

Xin chào, tôi là Kakeya, đại diện của công ty Scuti.
Công ty chúng tôi chuyên cung cấp các dịch vụ phát triển offshore tại Việt Nam, phát triển kiểu lab và tư vấn AI tạo sinh, với thế mạnh là công nghệ AI tạo sinh. Gần đây, chúng tôi rất may mắn khi nhận được nhiều yêu cầu phát triển hệ thống tích hợp với AI tạo sinh.
Công nghệ AI tạo sinh không ngừng phát triển! Tốc độ nhanh đến mức khó mà theo kịp!
Vào ngày 23 tháng 7 năm 2024 (giờ Mỹ), Meta đã công bố mô hình ngôn ngữ mới nhất của họ, Llama 3.1, thu hút sự chú ý rất lớn. Mặc dù chỉ là bản nâng cấp nhỏ từ Llama 3 lên Llama 3.1, nhưng Llama 3.1 với hiệu năng vượt trội và quyết định mở mã nguồn đã tạo nên những làn sóng mới trong thế giới AI tạo sinh.
Trong bài viết này, chúng tôi sẽ giải thích đầy đủ những điểm nổi bật của Llama 3.1 và khám phá tiềm năng của nó.
Kiến thức cơ bản về Llama 3.1

Llama 3.1 là gì?
Llama 3.1 là một AI có khả năng thực hiện nhiều tác vụ khác nhau như tạo văn bản tự nhiên giống con người, dịch thuật, trả lời câu hỏi và tạo cuộc hội thoại. Thông qua việc học từ một lượng dữ liệu khổng lồ, nó đạt được mức độ chính xác và tự nhiên mà các mô hình AI thông thường không thể làm được.
Độ dài ngữ cảnh mà nó có thể xử lý đã được mở rộng đáng kể, hỗ trợ đến 128.000 token, một con số đáng kinh ngạc. Đây là độ dài gấp 16 lần so với phiên bản trước đó là 8.000 token, cho phép nó hiểu và tạo ra các văn bản phức tạp và dài hơn.
Hơn nữa, khả năng hỗ trợ đa ngôn ngữ đã được cải thiện, với việc Llama 3.1 hiện hỗ trợ tổng cộng 8 ngôn ngữ, bao gồm tiếng Anh, tiếng Đức, tiếng Pháp, tiếng Ý, tiếng Bồ Đào Nha, tiếng Hindi, tiếng Tây Ban Nha và tiếng Thái. Mặc dù tiếng Nhật không có trong danh sách này, nhưng theo quan sát của tôi, Llama 3.1 xử lý văn bản tiếng Nhật một cách mượt mà, không có vấn đề đáng kể nào và đạt độ chính xác cao.
Ngoài ra, Llama 3.1 được phát hành theo giấy phép mã nguồn mở, đánh dấu một bước ngoặt lớn trong lịch sử phát triển AI. Điều này cho phép bất kỳ ai cũng có thể sử dụng, sửa đổi và phân phối lại mô hình một cách tự do, tạo điều kiện cho các nhà phát triển trên toàn thế giới đóng góp vào nghiên cứu và phát triển Llama 3.1. Động thái này được kỳ vọng sẽ thúc đẩy nhanh chóng sự tiến hóa của công nghệ AI.
Dòng mô hình Llama 3.1
Llama 3.1 có sẵn với ba kích thước mô hình: 8B, 70B và 405B, cho phép người dùng lựa chọn mô hình phù hợp nhất với mục đích sử dụng cụ thể.
- Mô hình 8B: Được biết đến với tính nhẹ nhàng và xử lý nhanh, lý tưởng cho các môi trường có tài nguyên tính toán hạn chế như thiết bị di động và hệ thống nhúng.
- Mô hình 70B: Cung cấp sự cân bằng giữa hiệu năng và hiệu quả, phù hợp với nhiều tác vụ xử lý ngôn ngữ tự nhiên phổ biến.
- Mô hình 405B: Là mô hình lớn nhất và mạnh mẽ nhất, được tối ưu hóa cho các tác vụ yêu cầu khả năng hiểu ngôn ngữ và lập luận nâng cao.
Mỗi kích thước mô hình đều có hai biến thể: Mô hình cơ bản, là mô hình ngôn ngữ đa dụng, và Mô hình chỉ dẫn, được tinh chỉnh để phản hồi chính xác hơn theo hướng dẫn của con người.
