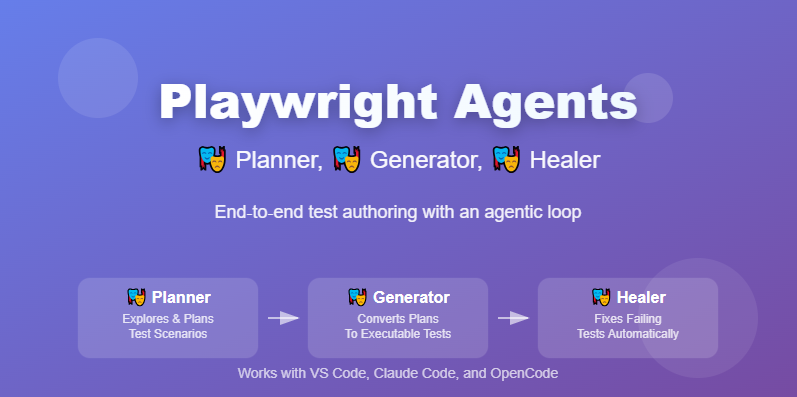
Giới Thiệu Trong thời đại AI đang phát triển mạnh mẽ, việc xây dựng các AI agent thông minh và hiệu quả đã trở...
We make services people love by the power of Gen AI.