🤖 OpenAI AgentKit vs Dify
A Comprehensive Technical Comparison of Two Leading AI Agent Development Platforms
Last Updated: October 2025 | DevDay 2025 Analysis
Executive Summary: OpenAI AgentKit and Dify represent two distinct approaches to AI agent development. AgentKit, announced at OpenAI’s DevDay 2025, offers a comprehensive, proprietary toolkit designed to streamline agent creation within the OpenAI ecosystem. Dify, an open-source platform, provides extensive flexibility with multi-provider LLM support and full infrastructure control. This guide examines both platforms in depth to help you make an informed decision.
🚀 Platform Overview
OpenAI AgentKit
Launched October 2025 at DevDay, AgentKit is OpenAI’s complete toolkit for building production-ready AI agents with minimal friction.
- Proprietary platform by OpenAI
- Cloud-based deployment
- Deep OpenAI ecosystem integration
- Enterprise-grade security built-in
- Visual drag-and-drop builder
- Rapid prototyping (agents in hours, not months)
Dify
Open-source LLMOps platform with 180,000+ developers, supporting comprehensive AI application development with full control.
- 100% open-source platform
- Self-hosted or cloud deployment
- Multi-provider LLM support (GPT, Claude, Llama, etc.)
- Complete data sovereignty
- Extensive RAG capabilities
- Active community of 180,000+ developers
🎯 OpenAI AgentKit – Core Features
🎨 Agent Builder
A visual canvas for creating and versioning multi-agent workflows using drag-and-drop functionality. Developers can design complex agent interactions without extensive coding.
- Visual workflow designer
- Version control for agent workflows
- Multi-agent orchestration
- Real-time collaboration
- 70% faster iteration cycles reported
💬 ChatKit
Embeddable, customizable chat interfaces that can be integrated directly into your applications with your own branding and workflows.
- White-label chat interfaces
- Custom branding options
- Pre-built UI components
- Seamless product integration
- Mobile-responsive design
🔌 Connector Registry
Centralized admin dashboard for managing secure connections between agents and both internal tools and third-party systems.
- Pre-built connectors: Dropbox, Google Drive, SharePoint, Teams
- Secure data access management
- Admin control panel
- Third-party MCP server support
- Enterprise-grade security controls
📊 Evaluation & Optimization
Comprehensive tools for measuring and improving agent performance with automated testing and optimization.
- Datasets for component testing
- End-to-end trace grading
- Automated prompt optimization
- Third-party model evaluation support
- Custom grading criteria
🔒 Security & Guardrails
Built-in security layers protecting against data leakage, jailbreaks, and unintended behaviors.
- PII leak detection and prevention
- Jailbreak protection
- Content filtering
- OpenAI’s standard security measures
- Compliance-ready infrastructure
⚡ Performance
Optimized for rapid development and deployment with impressive benchmarks demonstrated at DevDay 2025.
- Live demo: 2 agents built in <8 minutes
- Hours to deploy vs months traditionally
- Built on Responses API
- Integration with GPT-5 Codex
- Dynamic thinking time adjustment
🎯 Real-World Success Story
Ramp (Fintech): Built a complete procurement agent in just a few hours instead of months using AgentKit. Their teams reported a 70% reduction in iteration cycles, launching agents in two sprints rather than two quarters. Agent Builder enabled seamless collaboration between product, legal, and engineering teams on the same visual canvas.
🛠️ Dify – Core Features
🎯 Visual Workflow Builder
Intuitive canvas for building and testing AI workflows with comprehensive model support and visual orchestration.
- Drag-and-drop workflow design
- Support for 100+ LLM models
- Real-time debugging with node inspection
- Variable tracking during execution
- Instant step-by-step testing
🧠 Comprehensive Model Support
Seamless integration with hundreds of proprietary and open-source LLMs from multiple providers.
- OpenAI: GPT-3.5, GPT-4, GPT-5
- Anthropic: Claude models
- Open-source: Llama3, Mistral, Qwen
- Self-hosted model support
- Any OpenAI API-compatible model
📚 RAG Pipeline
Extensive Retrieval-Augmented Generation capabilities covering the entire document lifecycle.
