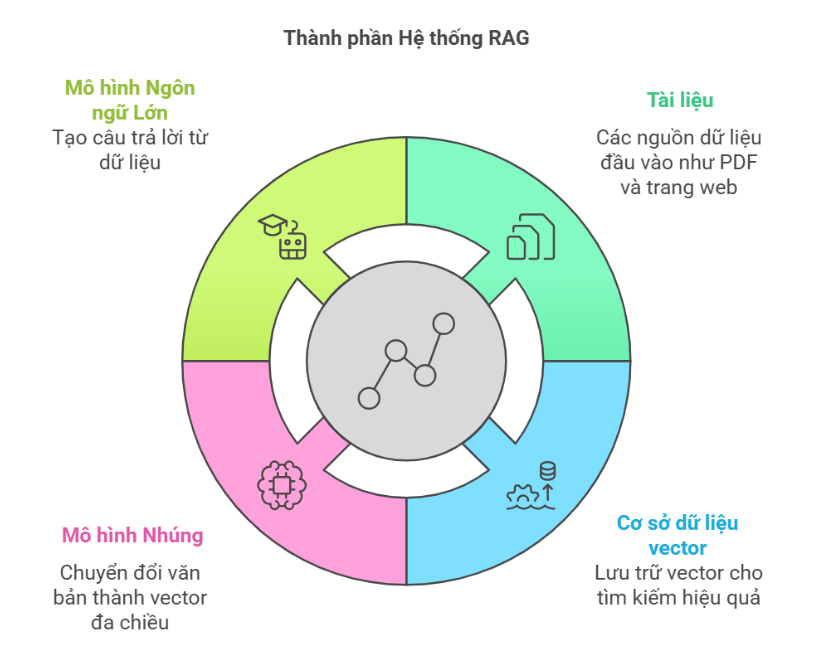
by Phan Thanh Giảng September 28, 2025 10 Hạn Chế Của Hệ Thống RAG Chatbot: Bạn Cần Biết Trước Khi Ứng Dụng Trong vài năm trở lại đây, RAG (Retrieval-Augmented Generation) nổi lên như một giải pháp “cứu cánh” cho các hệ thống chatbot. Nếu chatbot...
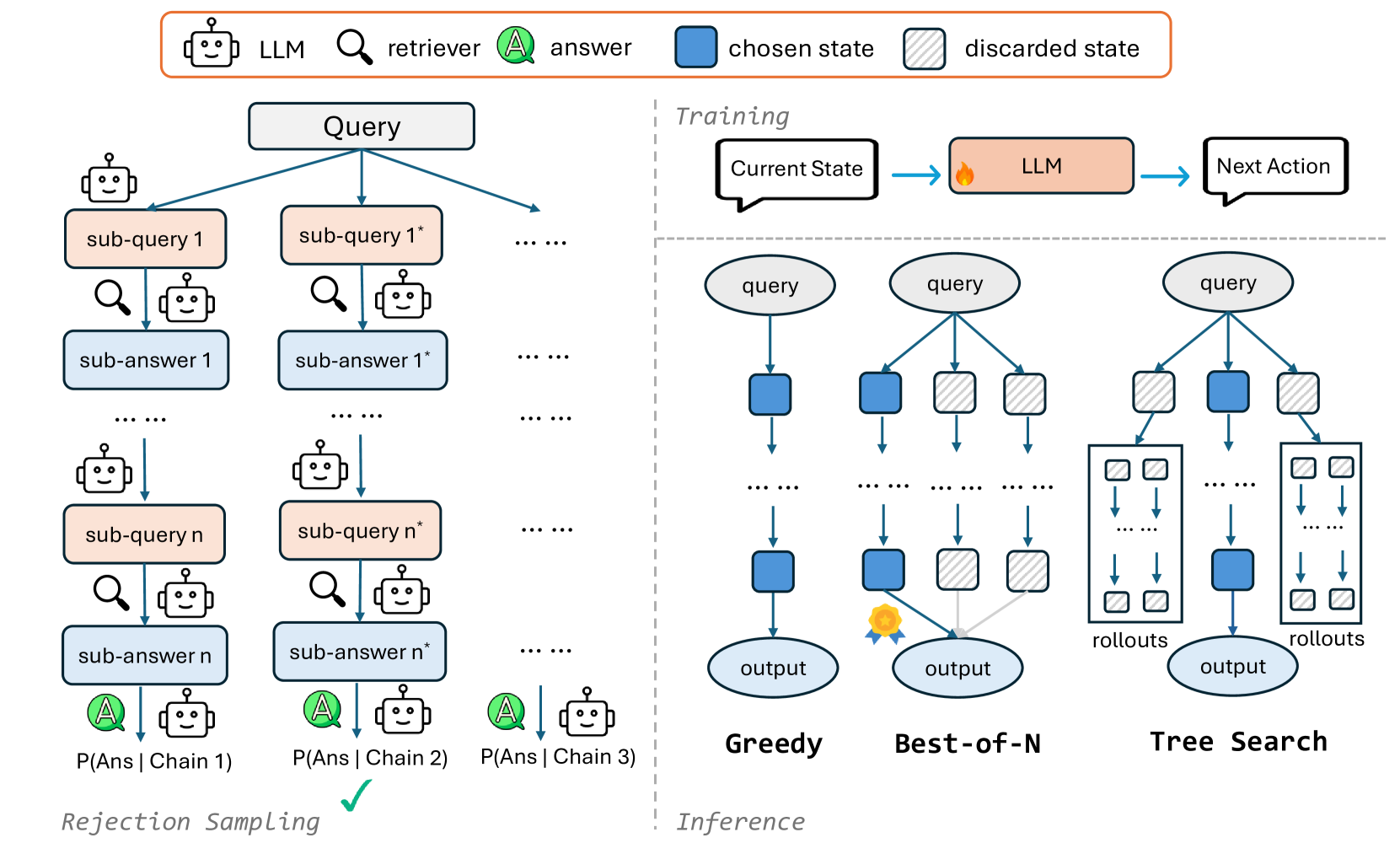
by Tran Dinh Trung February 16, 2025 CoRAG: Revolutionizing RAG Systems with Intelligent Retrieval Chains Large Language Models (LLMs) have demonstrated powerful content generation capabilities, but they often struggle with accessing the latest information, leading to hallucinations. Retrieval-Augmented Generation...