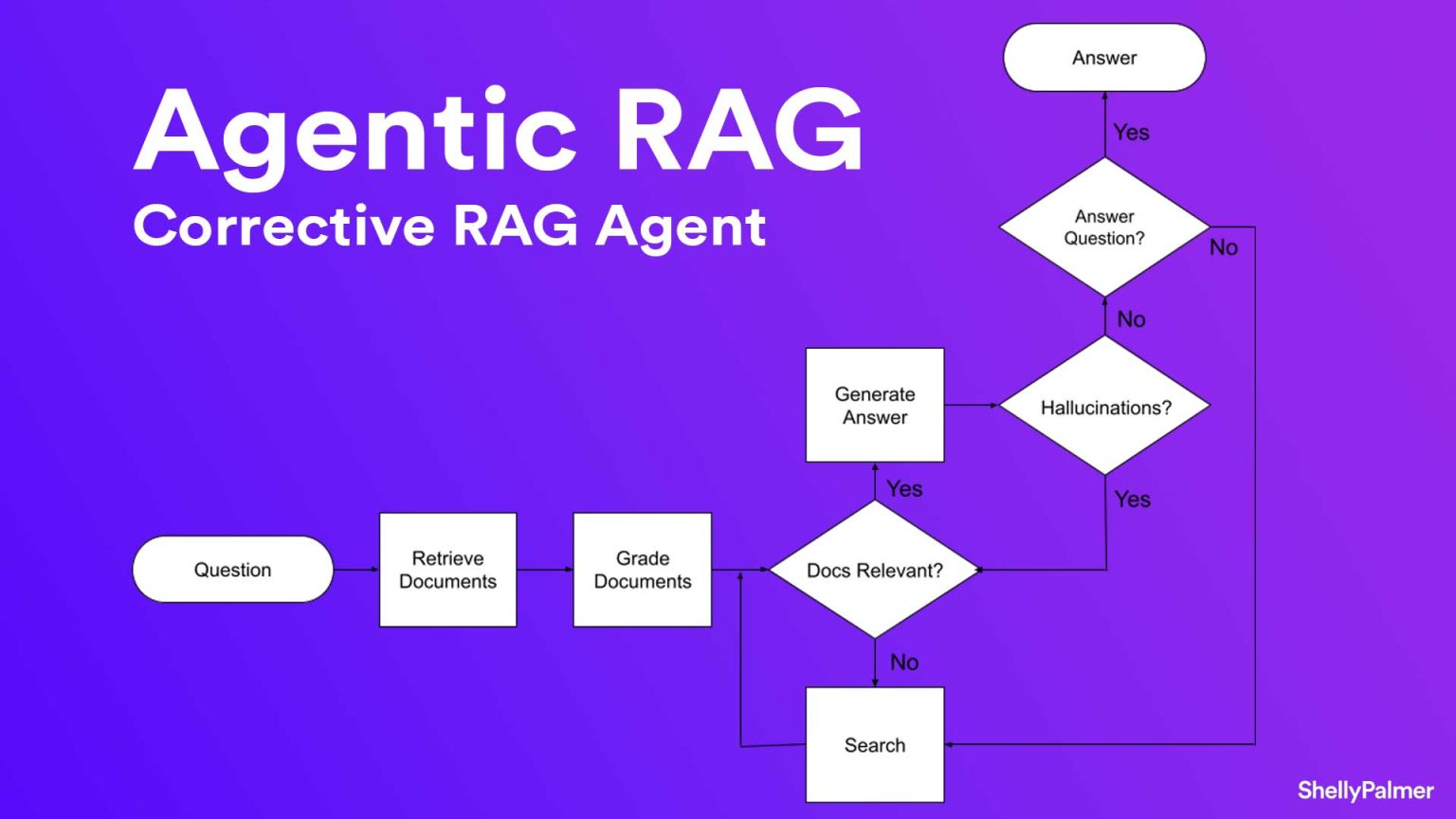
by Akai Taishi February 14, 2025 Agentic RAG: Giải pháp thông minh cho truy xuất dữ liệu Agentic RAG là giải pháp truy xuất dữ liệu thông minh, kết hợp AI Agent để vượt qua hạn chế của RAG truyền thống,...