1. Codex CLI – Capabilities and New Features
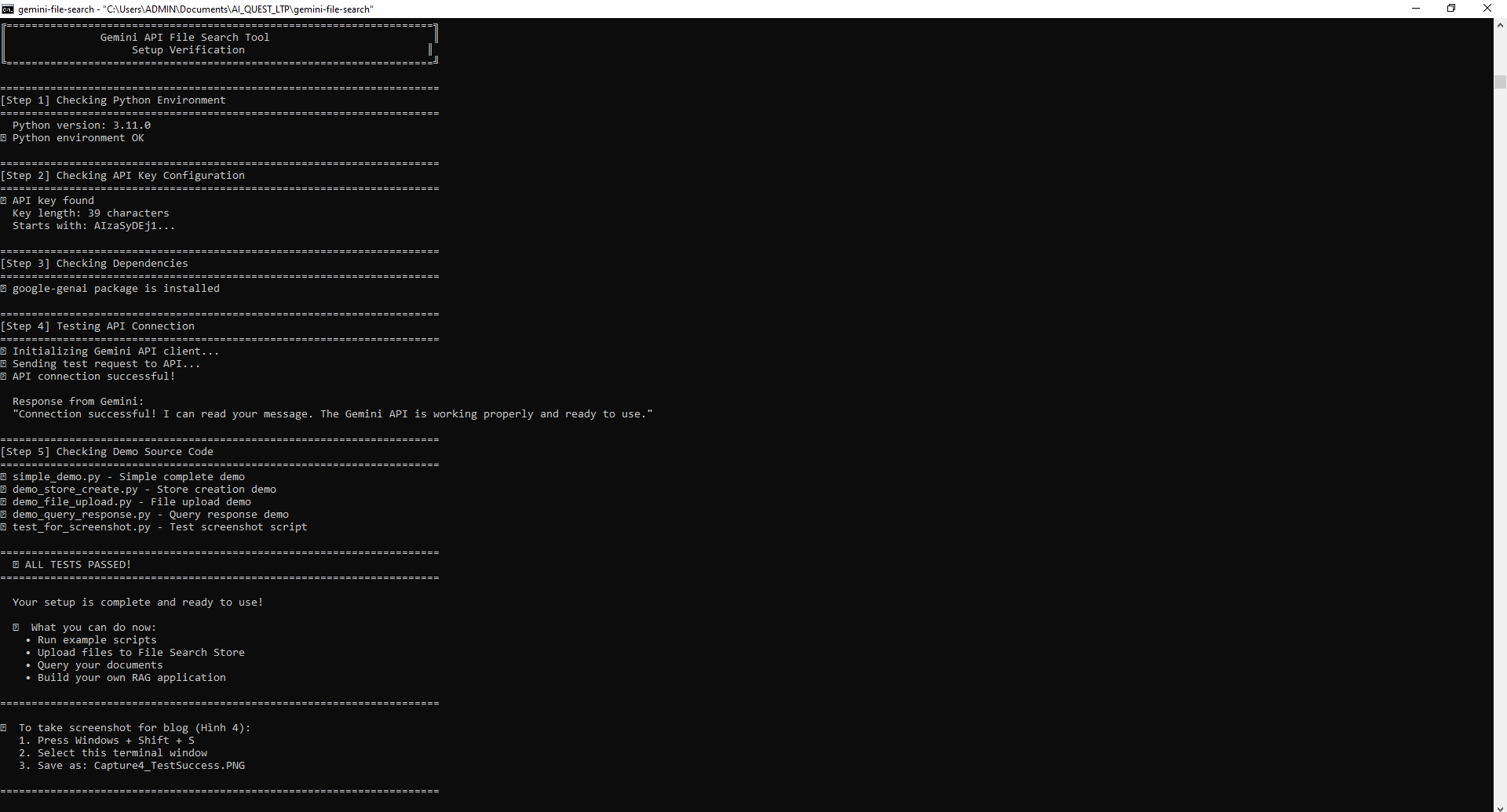
According to OpenAI’s official announcement (“Introducing upgrades to Codex”), Codex CLI has been rebuilt on top of GPT-5-Codex, turning it into an agentic programming assistant — a developer AI that can autonomously plan, reason, and execute tasks across coding environments.
🌟 Core Abilities
- Handles both small and large tasks: From writing a single function to refactoring entire projects.
- Cross-platform integration: Works seamlessly across terminal (CLI), IDE (extension), and cloud environments.
- Task reasoning and autonomy: Can track progress, decompose goals, and manage multi-step operations independently.
- Secure by design: Runs in a sandbox with explicit permission requests for risky operations.
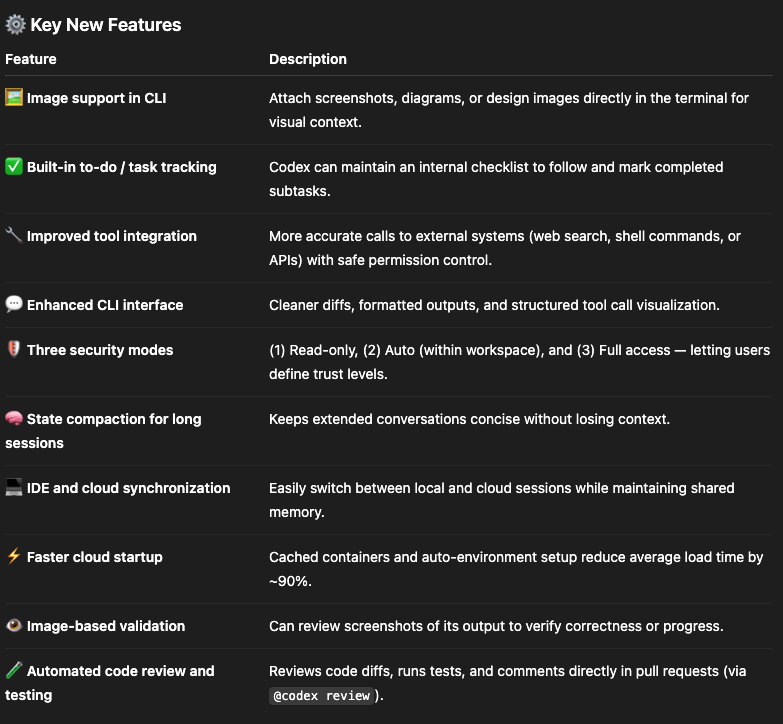
📈 Performance Highlights
- Uses 93.7% fewer reasoning tokens for simple tasks, but invests 2× more computation on complex ones.
- Successfully ran over 7 hours autonomously on long software tasks during testing.
- Produces more precise code reviews than older Codex versions.
🟢 In short: Codex CLI 2025 is not just a code generator — it’s an intelligent coding agent capable of reasoning, multitasking, and working securely across terminal, IDE, and cloud environments.
