
1. Purpose and Background
Introduced in Dify version 1.9.0, the Knowledge Pipeline marks a significant architectural evolution alongside the new Queue-based Graph Engine.
In essence, its purpose is to address real-world challenges that RAG (Retrieval-Augmented Generation) systems often face when handling knowledge and documents. These include:
-
The limitation of integrating diverse data sources such as files, web content, and cloud drives.
-
The loss of critical information like tables, images, and complex structures during ingestion, chunking, or retrieval.
-
Inefficient or rigid chunking strategies that result in poor retrieval accuracy and loss of context.
The Knowledge Pipeline solves these issues by introducing a modular and open-ended architecture that clearly defines each stage — from raw data ingestion → processing → storage → retrieval — allowing developers to adjust, customize, and extend it easily.
As project leaders often point out: when building an AI application with domain-specific requirements (such as customer support, internal assistants, or technical document analysis), you need a knowledge workflow far more advanced than just “upload a PDF and vectorize.” That’s exactly the gap Knowledge Pipeline fills.
2. Main Use Cases
Below are the primary use cases where the Knowledge Pipeline demonstrates its strengths — many drawn from real project experience:
a. Multi-source and Multi-type Data Integration
Organizations often store information across multiple systems — Word, Excel, PDF, images, spreadsheets, websites, or even internal web crawlers.
The Knowledge Pipeline allows you to connect to multiple data sources through configurable ingestion nodes and plug-ins.
For enterprise-level AI assistants, pulling data from Google Drive, OneDrive, internal file systems, or web URLs is essential — and this framework supports such extensibility out of the box.
b. Complex Pre-processing before Knowledge Storage
-
Advanced chunking: Beyond the traditional “General” and “Parent-Child” chunking modes, Dify now supports Q&A Processor plug-ins that structure content in a question-answer format, greatly improving retrieval precision.
-
Image extraction: Images embedded in documents are extracted and stored as URLs, allowing models to generate answers that include both text and visuals.
-
Table and structured data handling: For technical or spreadsheet-heavy documents, the pipeline enables pre-processing to normalize and extract metadata before chunking and indexing.
c. Building Domain-specific and Scalable RAG Applications
With its modular design, the pipeline allows developers to build domain-tailored workflows.
For example, a product-support RAG system may combine PDF manuals, extracted images, and video transcripts as input. The processing node might focus on extracting tables and diagrams, and the indexing node would attach domain-specific metadata such as product_version or module_name for context-aware retrieval.
This approach helps enterprises transform “raw data” into actionable knowledge, leading to more accurate and context-rich responses.
d. Debugging and Step-by-Step Validation
Large-scale ingestion pipelines are notoriously hard to debug. Without visibility into each step, it’s easy to face “blind errors.”
Dify’s Knowledge Pipeline allows step-wise test runs and variable previews at every node — making it possible to inspect chunks, extracted content, and intermediate data before final indexing.
For instance, in one enterprise project with over a million PDF pages, chunk sizes were initially too small, leading to poor retrieval quality. By debugging only the chunking node, we identified and fixed the issue quickly, saving both time and compute resources.
3. Key Features
Here’s a summary of the core features that make Dify’s Knowledge Pipeline stand out:
-
Node-based orchestration interface: Visually build your workflow (ingest → process → chunk → index) using modular blocks.
-
Templates and Pipeline DSL: Start quickly with built-in templates or export/import pipelines using DSL for team reuse.
-
Plug-in system for data sources and processors: Add new connectors and processors (e.g., spreadsheets, image parsers) to handle non-text content.
-
Extended chunking strategies: New chunking modes designed for Q&A or structured text improve retrieval accuracy.
-
Image extraction and multimodal support: Extract and link images within documents to enable text-plus-image responses.
-
Debugging and test-run capabilities: Execute individual nodes, inspect variables, and preview markdown results before deployment.
