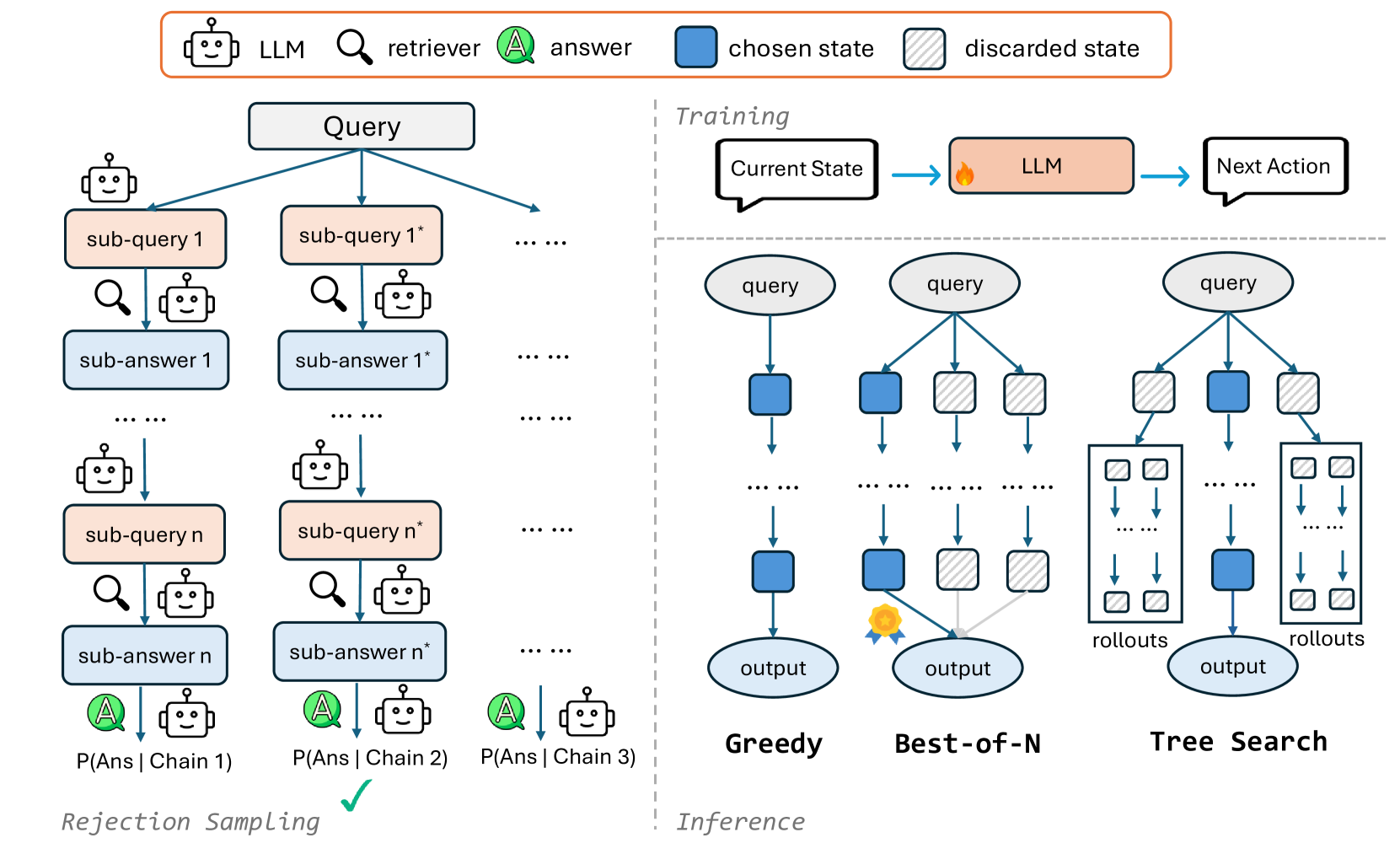
Large Language Models (LLMs) have demonstrated powerful content generation capabilities, but they often struggle with accessing the latest information, leading to hallucinations. Retrieval-Augmented Generation...