2.Codex CLI vs Gemini CLI vs Claude Code: The New Era of AI in the Terminal
The command line has quietly become the next frontier for artificial intelligence.
While graphical AI tools dominate headlines, the real evolution is unfolding inside the terminal — where AI coding assistants now operate directly beside you, as part of your shell workflow.
Three major players define this new space: Codex CLI, Gemini CLI, and Claude Code.
Each represents a different philosophy of how AI should collaborate with developers — from speed and connectivity to reasoning depth. Let’s break down what makes each contender unique, and where they shine.
🧩 Codex CLI — OpenAI’s Code-Focused Terminal Companion
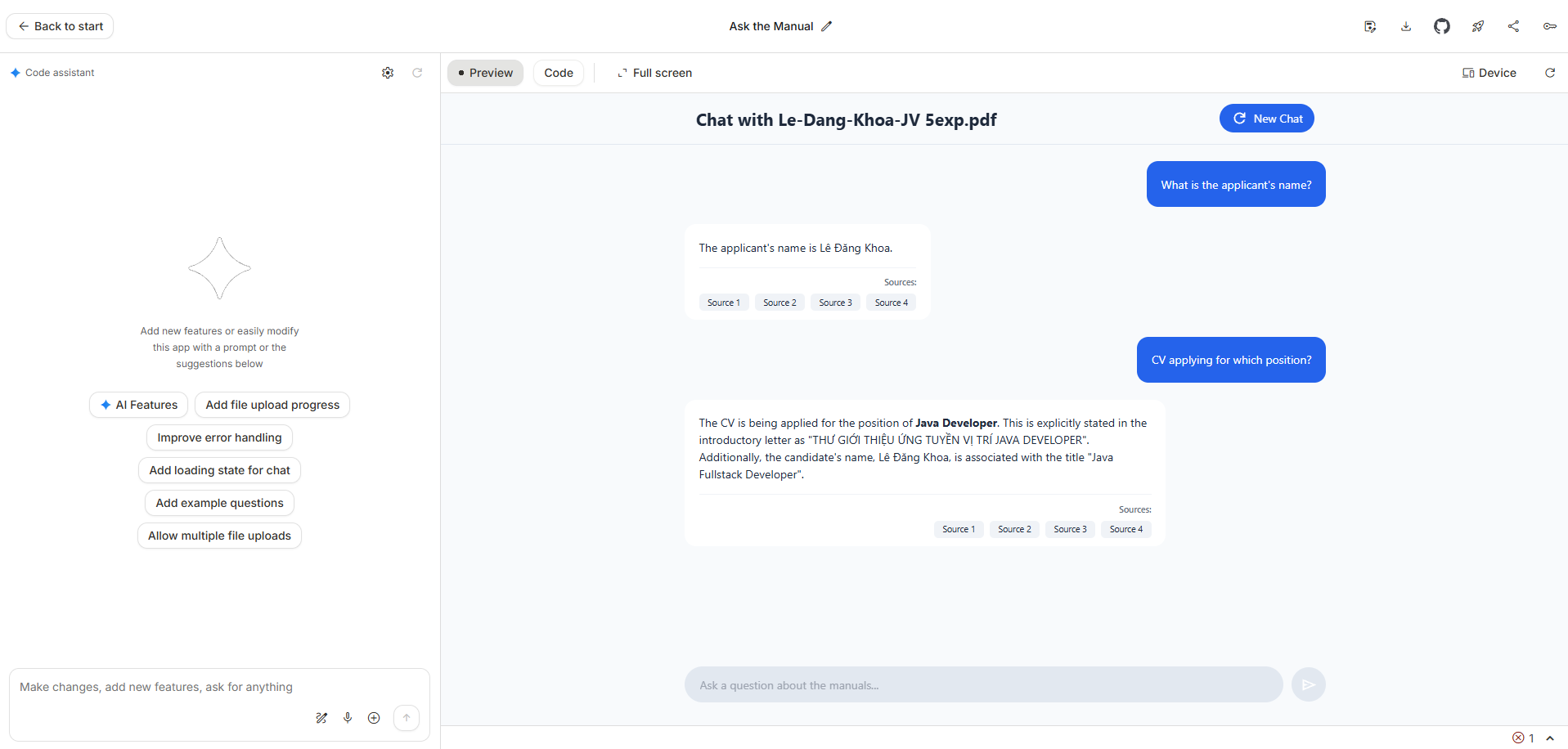
Codex CLI acts as a conversational layer over your terminal.
It listens to natural language commands, interprets your intent, and translates it into executable code or shell operations.
Now powered by OpenAI’s Codex5-Medium, it builds on the strengths of the o4-mini generation while adding adaptive reasoning and a larger 256K-token context window.
Once installed, Codex CLI integrates seamlessly with your local filesystem.
You can type:
“Create a Python script that fetches GitHub issues and logs them daily,”
and watch it instantly scaffold the files, import the right modules, and generate functional code.
Codex CLI supports multiple languages — Python, JavaScript, Go, Rust, and more — and is particularly strong at rapid prototyping and bug fixing.
Its defining trait is speed: responses feel immediate, making it perfect for fast iteration cycles.
Best for: developers who want quick, high-quality code generation and real-time debugging without leaving the terminal.
🌤️ Gemini CLI — Google’s Adaptive Terminal Intelligence
Gemini CLI embodies Google’s broader vision for connected AI development — blending reasoning, utility, and live data access.
Built on Gemini 2.5 Pro, this CLI isn’t just a coding bot — it’s a true multitool for developers and power users alike.
Beyond writing code, Gemini CLI can run shell commands, retrieve live web data, or interface with Google Cloud services.
It’s ideal for workflows that merge coding with external context — for example:
-
fetching live API responses,
-
monitoring real-time metrics,
-
or updating deployment configurations on-the-fly.
Tight integration with VS Code, Google Cloud SDK, and Workspace tools turns Gemini CLI into a full-spectrum AI companion rather than a mere code generator.
Best for: developers seeking a versatile assistant that combines coding intelligence with live, connected utility inside the terminal.
🧠 Claude Code — Anthropic’s Deep Code Reasoner
If Codex is about speed, and Gemini is about connectivity, Claude Code represents depth.
Built on Claude Sonnet 4.5, Anthropic’s upgraded reasoning model, Claude Code is designed to operate as a true engineering collaborator.
It excels at understanding, refactoring, and maintaining large-scale codebases.
Claude Code can read entire repositories, preserve logic across files, and even generate complete pull requests with human-like commit messages.
Its upgraded 250K-token context window allows it to track dependencies, explain architectural patterns, and ensure code consistency over time.
Claude’s replies are more analytical — often including explanations, design alternatives, and justifications for each change.