Danh sách các mô hình có sẵn:
- Meta-Llama-3.1-8B
- Meta-Llama-3.1-8B-Instruct
- Meta-Llama-3.1-70B
- Meta-Llama-3.1-70B-Instruct
- Meta-Llama-3.1-405B
- Meta-Llama-3.1-405B-Instruct
Đánh giá hiệu năng của Llama 3.1
Kết quả Benchmark – Điểm số ấn tượng vượt qua các mô hình trước đó
Hiệu năng của Llama 3.1 đã được đánh giá trên nhiều tiêu chuẩn benchmark và kết quả rất đáng kinh ngạc.
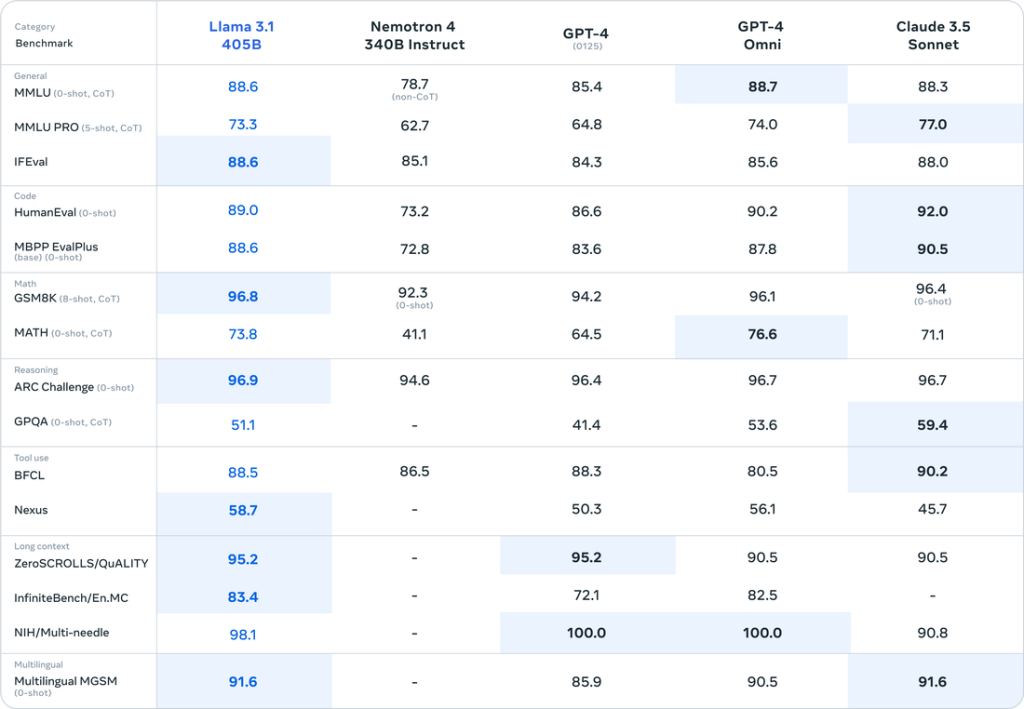
Nguồn: https://ai.meta.com/blog/meta-llama-3-1/
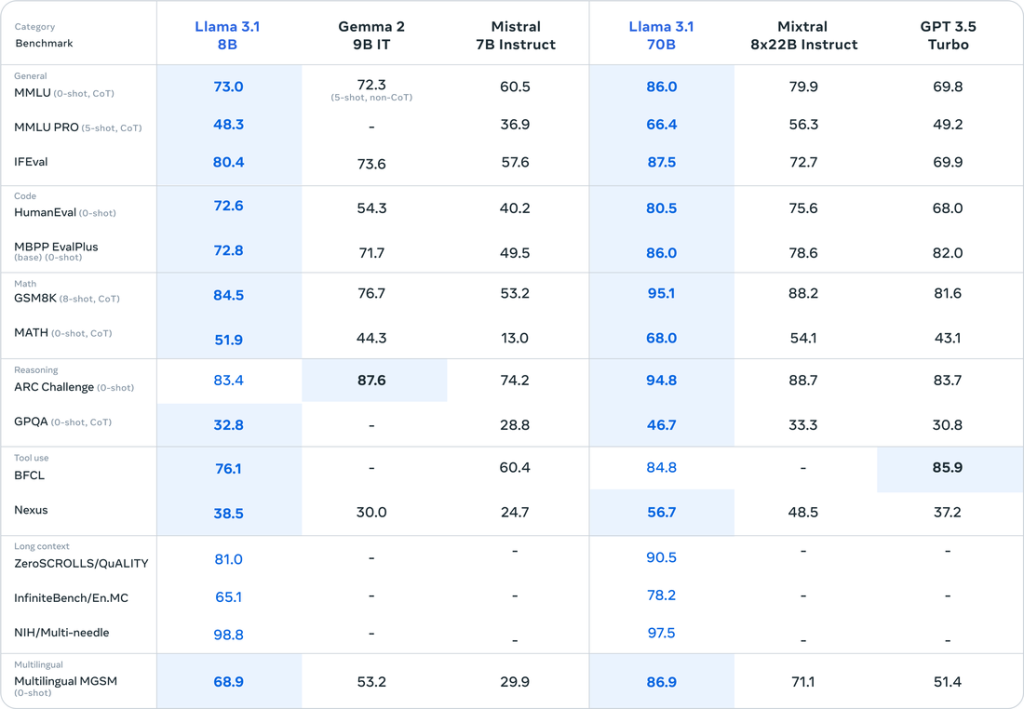
Nguồn: https://ai.meta.com/blog/meta-llama-3-1/
Đặc biệt, mô hình 405B cho thấy hiệu năng tổng thể vượt trội hơn GPT-4o và gần tương đương với Claude 3.5 Sonnet.
MMLU (Massive Multitask Language Understanding):
Trên tiêu chuẩn đánh giá này, bao gồm 57 nhiệm vụ đa dạng kiểm tra khả năng hiểu ngôn ngữ, mô hình Llama 3.1 405B đã đạt được số điểm ấn tượng 87.3%. Điểm số này gần đạt mức chuẩn của con người là 90% và tương đương với GPT-4o, thể hiện khả năng hiểu ngôn ngữ vượt trội của Llama 3.1.
HumanEval:
Tiêu chuẩn này đánh giá khả năng tạo mã Python dựa trên hướng dẫn được đưa ra. Mô hình Llama 3.1 405B đạt số điểm cao 89.0%, cho thấy khả năng hiểu các hướng dẫn phức tạp và tạo mã chính xác. Hiệu suất này ngang bằng với GPT-4o và chỉ hơi thấp hơn so với Claude 3.5 Sonnet mới được Anthropic phát hành.
GSM-8K:
Tiêu chuẩn này đo lường khả năng giải quyết các bài toán đố toán học cấp tiểu học. Mô hình Llama 3.1 405B đạt được số điểm ấn tượng 96.8%, thể hiện khả năng lập luận logic và giải toán tiên tiến của nó.
Những kết quả đánh giá này chứng minh rằng Llama 3.1 là một mô hình AI có hiệu suất rất cao trong nhiều lĩnh vực khác nhau.
Giấy phép và sử dụng thương mại của Llama 3.1
Llama 3.1 được cung cấp theo giấy phép thương mại đặc biệt có tên là “Llama 3.1 Community License,” linh hoạt hơn cho mục đích thương mại so với các phiên bản trước. Vui lòng tham khảo tài liệu giấy phép gốc để biết thêm chi tiết.
Các hành động được phép:
- Phân phối lại mô hình
- Tinh chỉnh mô hình
- Tạo các tác phẩm phái sinh
- Sử dụng đầu ra của mô hình để cải thiện các LLM khác (bao gồm tạo và trích xuất dữ liệu tổng hợp cho các mô hình khác)
Điều kiện:
- Nếu Llama 3.1 được sử dụng trong các sản phẩm hoặc dịch vụ có hơn 700 triệu người dùng hoạt động hàng tháng, cần phải có giấy phép riêng từ Meta.
- Tên của các mô hình phái sinh phải bắt đầu bằng “Llama.”
- Các tác phẩm hoặc dịch vụ phái sinh phải bao gồm tuyên bố rõ ràng: “Built with Llama.”
Những điều khoản này khiến Llama 3.1 trở thành một mô hình ngôn ngữ đa phương tiện mạnh mẽ, linh hoạt, tương đương với GPT-4o. Tuy nhiên, bạn có thể tự hỏi, “Nó rất tuyệt, nhưng làm thế nào để sử dụng nó hiệu quả?”
