
At the heart of multimodal LLMs is a powerful idea: all input types, whether text, images, or audio. But how does a single AI system understand such fundamentally different types of data? In this article, we try to answer this question.
From Single-Modal to Multimodal Intelligence
Traditional machine learning systems were typically designed to handle a single modality at a time—text-only language models, image-only vision models, or audio-focused speech models. This separation limited their ability to reason holistically about real-world data, which naturally combines text, visuals, sound, and motion.
Multimodal Large Language Models (LLMs) address this limitation by integrating multiple data modalities into a single unified reasoning system. Instead of building independent pipelines for each input type, modern architectures allow different modalities to be processed together, enabling richer understanding and more complex cross-modal reasoning.
A Shared Mathematical Language
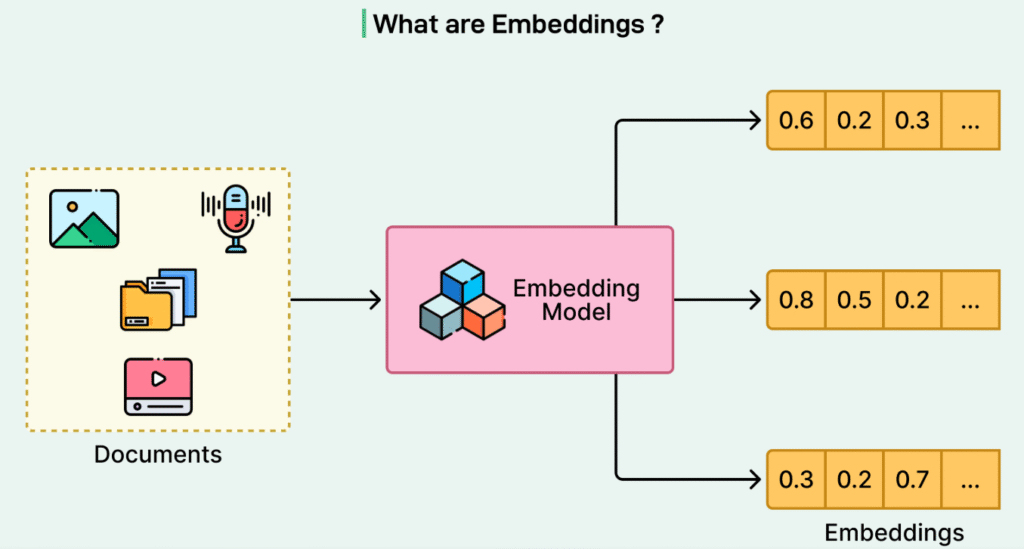
The foundational concept behind multimodal LLMs is the idea of a shared embedding space. Regardless of whether the input is text, an image, or audio, each modality is ultimately converted into a vector representation (embedding) within the same high-dimensional space.
In this shared mathematical language:
- The word “cat”
- An image of a cat
- The sound of a cat meowing
are all mapped to nearby regions in the embedding space. This alignment allows the model to reason about relationships across modalities using the same attention and inference mechanisms. The model no longer “sees” raw pixels or waveforms—it reasons over vectors.
Modality-Specific Encoders
Before different inputs can be unified, they must first be transformed into numerical representations. This is the role of modality-specific encoders, each optimized for a particular data type:
- Text encoders tokenize language and convert tokens into embeddings.
- Vision encoders (often Vision Transformers) split images into fixed-size patches and encode them as visual tokens.
- Audio encoders transform raw waveforms into spectrogram-like representations that can be embedded numerically.
These encoders act as the first stage of processing, converting raw, unstructured inputs into structured vector sequences.
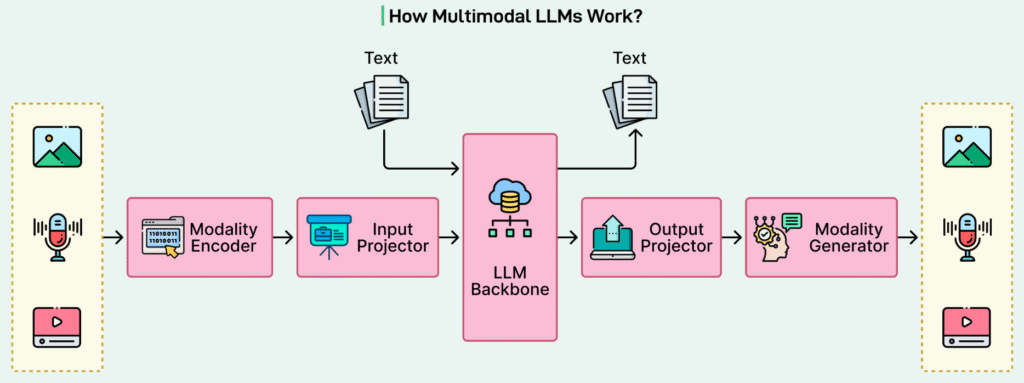
Projection into a Unified Embedding Space
Each encoder initially produces embeddings in its own latent space, which may not be directly compatible with others. To resolve this, multimodal systems use projection layers—typically lightweight neural networks—that map modality-specific embeddings into a common embedding space.
This projection step is critical. Without proper alignment, the language model would be unable to meaningfully combine or compare representations from different modalities. Successful projection ensures that semantic similarity is preserved across text, vision, and audio inputs.