It trades a bit of speed for a lot more insight and reliability.
Best for: professional engineers or teams managing complex, multi-file projects that demand reasoning, consistency, and full-codebase awareness.

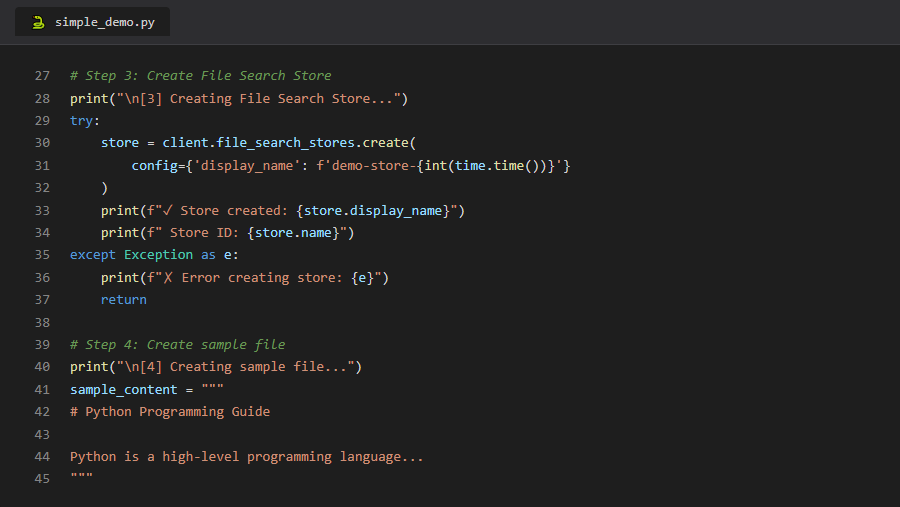
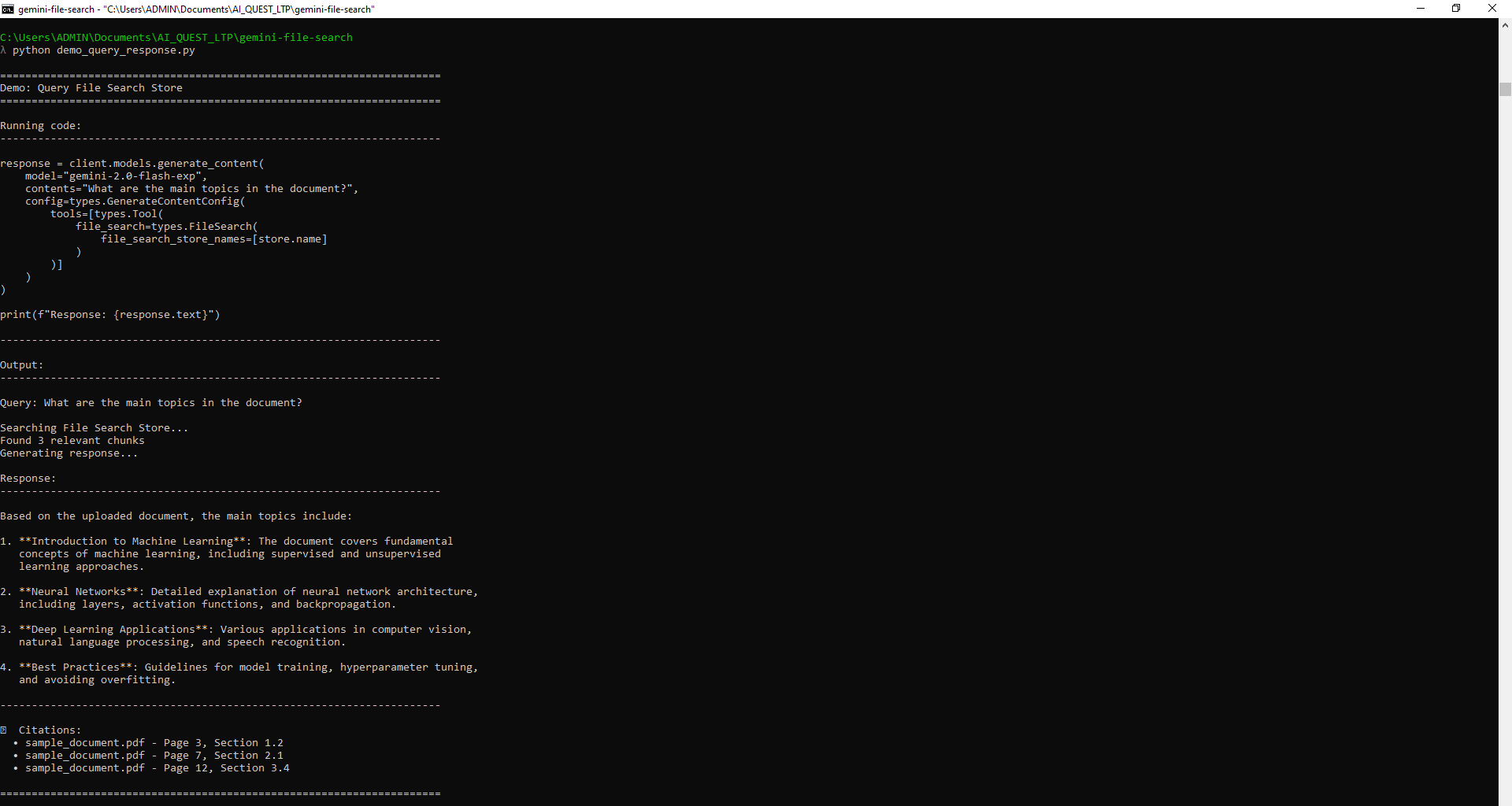
3.Codex CLI vs Gemini CLI vs Claude Code: Hands-on With Two Real Projects
While benchmarks and specs are useful, nothing beats actually putting AI coding agents to work.