Cách sử dụng hiệu quả nhất của Llama 3.1 là xây dựng các hệ thống RAG (Retrieval-Augmented Generation) trong môi trường on-premise. Đối với các tổ chức bị hạn chế bởi các chính sách bảo mật không thể sử dụng dịch vụ RAG trên đám mây, Llama 3.1 có thể được triển khai trên các máy chủ nội bộ để triển khai các giải pháp RAG an toàn và hiệu quả.
Công ty chúng tôi cung cấp một dịch vụ RAG (Retrieval-Augmented Generation) dựa trên SaaS có tên là “SecureGAI,” và chúng tôi cũng có chuyên môn cũng như kinh nghiệm trong việc triển khai dịch vụ này trong các môi trường on-premise. Nếu bạn quan tâm đến việc xây dựng RAG trong môi trường on-premise, xin đừng ngần ngại liên hệ với chúng tôi!
Công nghệ đứng sau Llama 3.1
Kiến trúc Transformer – Cấu trúc đột phá cho phép xử lý ngôn ngữ nâng cao
Llama 3.1 được xây dựng dựa trên kiến trúc học sâu Transformer. Được các nhà nghiên cứu của Google giới thiệu vào năm 2017, kiến trúc Transformer đã cách mạng hóa lĩnh vực xử lý ngôn ngữ tự nhiên.
Các mô hình xử lý ngôn ngữ tự nhiên truyền thống gặp khó khăn trong việc xử lý văn bản dài và yêu cầu thời gian huấn luyện đáng kể. Tuy nhiên, kiến trúc Transformer khắc phục những thách thức này bằng cách sử dụng cơ chế Attention.
Cơ chế Attention tính toán mối liên hệ giữa từng từ trong một câu với các từ khác, cho phép Transformer hiểu ngữ cảnh của các văn bản dài một cách chính xác và đạt được khả năng xử lý ngôn ngữ chính xác cao.
Llama 3.1 tận dụng kiến trúc Transformer này và bổ sung các cải tiến độc quyền để đạt được hiệu suất và hiệu quả vượt trội so với các mô hình trước đó.
Mô hình ngôn ngữ tự hồi quy – Dự đoán tương lai từ dữ liệu quá khứ
Llama 3.1 là một mô hình ngôn ngữ tự hồi quy, dự đoán dữ liệu tương lai dựa trên dữ liệu quá khứ.
Trong bối cảnh xử lý ngôn ngữ tự nhiên, điều này có nghĩa là dự đoán từ tiếp theo trong một chuỗi từ. Ví dụ, với cụm từ “Hôm nay trời đẹp,” mô hình ngôn ngữ tự hồi quy sẽ dự đoán từ “quá.”
Thông qua việc học từ một lượng lớn dữ liệu văn bản, Llama 3.1 đã đẩy khả năng dự đoán này đến giới hạn tối đa, cho phép nó tạo ra văn bản tự nhiên giống con người.
Huấn luyện trên dữ liệu lớn – Tích hợp kiến thức từ 15 nghìn tỷ token
Llama 3.1 đạt được hiệu suất đáng kinh ngạc nhờ vào việc huấn luyện trên một khối lượng dữ liệu khổng lồ. Cụ thể, mô hình này đã được huấn luyện trên hơn 15 nghìn tỷ token từ các nguồn như website, sách và mã lập trình.
Việc sử dụng dữ liệu quy mô lớn như vậy đóng vai trò rất quan trọng trong sự phát triển của công nghệ AI trong những năm gần đây. Không giống như học máy truyền thống, nơi các đặc trưng được thiết kế thủ công bởi con người, học sâu cho phép máy tính học các đặc trưng trực tiếp từ một lượng lớn dữ liệu.
Bằng cách tận dụng tối đa sức mạnh của học sâu, Llama 3.1 đã đạt được mức độ hiểu ngôn ngữ mà trước đây không thể tưởng tượng được với các mô hình ngôn ngữ truyền thống.
Cụ thể, quá trình tiền huấn luyện bao gồm khoảng 15 nghìn tỷ token dữ liệu từ các nguồn công khai, các tập dữ liệu chỉ dẫn công khai, và hơn 25 triệu ví dụ tổng hợp được tạo ra thông qua SFT (Supervised Fine-Tuning) và RLHF (Reinforcement Learning from Human Feedback).