-
One-click migration from legacy knowledge bases: Easily upgrade from the old ingestion + vectorization flow to the new pipeline without rebuilding your knowledge base.
4. Real-world example
4.1 Guide to Using the Knowledge Pipeline to Convert Data from an .xlsx File to Markdown Format and Then Save It as Knowledge Data
Prerequisite: Install the following plugins
- Markitdown: https://marketplace.dify.ai/plugins/yevanchen/markitdown
- Parent-child Chunker: https://marketplace.dify.ai/plugins/langgenius/parentchild_chunker
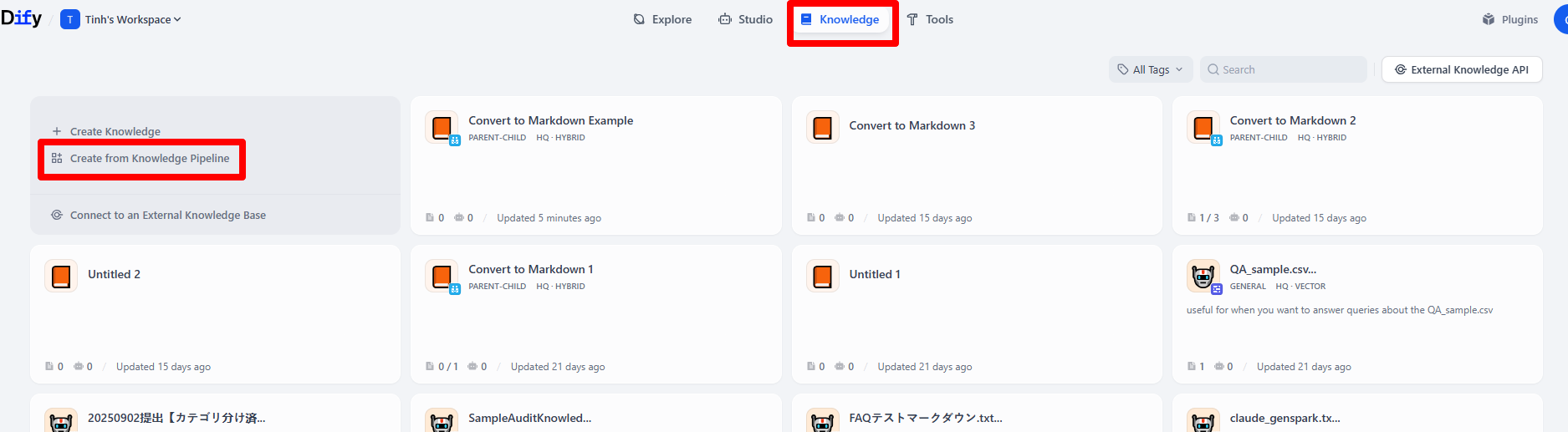
Step 2: Select “Blank Knowledge Pipeline”
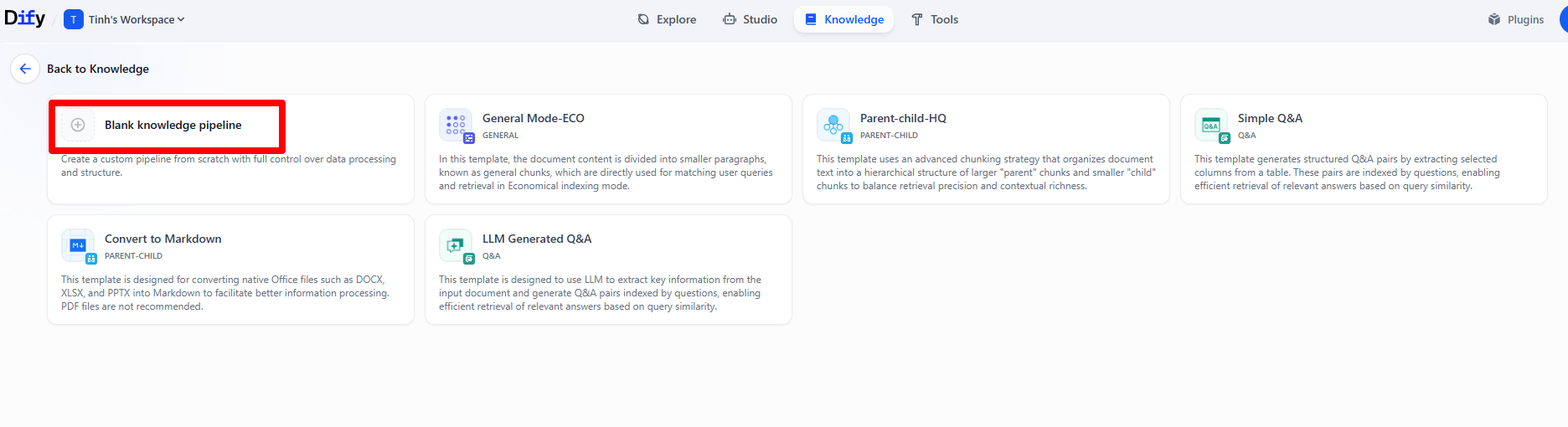
Step 3: On the next screen, select “File” as the data source to allow users to upload their file.
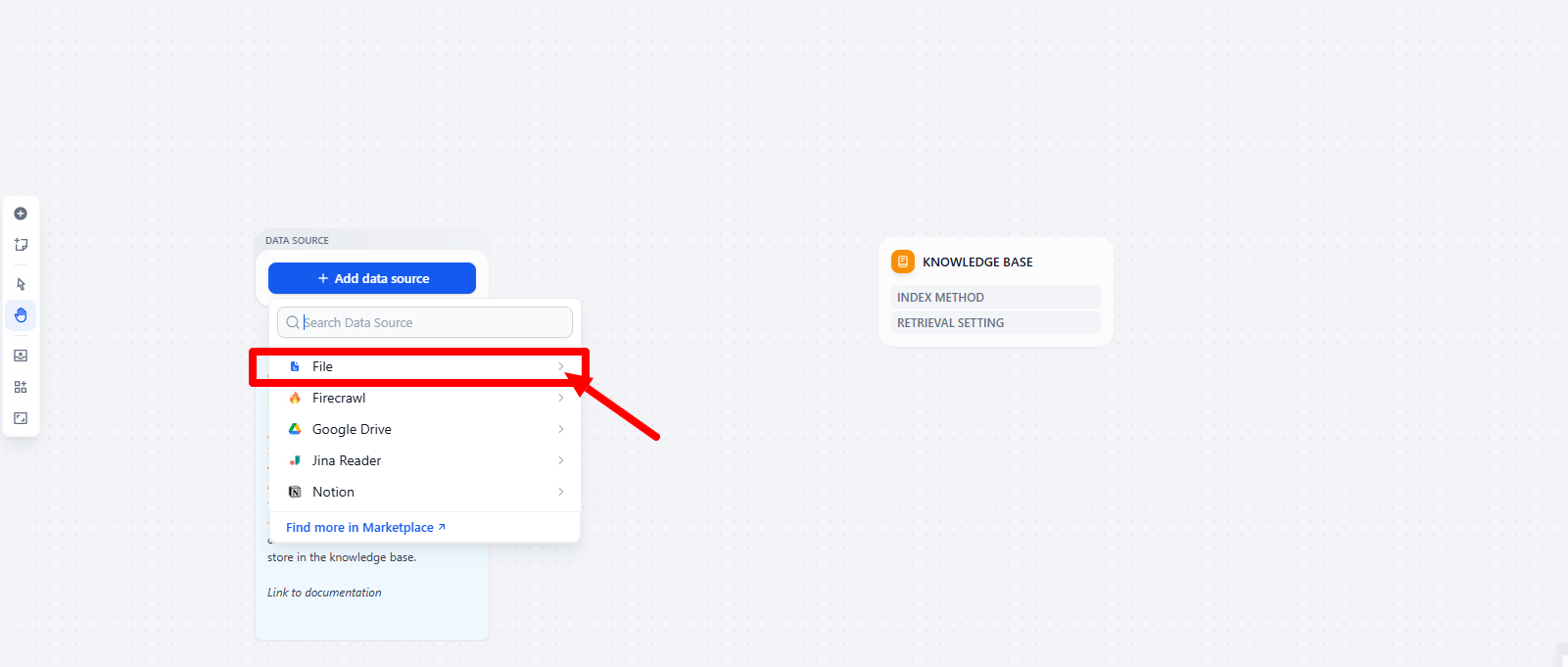
Step 4: To convert the data into Markdown format, you need to use the plugin markitdown.