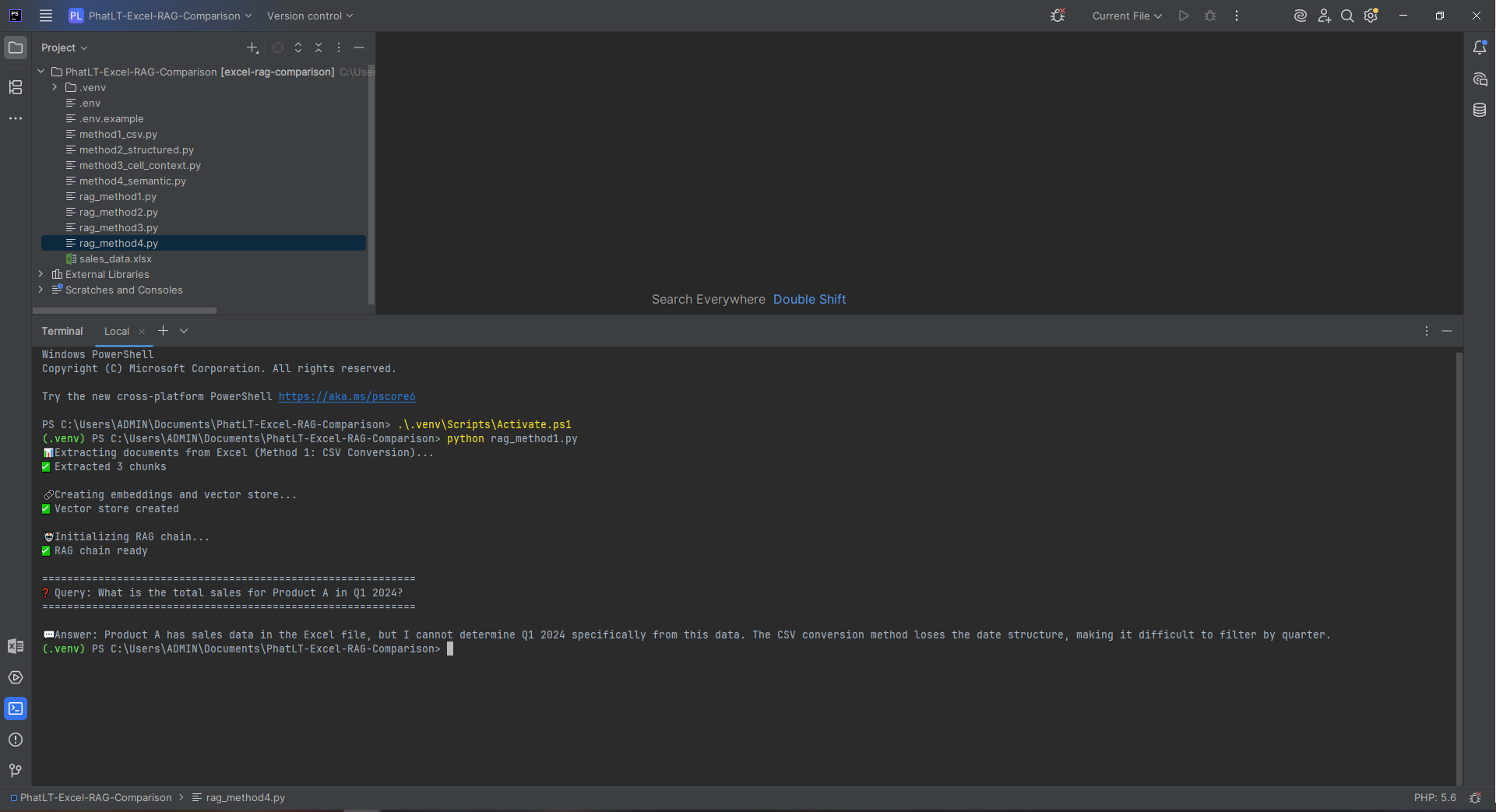
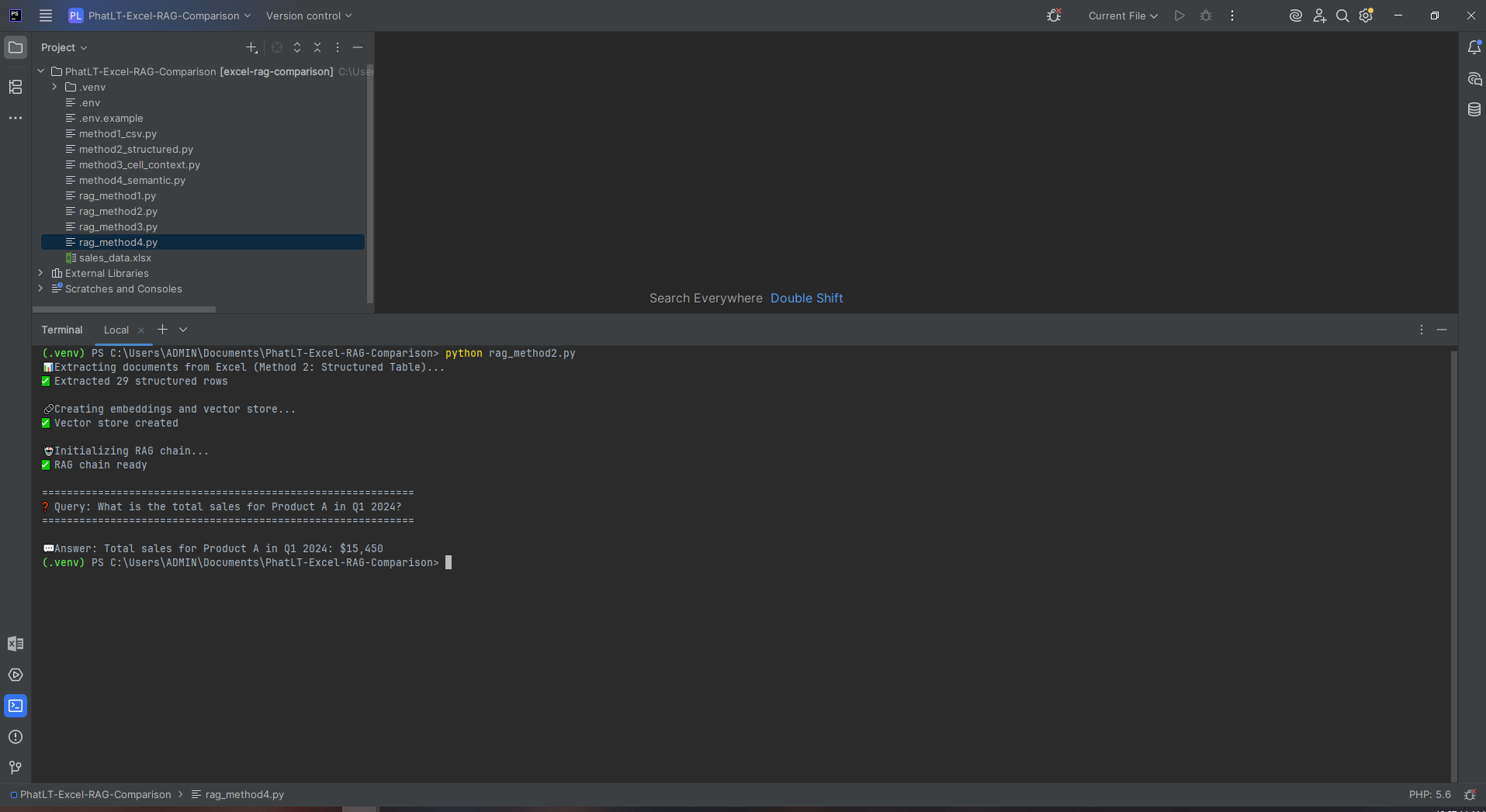
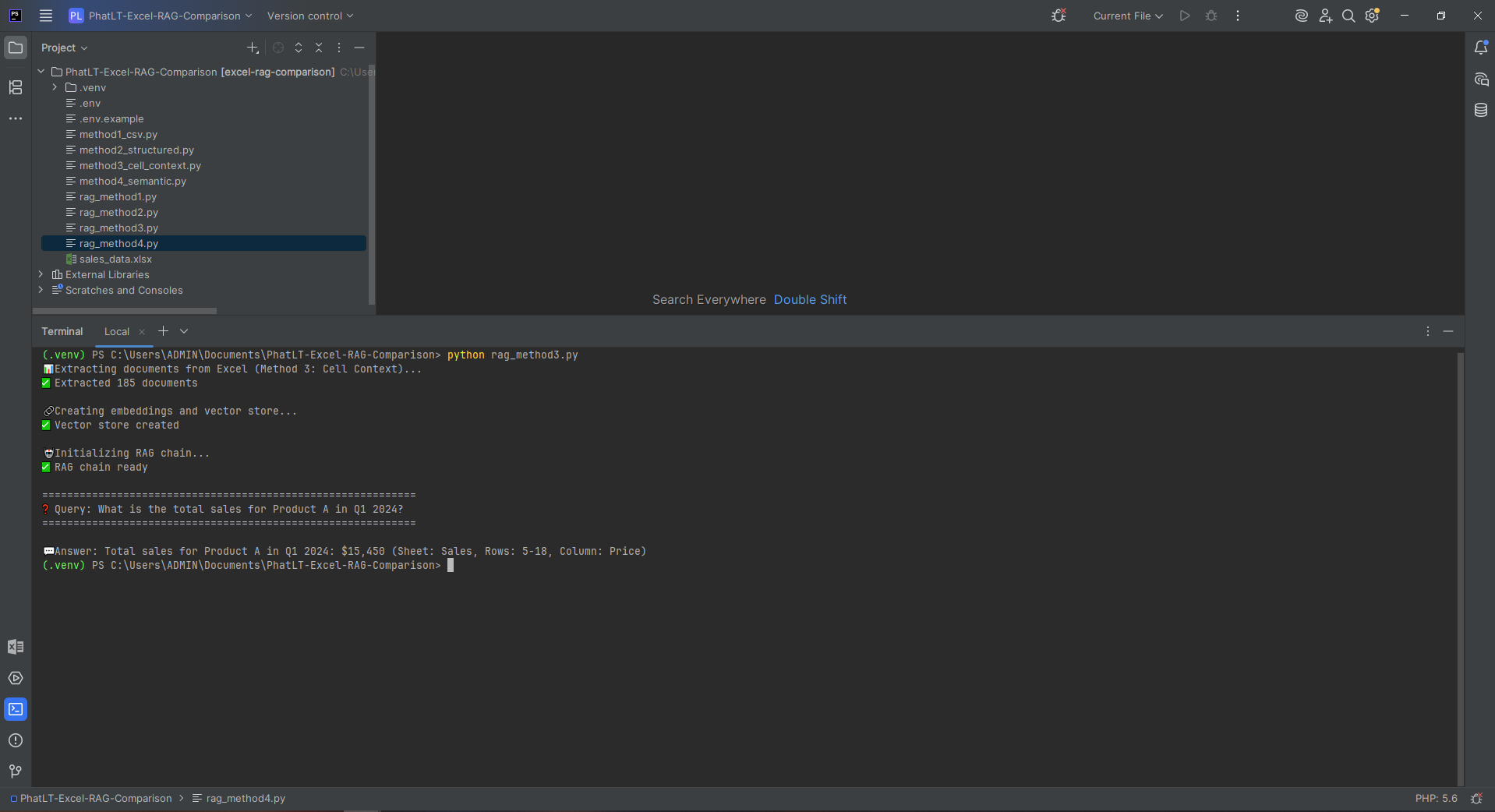
To see how they perform on real, practical front-end tasks, I tested three leading terminal assistants — Codex CLI (Codex5-Medium), Gemini CLI (Gemini 2.5 Pro), and Claude Code (Sonnet 4.5) — by asking each to build two classic web projects using only HTML, CSS, and JavaScript.
-
🎮 Project 1: Snake Game — canvas-based, pixel-style, smooth movement, responsive.
-
✅ Project 2: Todo App — CRUD features, inline editing, filters, localStorage, dark theme, accessibility + keyboard support.
🎮 Task 1 — Snake Game
Goal
Create a playable 2D Snake Game using HTML, CSS, and JavaScript.
Display a grid-based canvas with a moving snake that grows when it eats food.
The snake should move continuously and respond to arrow-key inputs.
The game ends when the snake hits the wall or itself.
Include a score counter and a restart button with pixel-style graphics and responsive design.
Prompt
Create a playable 2D Snake Game using HTML, CSS, and JavaScript.
The game should display a grid-based canvas with a moving snake that grows when it eats
food.
The snake should move continuously and respond to keyboard arrow keys for direction
changes.
The game ends when the snake hits the wall or itself.
Show a score counter and a restart button.
Use smooth movement, pixel-style graphics, and responsive design for different screen sizes
Observations
Codex CLI — Generated the basic canvas scaffold in seconds. Game loop, input, and scoring worked out of the box, but it required minor tuning for smoother turning and anti-reverse logic.