- Document ingestion from multiple formats
- PDF, PPT, Word extraction
- Vector database integration
- Advanced retrieval strategies
- Metadata-based filtering for security
🤖 Agent Node System
Flexible agent architecture with customizable strategies for autonomous decision-making within workflows.
- Plug-in “Agent Strategies”
- Autonomous task handling
- Custom tool integration
- Multi-agent collaboration
- Dynamic workflow adaptation
🎛️ Prompt Engineering IDE
Intuitive interface for crafting, testing, and comparing prompts across different models.
- Visual prompt editor
- Model performance comparison
- A/B testing capabilities
- Text-to-speech integration
- Template management
📊 Observability & Operations
Full visibility into AI application performance with comprehensive logging and monitoring.
- Complete execution logs
- Cost tracking per execution
- Conversation auditing
- Performance metrics dashboard
- Version control for workflows
🏢 Enterprise Features
Production-ready infrastructure with enterprise-grade security and scalability.
- Self-hosted deployment options
- AWS Marketplace integration
- Custom branding and white-labeling
- SSO and access control
- Multi-tenant architecture
🌐 Open Source Advantage
Community-driven development with transparent roadmap and extensive customization options.
- 180,000+ developer community
- 34,800+ GitHub stars
- Regular feature updates
- Community plugins and extensions
- Full code access and customization
🎯 Real-World Success Story
Volvo Cars: Uses Dify for rapid AI validation and deployment, enabling teams to quickly design and deploy complex NLP pipelines. This approach significantly improved assessment product quality while reducing both cost and time to market. Dify’s democratized AI development allows even non-technical team members to contribute to AI initiatives.
⚖️ Detailed Comparison
| Feature / Aspect |
OpenAI AgentKit |
Dify |
| Launch Date |
October 2025 (DevDay 2025) |
May 2023 (Established platform) |
| Source Model |
Proprietary, closed-source |
100% open-source (GitHub) |
| Ecosystem |
OpenAI-exclusive (GPT models) |
Multi-provider (100+ LLMs from dozens of providers) |
| Deployment Options |
Cloud-based on OpenAI platform only |
Self-hosted, cloud, or hybrid deployment |
| Data Sovereignty |
Managed by OpenAI infrastructure |
Full control – host anywhere, complete data ownership |
| Model Support |
OpenAI models (GPT-3.5, GPT-4, GPT-5, Codex) |
GPT, Claude, Llama3, Mistral, Qwen, self-hosted models, any OpenAI-compatible API |
| Visual Builder |
✓ Agent Builder (drag-and-drop, currently in beta) |
✓ Visual workflow canvas (production-ready) |
| RAG Capabilities |
Limited documentation available |
Extensive: document ingestion, retrieval, PDF/PPT/Word extraction, vector databases, metadata filtering |
| Chat Interface |
ChatKit (embeddable, customizable) |
Built-in chat UI with full customization |
| Connectors |
Connector Registry (Dropbox, Drive, SharePoint, Teams, MCP servers) – Limited beta |
Extensive integration options, custom API connections, community plugins |
| Evaluation Tools |
Datasets, trace grading, automated prompt optimization, custom graders |
Full observability, debugging tools, version control, execution logs |
| Security Features |
PII detection, jailbreak protection, OpenAI security standards, guardrails |
Self-managed security, SSO, access control, custom security policies |
| Community Size |
New (launched Oct 2025), growing adoption |
180,000+ developers, 59,000+ end users, 34,800+ GitHub stars |
| Pricing Model |
Included with standard API pricing, enterprise features for some components |
Free tier, Professional ($59/month), Team ($159/month), Enterprise (custom) |
| Development Speed |
Hours to build agents (demo showed <8 minutes for 2 agents) |
Rapid prototyping, established workflow templates |
| Customization |
Within OpenAI ecosystem constraints |
Unlimited – full code access, custom modifications possible |
| Learning Curve |
Low – designed for ease of use |
Low to medium – extensive documentation and community support |
| Best For |
OpenAI-committed teams, rapid prototyping, enterprise users wanting managed solution |
Multi-provider needs, data sovereignty requirements, open-source advocates, full customization |