The Language Model as a Universal Reasoning Engine
Once all inputs are projected into the same embedding space, they are fed into the language model backbone, usually a large transformer. At this stage, the model treats all inputs as sequences of tokens, regardless of their original modality.
The transformer’s attention mechanism enables:
- Cross-modal reasoning (e.g., linking text queries to visual regions)
- Contextual understanding across time and modalities
- Generation of coherent outputs conditioned on mixed inputs
Importantly, the language model itself is not modality-specific. It serves as a general-purpose reasoning engine operating over unified embeddings.
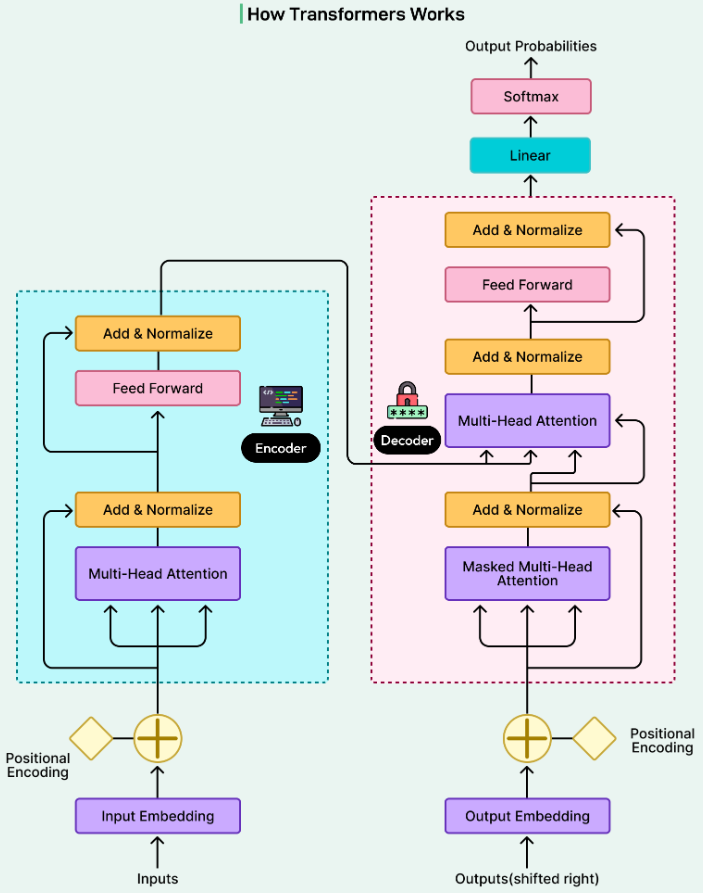
Treating Images and Audio as Tokens
A key architectural breakthrough enabling multimodal LLMs is the realization that non-text data can be modeled as token sequences. Image patches and audio frames can be ordered and processed similarly to word tokens.
This abstraction allows existing transformer architectures—originally designed for language—to be reused for vision and audio tasks with minimal modification. As a result, multimodal models scale efficiently by leveraging proven language model designs.
Training and Cross-Modal Alignment
To align different modalities effectively, multimodal LLMs rely on large-scale training techniques such as contrastive learning. These methods encourage semantically related inputs (e.g., an image and its caption) to produce similar embeddings while pushing unrelated inputs apart.
Through this process, the model learns consistent representations across modalities, enabling tasks such as image captioning, visual question answering, audio-text understanding, and video reasoning.
A Unified Model for Multimodal Understanding
Rather than relying on separate systems for vision, speech, and language, modern multimodal LLMs unify all inputs into a single representation and reasoning pipeline. This design significantly simplifies system architecture while expanding capability.
By operating in a shared embedding space and using a single transformer-based reasoning core, multimodal LLMs move closer to general-purpose AI systems that can perceive, understand, and reason about the world in a human-like, integrated manner.
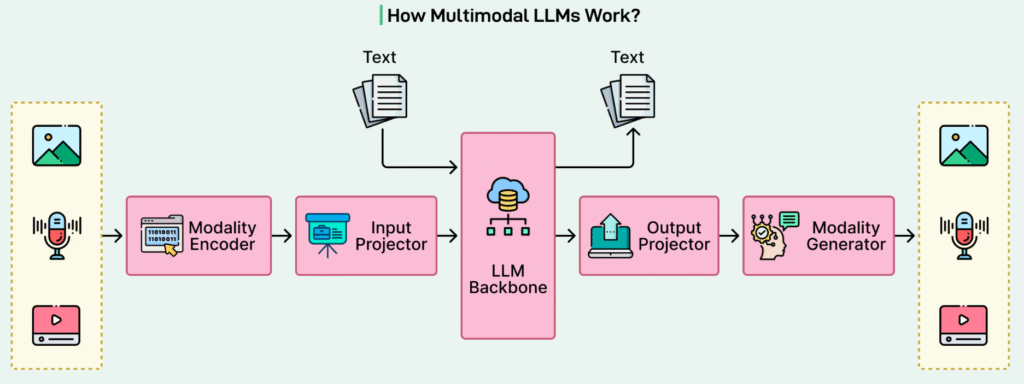
Conclusion
Multimodal LLMs unify text, vision, audio, and video by projecting all inputs into a shared embedding space and reasoning over them with a single transformer-based language model. This architecture removes modality boundaries and enables consistent cross-modal understanding.
By decoupling perception (encoders) from reasoning (the language model), multimodal LLMs offer a scalable and extensible foundation for building general-purpose AI systems capable of richer, more integrated world understanding.