This library allows you to convert various document types into Markdown format, including:
-
PDF
-
PowerPoint
-
Word
-
Excel
-
Images (EXIF metadata, OCR)
-
Audio (EXIF metadata, speech transcription)
-
HTML
-
Text-based formats
-
ZIP archives
-
YouTube URLs
-
EPUBs
Add a new node, go to the “Tools” tab, and select “Markitdown” to use this plugin.
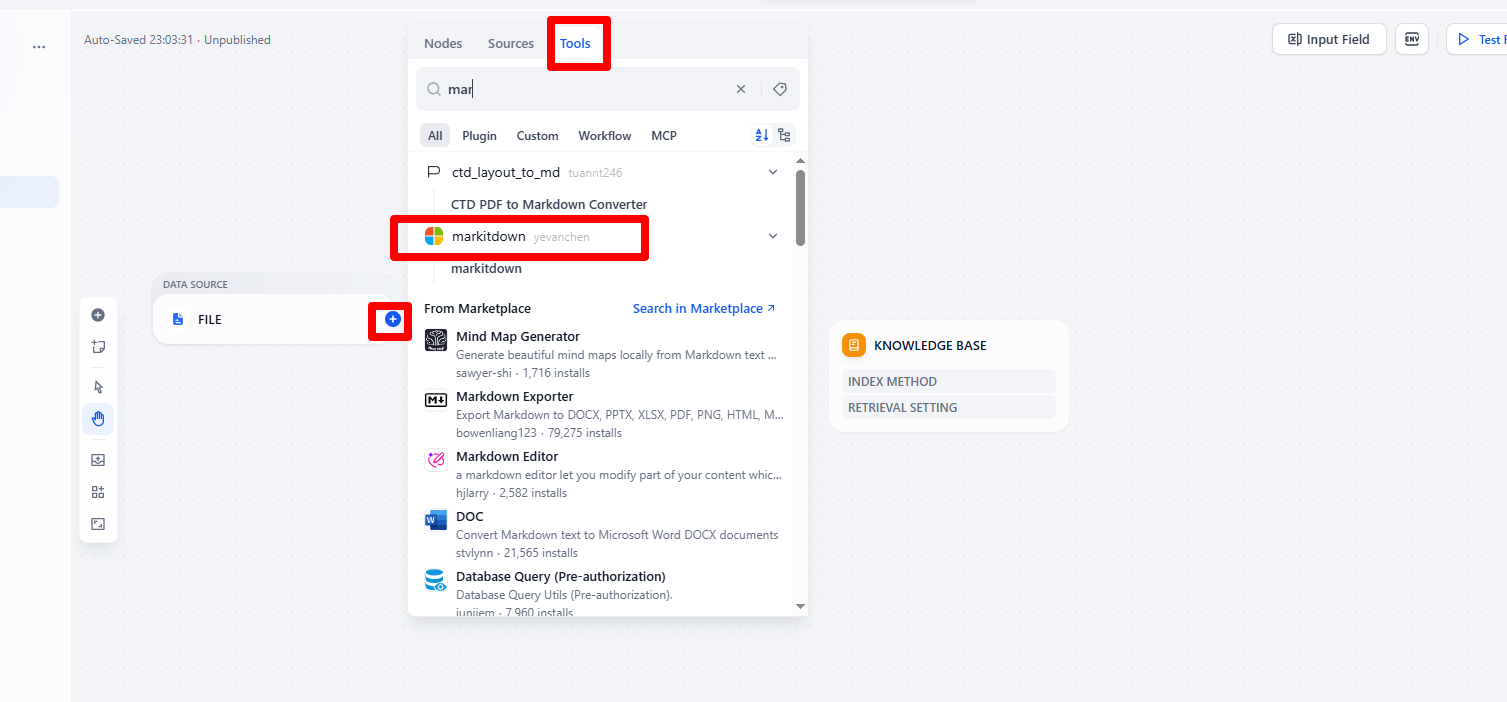
Don’t forget to set the input for this node as the uploaded file.