| Production Readiness |
ChatKit & Evals: Generally available
Agent Builder: Beta
Connector Registry: Limited beta |
Fully production-ready, battle-tested by 180,000+ developers |
| API Integration |
Built on OpenAI Responses API |
RESTful API, webhook support, extensive integration options |
✅ Pros & Cons Analysis
OpenAI AgentKit
Advantages
- Rapid Development: Build functional agents in hours rather than months with visual tools
- Seamless Integration: Deep integration with OpenAI ecosystem and GPT models
- Enterprise Security: Built-in guardrails, PII protection, and OpenAI security standards
- Managed Infrastructure: No DevOps burden, fully managed by OpenAI
- Cutting-Edge Models: Immediate access to latest GPT models and features
- Live Demo Success: Proven capability (2 agents in <8 minutes)
- Unified Toolkit: All necessary tools in one platform
- Evaluation Tools: Comprehensive testing and optimization features
Limitations
- Vendor Lock-in: Exclusively tied to OpenAI ecosystem
- Limited Model Choice: Cannot use Claude, Llama, or other non-OpenAI models
- New Platform: Just launched (Oct 2025), limited production track record
- Beta Features: Key components still in beta (Agent Builder, Connector Registry)
- No Data Sovereignty: Data managed by OpenAI, not self-hostable
- Closed Source: Cannot inspect or modify underlying code
- Pricing Uncertainty: Costs tied to OpenAI API pricing model
- Limited Customization: Constrained by platform design decisions
Dify
Advantages
- Open Source Freedom: Full code access, unlimited customization, no vendor lock-in
- Multi-Provider Support: Use any LLM – GPT, Claude, Llama, Mistral, or self-hosted models
- Data Sovereignty: Complete control over data, self-hosting options
- Extensive RAG: Comprehensive document processing and retrieval capabilities
- Large Community: 180,000+ developers, active development, extensive resources
- Production Proven: Battle-tested since 2023, used by major companies like Volvo
- Flexible Deployment: Cloud, self-hosted, or hybrid options
- Cost Control: Use cheaper models or self-hosted options, transparent pricing
- No Vendor Dependencies: Switch providers or models without platform changes
Limitations
- DevOps Responsibility: Self-hosting requires infrastructure management
- Learning Curve: More complex than managed solutions for beginners
- No Native OpenAI Features: Latest OpenAI-specific features may lag
- Security Setup: Must configure own security measures for self-hosted
- Community Support: Relies on community vs dedicated support team
- Integration Effort: May require more work to integrate custom tools
- Scalability Management: Need to handle scaling for high-traffic scenarios
💡 Use Cases & Applications
OpenAI AgentKit – Ideal Use Cases
🏢 Enterprise Rapid Prototyping
Large organizations already invested in OpenAI wanting to quickly deploy AI agents across multiple departments without heavy technical overhead.
🚀 Startup MVPs
Startups needing to build and iterate on AI-powered products rapidly with minimal infrastructure investment and maximum speed to market.
💼 Business Process Automation
Companies automating internal workflows like procurement, customer support, or data analysis using OpenAI’s latest models.
🔬 Research & Development
Teams exploring cutting-edge AI capabilities with OpenAI’s latest models and wanting managed infrastructure for experiments.
Dify – Ideal Use Cases
🏦 Regulated Industries
Banking, healthcare, or government organizations requiring full data sovereignty, self-hosting, and complete audit trails.
🌐 Multi-Model Applications
Projects needing to leverage multiple LLM providers for cost optimization, feature diversity, or redundancy.
🛠️ Custom AI Solutions
Development teams building highly customized AI applications requiring deep integration with existing systems and workflows.
📚 Knowledge Management
Organizations building comprehensive RAG systems with complex document processing, vector search, and metadata filtering needs.
🎓 Educational & Research
Academic institutions and researchers needing transparent, customizable AI systems with full control over model selection and data.
🌍 Global Operations
International companies needing to deploy AI across multiple regions with varying data residency requirements.