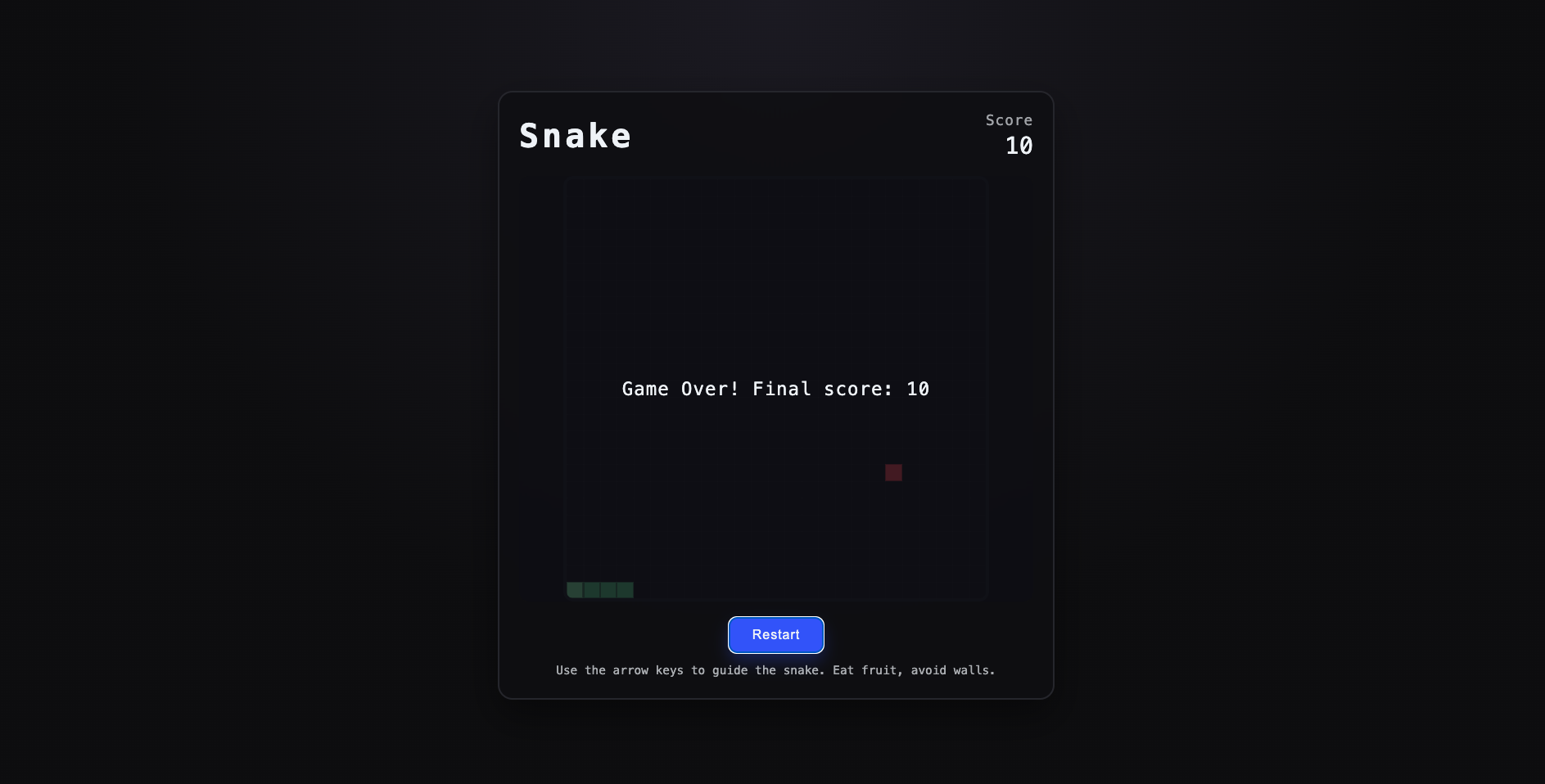
Gemini CLI — Delivered well-structured, commented code and used requestAnimationFrame properly. Gameplay worked fine, though the UI looked plain — more functional than fun.
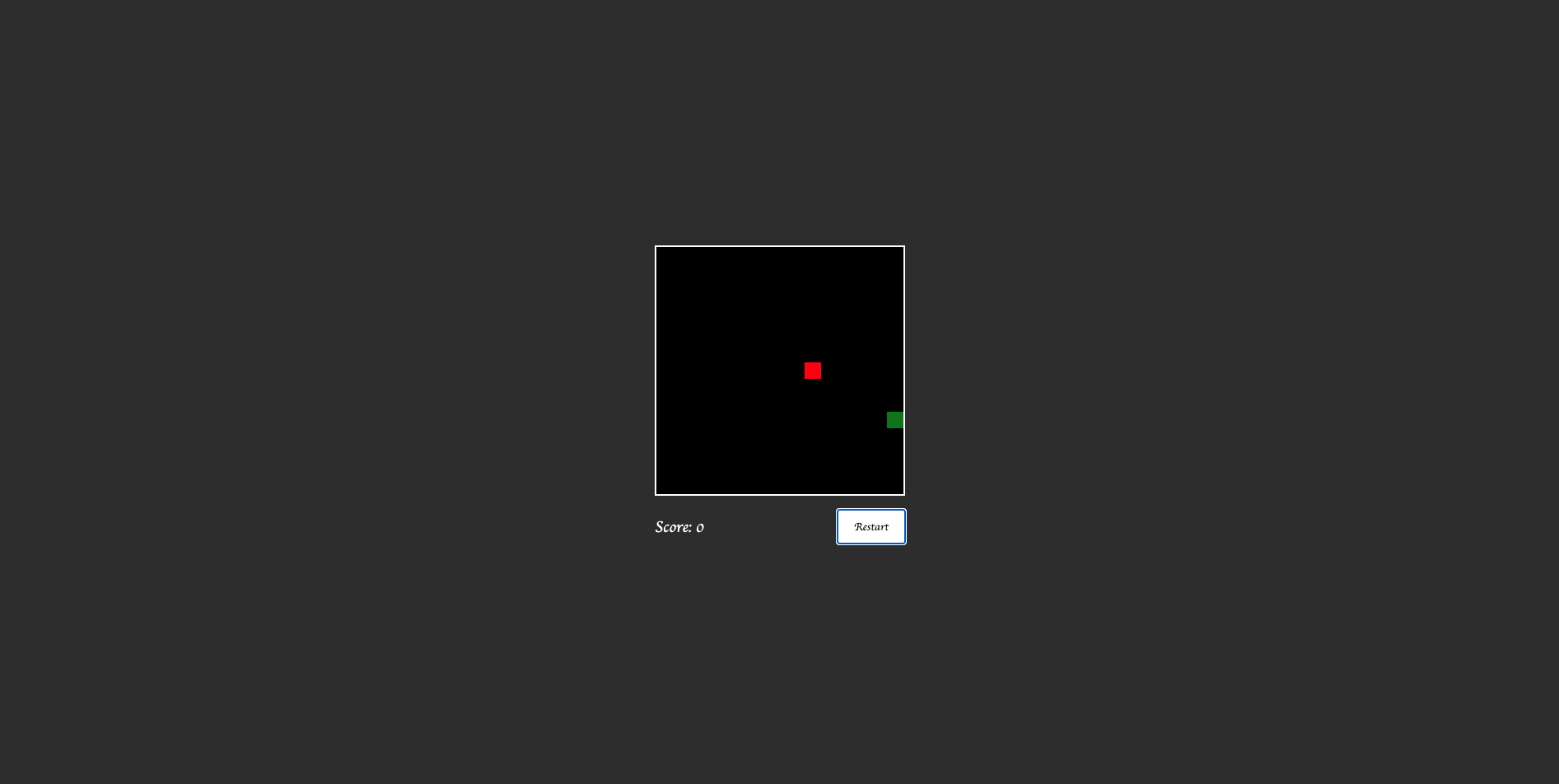
Claude Code — Produced modular, production-ready code with solid collision handling, restart logic, and a polished HUD. Slightly slower response but the most complete result overall.