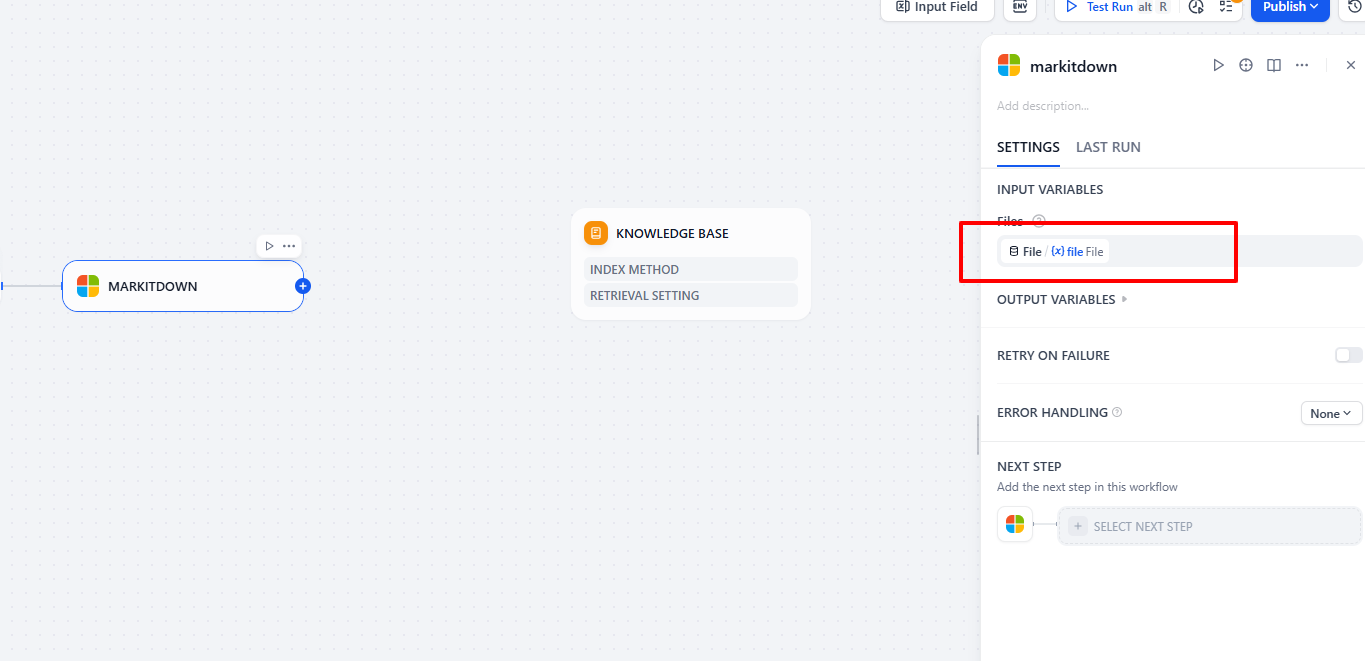
Step 5: Structure and Segment Content Using Parent-child Chunker