💰 Pricing Comparison
OpenAI AgentKit Pricing
Model: Included with standard OpenAI API pricing. You pay for:
- API calls to GPT models (token-based pricing)
- Standard OpenAI usage fees apply
- Enterprise features may have additional costs
- Connector Registry requires Global Admin Console (available for Enterprise/Edu)
Advantage: No separate platform fee, but tied to OpenAI’s pricing
Consideration: Costs can scale significantly with high usage; no control over rate changes
Dify Pricing
Sandbox (Free):
- 200 OpenAI calls included
- Core features access
- Ideal for testing and small projects
Professional ($59/month):
- For independent developers & small teams
- Production AI applications
- Increased resources and team collaboration
Team ($159/month):
- Medium-sized teams
- Higher throughput requirements
- Advanced collaboration features
Enterprise (Custom):
- Custom deployment options
- Dedicated support
- SLA guarantees
- On-premise or private cloud hosting
Self-Hosted (Free):
- Deploy on your own infrastructure at no platform cost
- Only pay for your chosen LLM provider (can use cheaper options)
- Complete cost control
🎯 Decision Framework: Which Platform Should You Choose?
Choose OpenAI AgentKit If:
- You’re already heavily invested in the OpenAI ecosystem
- You want the fastest possible time-to-market with minimal setup
- Your use case doesn’t require data to stay on-premise
- You prefer managed infrastructure over self-hosting
- You need the latest GPT models immediately upon release
- Your team lacks DevOps resources for infrastructure management
- Budget allows for OpenAI’s premium pricing model
- You value tight integration over flexibility
- Compliance allows cloud-based AI processing
- You’re comfortable with platform limitations for ease of use
Choose Dify If:
- You need to use multiple LLM providers or specific models
- Data sovereignty and privacy are critical requirements
- You want complete control over your AI infrastructure
- Your organization requires self-hosted solutions
- Cost optimization through model flexibility is important
- You have DevOps capability for self-hosting
- You need extensive RAG and document processing capabilities
- Open-source transparency is a requirement
- You want to avoid vendor lock-in
- Your use case requires deep customization
- You’re in a regulated industry (banking, healthcare, government)
- You prefer community-driven development
🔮 Future Outlook & Roadmap
OpenAI AgentKit Roadmap
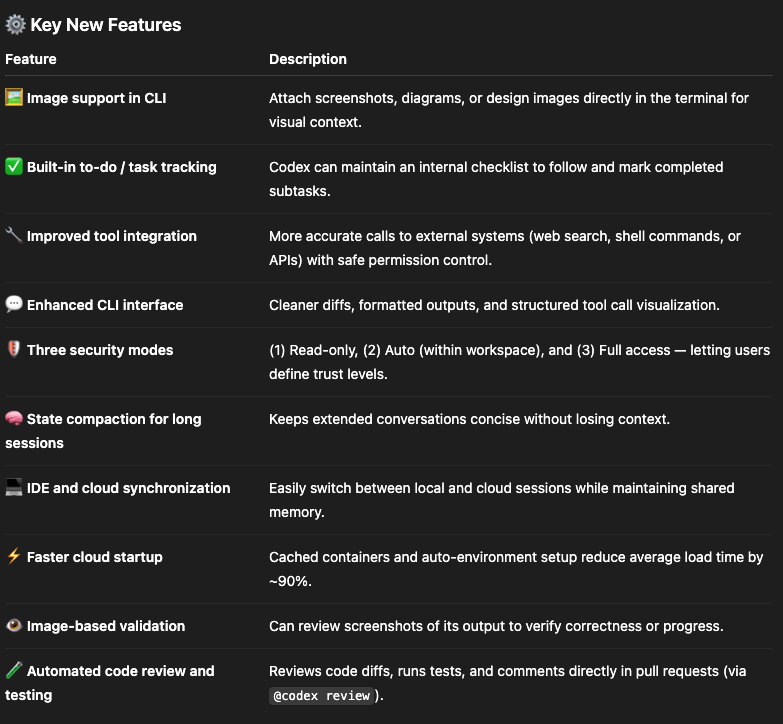
OpenAI plans to add standalone Workflows API and agent deployment options to ChatGPT. Expect rapid iteration and new features as the platform matures beyond beta stage.
Dify Development
Active open-source development with regular releases. Community-driven feature requests and transparent roadmap on GitHub. Continuous improvements to RAG, workflows, and integrations.
Market Competition
Both platforms face competition from LangChain, n8n, Zapier Central, and others. The AI agent space is rapidly evolving with new players entering regularly.