Yêu cầu bộ nhớ cho Llama 3.1

Nguồn: https://huggingface.co/blog/llama31
Yêu cầu bộ nhớ để chạy Llama 3.1 phụ thuộc vào kích thước mô hình và độ chính xác được sử dụng. Mô hình càng lớn và độ chính xác càng cao thì yêu cầu bộ nhớ càng nhiều.
Ví dụ, khi chạy mô hình 405B với độ chính xác FP16, trọng số của mô hình yêu cầu khoảng 800GB bộ nhớ. Ngoài ra, bộ nhớ KV cache cần thiết để lưu trữ ngữ cảnh của mô hình có thể yêu cầu thêm vài trăm GB bộ nhớ, tùy thuộc vào độ dài ngữ cảnh. Do đó, để chạy mô hình 405B, cần có máy chủ GPU với dung lượng bộ nhớ lớn.
Trong khi đó, các mô hình nhỏ hơn như 8B và 70B có thể chạy trên các máy chủ GPU nhỏ hơn. Khi chạy mô hình 8B với độ chính xác FP16, trọng số mô hình yêu cầu khoảng 16GB và KV cache tối đa là 16GB, tổng cộng yêu cầu khoảng 32GB bộ nhớ. Đối với mô hình 70B, trọng số yêu cầu khoảng 140GB và KV cache tối đa là 140GB, tổng cộng yêu cầu khoảng 280GB bộ nhớ.
Tối ưu hóa bộ nhớ bằng lượng tử hóa – Hiệu suất cao với ít bộ nhớ hơn
Để giảm lượng bộ nhớ sử dụng, Llama 3.1 cũng cung cấp các mô hình được lượng tử hóa. Lượng tử hóa là kỹ thuật biểu diễn trọng số của mô hình bằng các kiểu dữ liệu với số bit ít hơn mà không làm giảm đáng kể độ chính xác. Điều này giúp giảm lượng bộ nhớ sử dụng và tăng tốc độ suy luận.
Llama 3.1 cung cấp các mô hình lượng tử hóa với độ chính xác FP16 (số thực 16 bit), FP8 (số thực 8 bit) và INT4 (số nguyên 4 bit). Các mô hình lượng tử hóa FP8 có thể giảm lượng bộ nhớ sử dụng khoảng một nửa so với mô hình FP16. Các mô hình lượng tử hóa INT4 thậm chí có thể giảm lượng bộ nhớ xuống còn khoảng một phần tư so với mô hình FP16.
Llama 3.1 như một hệ thống: Các công cụ để xây dựng hệ thống AI an toàn
Llama 3.1 không được thiết kế để hoạt động độc lập; để hoạt động an toàn và hiệu quả, cần áp dụng thêm các biện pháp bảo mật. Meta đã cung cấp một số công cụ và hướng dẫn được khuyến nghị sử dụng cùng với Llama 3.1.
Llama Guard 3 – Phát hiện nội dung không an toàn
Llama Guard 3 là một công cụ bảo mật phân tích các lệnh đầu vào và phản hồi được tạo ra nhằm phát hiện nội dung không an toàn hoặc không phù hợp.
Công cụ này hỗ trợ nhiều ngôn ngữ, cho phép phân tích văn bản được viết bằng các ngôn ngữ khác nhau.
Việc tích hợp Llama Guard 3 với Llama 3.1 giúp giảm nguy cơ lạm dụng mô hình, từ đó xây dựng các hệ thống AI an toàn hơn.
Prompt Guard – Ngăn chặn tấn công tiêm lệnh
Prompt Guard là một công cụ được thiết kế để phát hiện các cuộc tấn công tiêm lệnh (prompt injection), trong đó người dùng ác ý thao túng lệnh đầu vào để thay đổi hành vi của mô hình AI.
Công cụ này giúp đảm bảo an toàn cho mô hình AI bằng cách phát hiện những cuộc tấn công như vậy.
Code Shield – Phát hiện lỗ hổng trong mã được tạo
Code Shield là một công cụ kiểm tra tính an toàn của mã được tạo ra bởi các mô hình AI.
Mã do AI tạo ra có thể chứa lỗ hổng bảo mật, Code Shield hỗ trợ phát hiện và xử lý những lỗ hổng này, góp phần phát triển các ứng dụng AI an toàn.