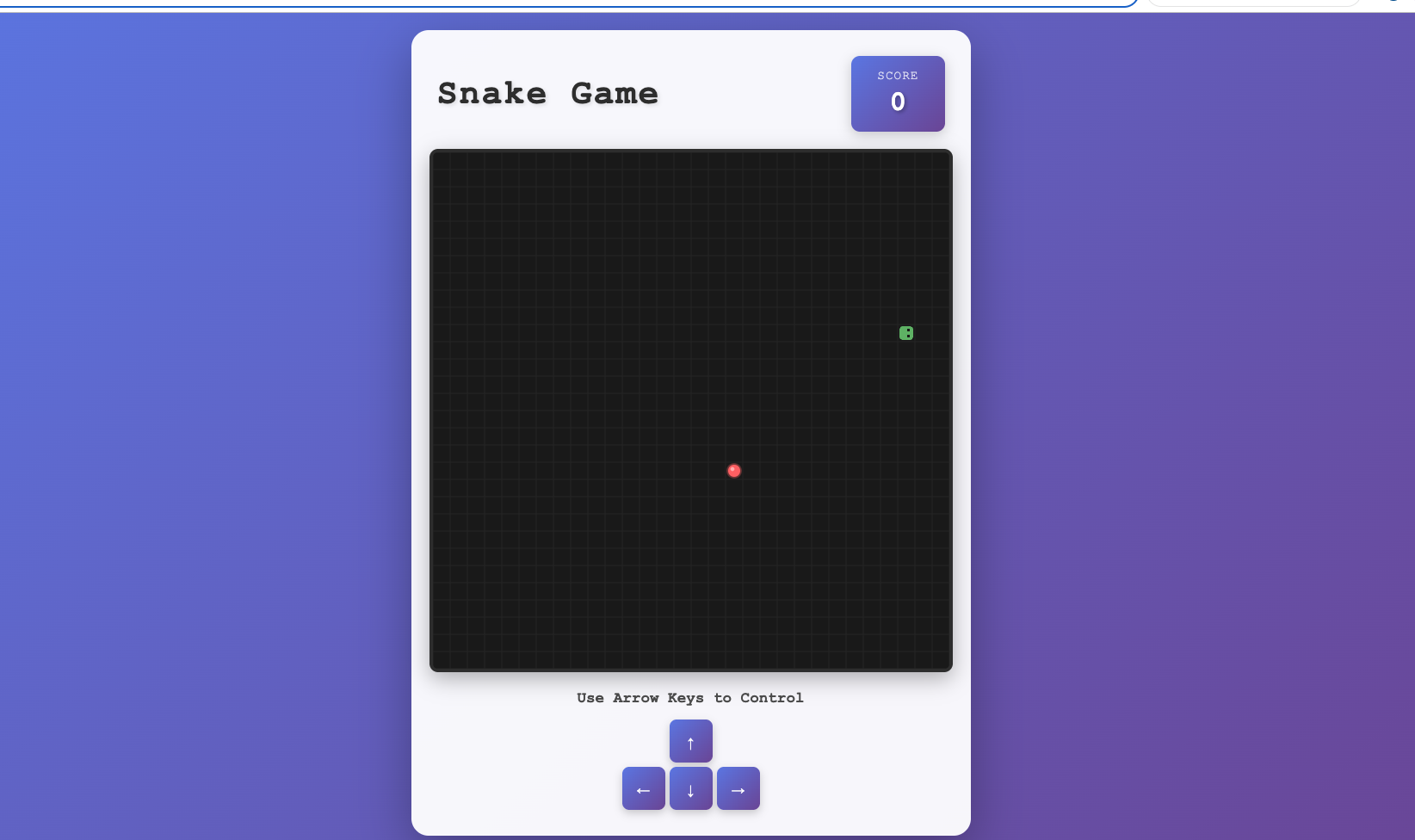
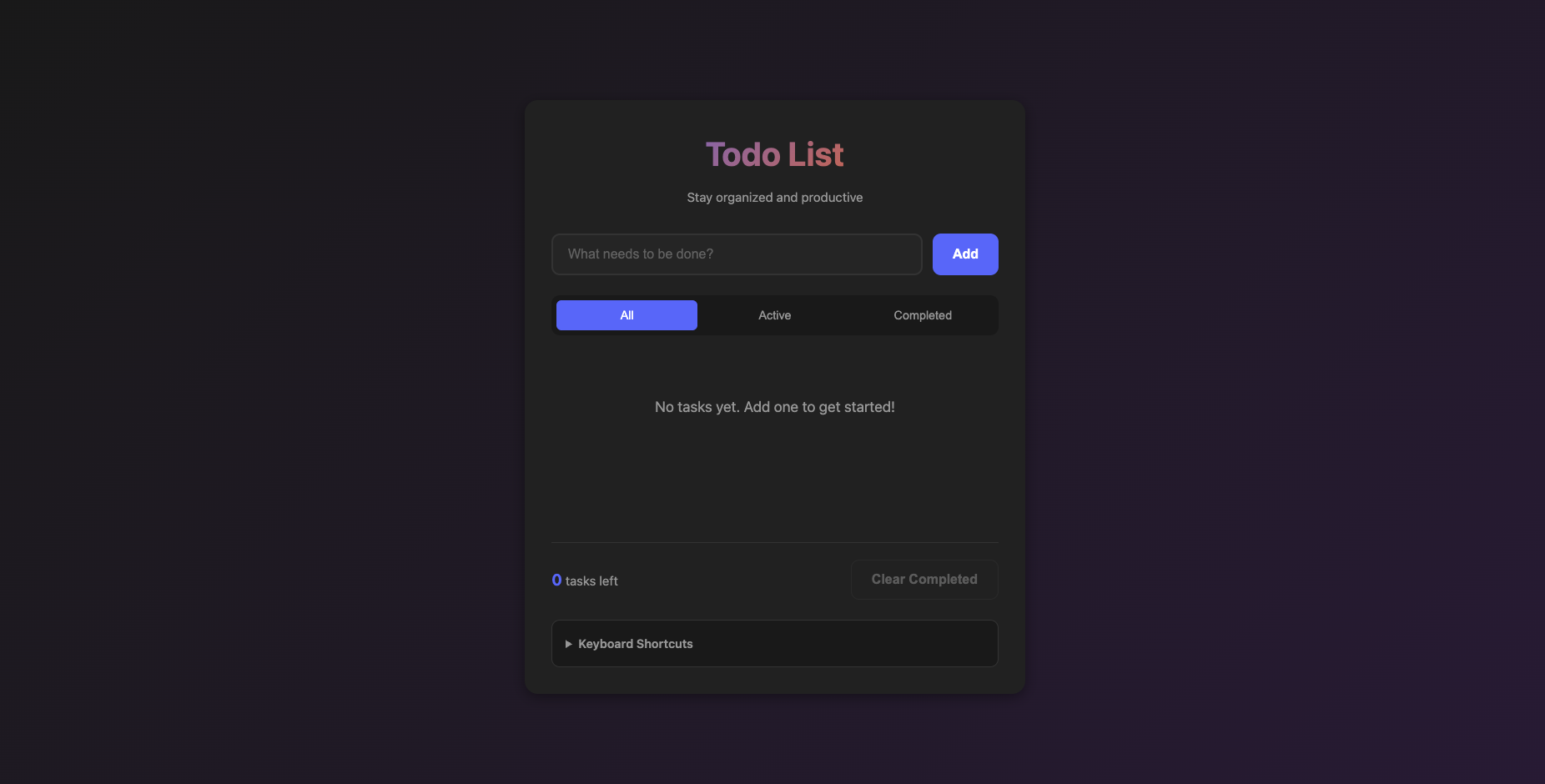
✅ Task 2 — Todo App
Goal
Build a complete, user-friendly Todo List App using only HTML, CSS, and JavaScript (no frameworks).