Convergence Trends
Expect features to converge over time as both platforms mature. Visual builders, multi-agent orchestration, and evaluation tools are becoming industry standards.
🎓 Final Recommendation
For most organizations: The choice depends on your priorities. If you value speed, simplicity, and are committed to OpenAI, AgentKit offers the fastest path to production agents. If you need flexibility, data control, and multi-provider support, Dify provides superior long-term value despite requiring more initial setup.
Hybrid Approach: Some organizations use AgentKit for rapid prototyping and Dify for production deployments where data sovereignty and model flexibility matter. This combines the speed of AgentKit with the control of Dify.
Last Updated: October 2025 | Based on OpenAI DevDay 2025 announcements
Sources: Official OpenAI documentation, Dify GitHub repository, TechCrunch, VentureBeat, Medium technical analyses
This comparison is for informational purposes. Features and pricing subject to change. Always consult official documentation for the most current information.
Building Intelligent AI Agents with OpenAI: From Raw API to Official Agents SDK
Introduction
Artificial Intelligence agents are revolutionizing how we interact with technology. Unlike traditional chatbots that simply respond to queries, AI agents can understand context, make decisions, and use tools to accomplish complex tasks autonomously. This project demonstrates how to build progressively sophisticated AI agents using both the OpenAI API and the official OpenAI Agents SDK.
Whether you’re a beginner exploring AI development or an experienced developer looking to integrate intelligent agents into your applications, this sample project provides practical, hands-on examples comparing two approaches: custom implementation using raw OpenAI API and using the official Agents SDK.
What is an AI Agent?
An AI agent is an autonomous system powered by a language model that can:
- Understand natural language instructions
- Make intelligent decisions about which tools to use
- Execute functions to interact with external systems
- Reason about results and provide meaningful responses
- Collaborate with other agents to solve complex problems
Think of it as giving your AI assistant a toolbox. Instead of just talking, it can now check the weather, perform calculations, search databases, and much more.
Project Overview
The OpenAI AgentKit Sample Project demonstrates six levels of AI agent sophistication across two implementation approaches:
OpenAI API Approach (Custom Implementation)
1. Basic Agent
A foundational implementation showing how to set up OpenAI’s Chat Completions API.
What you’ll learn:
- Setting up the OpenAI client
- Configuring system and user messages
- Managing model parameters (temperature, tokens)
- Handling API responses
2. Agent with Tools
Introduces function calling where the agent decides when and how to use specific tools.
Available Tools:
- Weather Tool: Retrieves current weather information
- Calculator Tool: Performs mathematical operations
- Time Tool: Gets current date and time across timezones
3. Advanced Agent
Production-ready example with sophisticated features including detailed logging, error handling, and multiple complex tools.
Enhanced Capabilities:
- Wikipedia search integration
- Sentiment analysis
- Timezone-aware time retrieval
- Comprehensive error handling
- Performance statistics and logging
OpenAI Agents SDK Approach (Official Framework)
4. SDK Basic Agent
Simple agent using the official OpenAI Agents SDK with automatic agent loop and simplified API.
Key Features:
- Uses
Agent and run from @openai/agents
- Automatic conversation management
- Clean, minimal code
5. SDK Agent with Tools
Agent with tools using proper SDK conventions and automatic schema generation.
Tools:
- Weather lookup with Zod validation
- Mathematical calculations
- Time zone support
Key Features:
- Tools defined with
tool() helper
- Zod-powered parameter validation
- Automatic schema generation from TypeScript types
6. SDK Multi-Agent System
Sophisticated multi-agent system with specialized agents and handoffs.