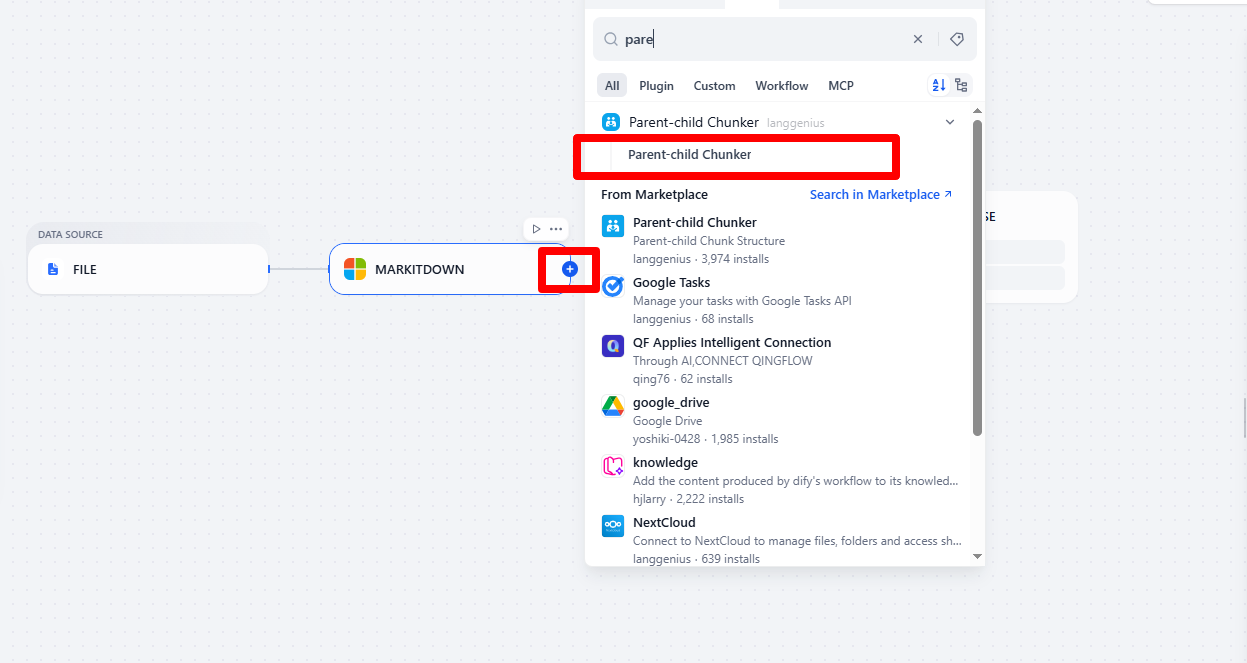
Don’t forget to set up the input and configure the related parameters.