Sử dụng Llama 3.1
Truy cập qua các dịch vụ đám mây
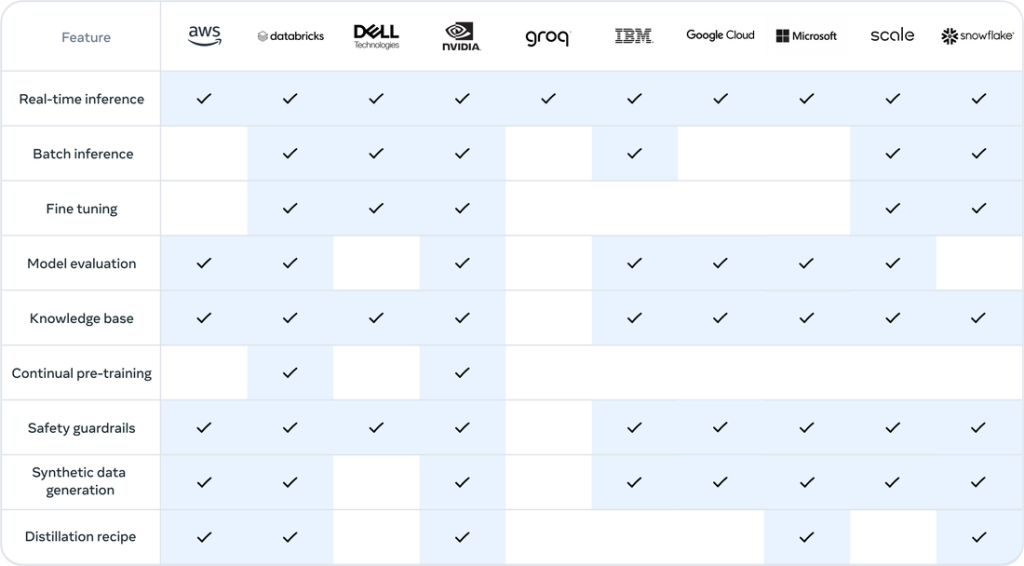
Nguồn: https://ai.meta.com/blog/meta-llama-3-1/
Llama 3.1 có thể được truy cập thông qua các nhà cung cấp dịch vụ đám mây lớn, cho phép nhà phát triển sử dụng các khả năng mạnh mẽ của nó mà không cần xây dựng cơ sở hạ tầng riêng.
- Amazon Web Services (AWS): Dễ dàng triển khai và sử dụng Llama 3.1 thông qua Amazon SageMaker JumpStart.
- Microsoft Azure: Chạy Llama 3.1 trên đám mây và xây dựng các ứng dụng AI có khả năng mở rộng thông qua Azure Machine Learning.
- Google Cloud Platform (GCP): Dễ dàng triển khai Llama 3.1 và phát triển các giải pháp AI tùy chỉnh thông qua Vertex AI.
Các nhà cung cấp dịch vụ đám mây này cung cấp tài nguyên tính toán, lưu trữ và bảo mật cần thiết để sử dụng Llama 3.1, giúp các nhà phát triển tập trung hoàn toàn vào việc phát triển AI.
Hugging Face Transformers
Hugging Face Transformers là một thư viện mã nguồn mở để làm việc với các mô hình xử lý ngôn ngữ tự nhiên. Llama 3.1 cũng được Hugging Face Transformers hỗ trợ, giúp dễ dàng tải và sử dụng mô hình. Transformers tương thích với các khung học sâu chính như PyTorch, TensorFlow và JAX, cho phép sử dụng trong nhiều môi trường phát triển khác nhau.
Dùng thử miễn phí Llama 3.1 405B trên HuggingChat
Bạn có thể dùng thử Llama 3.1 405B miễn phí trên HuggingChat. Mặc dù không hỗ trợ tạo hình ảnh và chỉ giới hạn trong việc tạo văn bản, việc trải nghiệm mô hình 405B miễn phí vẫn là một cơ hội rất đáng giá!
Trò chuyện nhanh với Llama 3.1 70B trên Groq
Groq cũng đã nhanh chóng hỗ trợ Llama 3.1! Hiện tại, chỉ có các mô hình 8B và 70B (chưa hỗ trợ 405B), nhưng bạn có thể tận hưởng khả năng của Llama 3.1 trong môi trường phản hồi siêu nhanh của Groq!