Agents:
- WeatherExpert: Handles weather queries
- MathExpert: Performs calculations
- KnowledgeExpert: Searches knowledge base
- Coordinator: Routes requests to specialists
Technology Stack
OpenAI API
GPT-4o-mini model for intelligent responses
@openai/agents
Official OpenAI Agents SDK
Zod
Runtime type validation and schema generation
Node.js
Runtime environment (22+ required for SDK)
Express.js
Web server framework
dotenv
Environment variable management
Getting Started
Prerequisites
Installation
1. Clone or download the project
cd openai-agentkit-sample
2. Install dependencies
npm install
This will install:
openai – Raw OpenAI API client@openai/agents – Official Agents SDKzod – Schema validation- Other dependencies
3. Configure environment variables
cp .env.example .env
Edit .env and add your OpenAI API key:
OPENAI_API_KEY=sk-your-actual-api-key-here
Running the Examples
Start the web server:
npm start
Open http://localhost:3000 in your browser
Run OpenAI API examples:
npm run example:basic # Basic agent
npm run example:tools # Agent with tools
npm run example:advanced # Advanced agent
Run OpenAI Agents SDK examples:
npm run example:sdk-basic # SDK basic agent
npm run example:sdk-tools # SDK with tools
npm run example:sdk-multi # Multi-agent system
Comparing the Two Approaches
OpenAI API (Custom Implementation)
Pros:
- Full control over every aspect
- Deep understanding of agent mechanics
- Maximum flexibility
- No framework constraints
Cons:
- More code to write and maintain
- Manual agent loop implementation
- Manual tool schema definition
- More error-prone
Example – Tool Definition (Raw API):
const weatherTool = {
type: 'function',
function: {
name: 'get_weather',
description: 'Get the current weather in a given location',
parameters: {
type: 'object',
properties: {
location: {
type: 'string',
description: 'The city and country',
},
unit: {
type: 'string',
enum: ['celsius', 'fahrenheit'],
},
},
required: ['location'],
},
},
};
// Manual tool execution
function executeFunction(functionName, args) {
switch (functionName) {
case 'get_weather':
return getWeather(args.location, args.unit);
// ... more cases
}
}
OpenAI Agents SDK (Official Framework)
Pros:
- Less code, faster development
- Automatic agent loop
- Automatic schema generation from Zod
- Built-in handoffs for multi-agent systems
- Production-ready patterns
- Type-safe with TypeScript
Cons:
- Less control over internals
- Framework learning curve
- Tied to SDK conventions
- Node.js 22+ requirement
Example – Tool Definition (Agents SDK):
import { tool } from '@openai/agents';
import { z } from 'zod';
const getWeatherTool = tool({
name: 'get_weather',
description: 'Get the current weather for a given location',
parameters: z.object({
location: z.string().describe('The city and country'),
unit: z.enum(['celsius', 'fahrenheit']).optional().default('celsius'),
}),
async execute({ location, unit }) {
// Tool implementation
return JSON.stringify({ temperature: 22, condition: 'Sunny' });
},
});
// Automatic execution - no switch statement needed!
const agent = new Agent({
tools: [getWeatherTool],
});
Key Concepts
Function Calling / Tool Usage
Both approaches support function calling, where the AI model can “call” functions you define:
- Define tool: Describe function, parameters, and purpose
- Model decides: Model automatically decides when to use tools
- Execute tool: Your code executes the function
- Return result: Send result back to model
- Final response: Model uses result to create answer
OpenAI Agents SDK Advantages
The Agents SDK provides several powerful features:
Automatic Schema Generation:
// SDK automatically generates JSON schema from Zod!