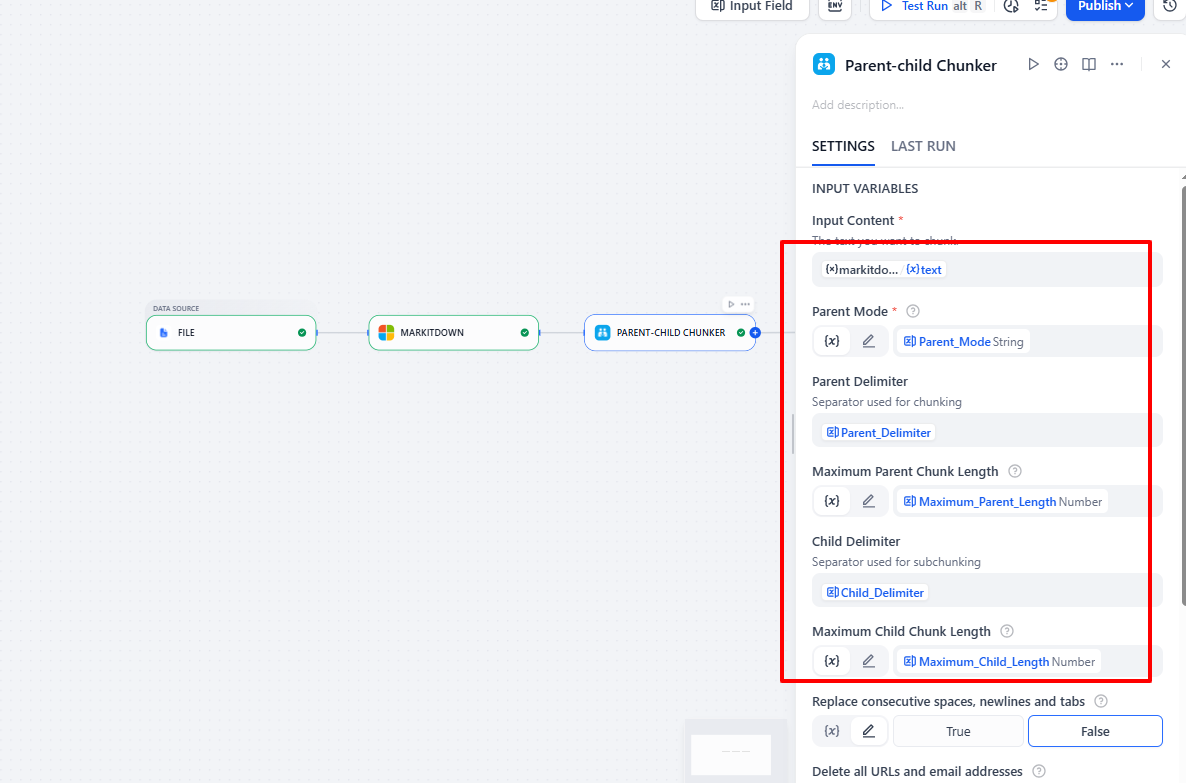
Step 6: Create Knowledge
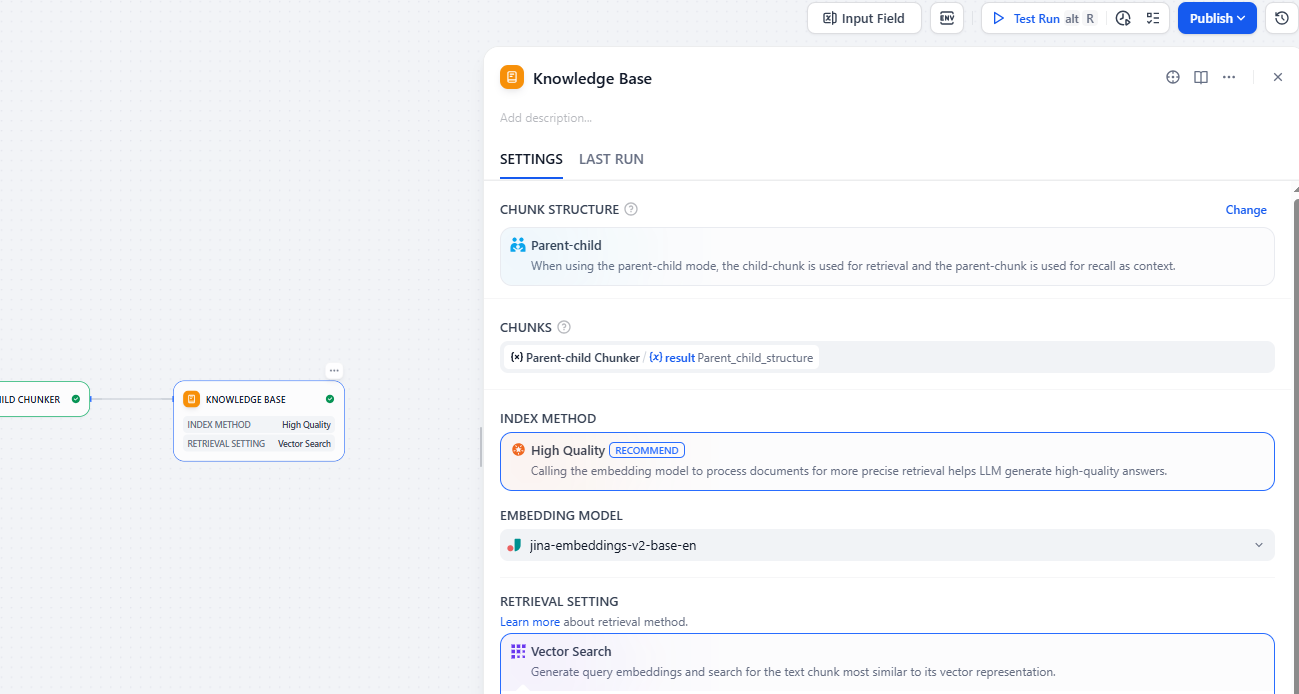
After this step, publish your pipeline and create a Knowledge using the pipeline you’ve just configured.
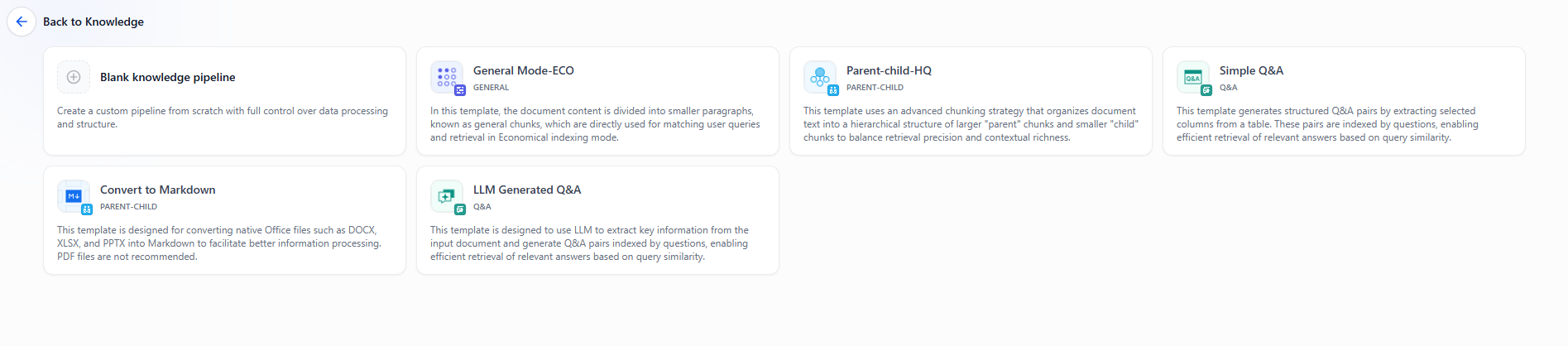
In addition to the example above, you can also use one of the pre-built templates provided by Dify if it suits your purpose.
5. Conclusion
From the perspective of someone with extensive experience in AI and RAG projects, Dify’s Knowledge Pipeline represents a major leap forward — bridging the gap between experimental prototypes and production-grade enterprise AI systems.
It transforms knowledge management from a simplistic “upload → vectorize → query” loop into a scalable, debuggable, and extensible framework capable of handling diverse and complex knowledge sources.
For organizations building domain-specific AI assistants or knowledge bots, adopting the Knowledge Pipeline early can dramatically improve retrieval quality, flexibility, and system reliability.
However, with this flexibility comes responsibility: the more modular the pipeline, the more critical it becomes to design clear workflows, define each node purposefully, and test each step thoroughly before deployment.
Ref: https://github.com/langgenius/dify/discussions/26138