z.object({
city: z.string(),
unit: z.enum(['celsius', 'fahrenheit']).optional(),
})
Agent Handoffs:
const coordinator = new Agent({
handoffs: [weatherAgent, mathAgent, knowledgeAgent],
});
// Coordinator can automatically route to specialists
Built-in Agent Loop:
// SDK handles the entire conversation loop
const result = await run(agent, "What's the weather in Hanoi?");
console.log(result.finalOutput);
Practical Use Cases
Customer Service Automation
- Answer questions using knowledge bases
- Check order status
- Process refunds
- Escalate to human agents
- Route to specialized agents
Personal Assistant Applications
- Schedule management
- Email drafting
- Research and information gathering
- Task automation
- Multi-task coordination
Data Analysis Tools
- Query databases
- Generate reports
- Perform calculations
- Visualize insights
- Collaborate across data sources
Best Practices
1. Clear Tool Descriptions
Make function descriptions detailed and specific:
Good:
description: 'Get the current weather including temperature, conditions, and humidity for a specific city and country'
Bad:
description: 'Get weather'
2. Use Zod for Validation (SDK)
parameters: z.object({
email: z.string().email(),
age: z.number().min(0).max(120),
role: z.enum(['admin', 'user', 'guest']),
})
3. Error Handling
Always implement comprehensive error handling:
async execute({ city }) {
try {
const result = await weatherAPI.get(city);
return JSON.stringify(result);
} catch (error) {
return JSON.stringify({ error: error.message });
}
}
4. Tool Modularity
Create small, focused tools rather than monolithic ones:
// Good - specific tools
const getWeatherTool = tool({...});
const getForecastTool = tool({...});
// Bad - one giant tool
const weatherAndForecastAndHistoryTool = tool({...});
Multi-Agent Patterns
The Agents SDK excels at multi-agent workflows:
Specialist Pattern
const weatherExpert = new Agent({
name: 'WeatherExpert',
tools: [getWeatherTool],
});
const mathExpert = new Agent({
name: 'MathExpert',
tools: [calculateTool],
});
const coordinator = new Agent({
handoffs: [weatherExpert, mathExpert],
});
Hierarchical Delegation
- Coordinator receives user request
- Analyzes which specialist is needed
- Hands off to appropriate agent
- Aggregates results
- Returns unified response
API Endpoints
The project includes a web server with both approaches:
Raw API:
POST /api/chat/basic – Basic chat completionPOST /api/chat/with-tools – Manual tool handling
Agents SDK:
POST /api/chat/agents-sdk – SDK-powered agent with tools
When to Use Which Approach?
Use OpenAI API (Custom Implementation) When:
- You need full control and customization
- Learning how agents work at a low level
- Implementing highly custom logic
- Working with existing codebases
- Framework constraints are a concern
Use OpenAI Agents SDK When:
- Building production applications quickly
- Need multi-agent workflows
- Want type-safe tool definitions
- Prefer less boilerplate code
- Following best practices matters
- Team collaboration is important
Performance Considerations
- Model Selection: GPT-4o-mini offers great balance of capability and cost
- Caching: Consider caching frequent queries
- Async Operations: Use Promise.all() for parallel tool execution
- Response Streaming: Implement for better UX
- Rate Limiting: Monitor and manage API rate limits
Troubleshooting
Issue: “Invalid API Key”
- Verify
.env file contains correct API key
- Check key is active in OpenAI dashboard
Issue: Tools Not Being Called
- Ensure tool descriptions are clear and specific
- Try more explicit user prompts
- Check parameter schemas are correctly formatted
Issue: “Unsupported tool type”
- Use
tool() helper with Agents SDK
- Ensure Zod schemas are properly defined
- Check you’re importing from
@openai/agents
Resources
Comparison Table
| Feature |
Raw OpenAI API |
Agents SDK |
| Code Lines |
~200 for basic agent with tools |
~50 for same functionality |
| Schema Definition |
Manual JSON |
Automatic from Zod |
| Agent Loop |
Manual implementation |
Built-in |
| Type Safety |
Limited |
Full TypeScript support |
| Multi-Agent |
Manual implementation |
Built-in handoffs |
| Learning Curve |
Steep |
Moderate |
| Flexibility |
Maximum |
High |
| Production Ready |
Requires work |
Out-of-the-box |
| Node.js Requirement |
18+ |
22+ |
Conclusion
This project demonstrates two powerful approaches to building AI agents:
- Raw OpenAI API: Provides deep understanding and maximum control. Perfect for learning and custom implementations.
- OpenAI Agents SDK: Offers productivity, type safety, and production-ready patterns. Ideal for building real applications quickly.
Both approaches have their place. Start with the SDK for production work, but understanding the raw API approach gives you insights into how agents actually work.
Next Steps
- Experiment: Run all six examples
- Compare: Notice the differences in code complexity
- Customize: Create your own tools
- Integrate: Connect real APIs
- Deploy: Move to production with proper error handling
- Scale: Implement multi-agent systems for complex tasks
Contributing
Contributions, suggestions, and improvements are welcome! Feel free to:
- Report issues
- Submit pull requests
- Share your custom tools
- Suggest new examples
License
MIT License – Feel free to use this project for learning, development, or commercial purposes.
Ready to build your own AI agents?
Clone the repository, follow the setup instructions, and start with whichever approach fits your needs. The future of intelligent automation is in your hands!