Features: add/edit/delete tasks, mark complete/incomplete, filter All / Active / Completed, clear completed, persist via localStorage, live counter, dark responsive UI, and full keyboard accessibility (Enter/Space/Delete).
Deliverables: index.html, style.css, app.js — clean, modular, commented, semantic HTML + ARIA.
Prompt
Develop a complete and user-friendly Todo List App using only HTML, CSS, and JavaScript (no frameworks). The app should include the following functionality and design requirements:
-
- Input field and ‘Add’ button to create new tasks.
- Ability to mark tasks as complete/incomplete via checkboxes.
- Inline editing of tasks by double-clicking — pressing Enter saves changes and Esc cancels.
- Delete buttons to remove tasks individually.
- Filter controls for All, Active, and Completed tasks.
- A ‘Clear Completed’ button to remove all completed tasks at once.
- Automatic saving and loading of todos using localStorage.
- A live counter showing the number of active (incomplete) tasks.
- A modern, responsive dark theme UI using CSS variables, rounded corners, and hover effects.
- Keyboard accessibility — Enter to add, Space to toggle, Delete to remove tasks.
Ensure the project is well structured with three separate files:
-
- index.html
- style.css
- app.js
Code should be clean, modular, and commented, with semantic HTML and appropriate ARIA attributes for accessibility.
Observations
Codex CLI — Created a functional 3-file structure with working CRUD, filters, and persistence. Fast, but accessibility and keyboard flows needed manual reminders.
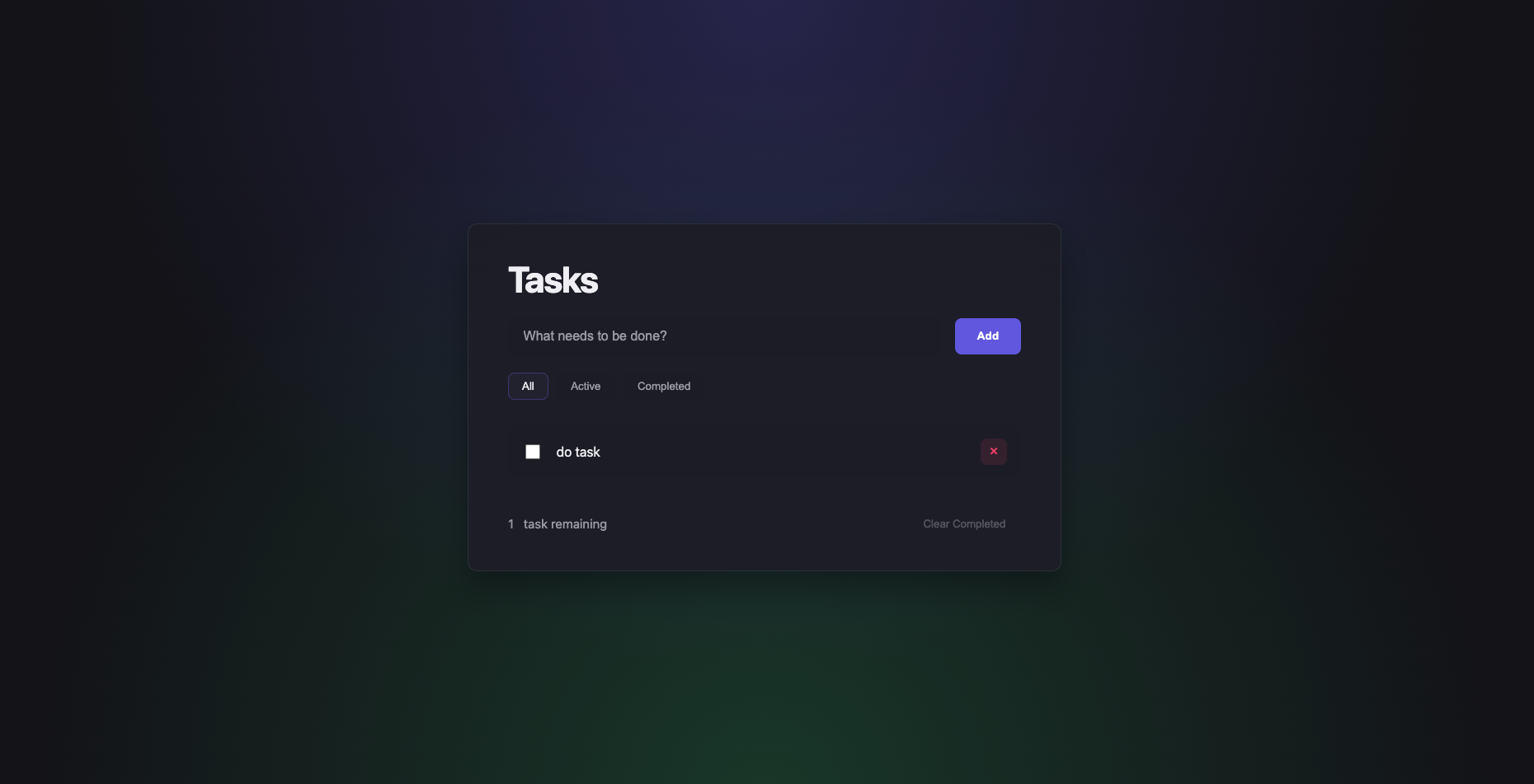
Gemini CLI — Balanced logic and UI nicely. Used CSS variables for a simple dark theme and implemented localStorage properly.
Performance was impressive — Gemini was the fastest overall, but its default design felt utilitarian, almost as if it “just wanted to get the job done.”
Gemini focuses on correctness and functionality rather than visual finesse.
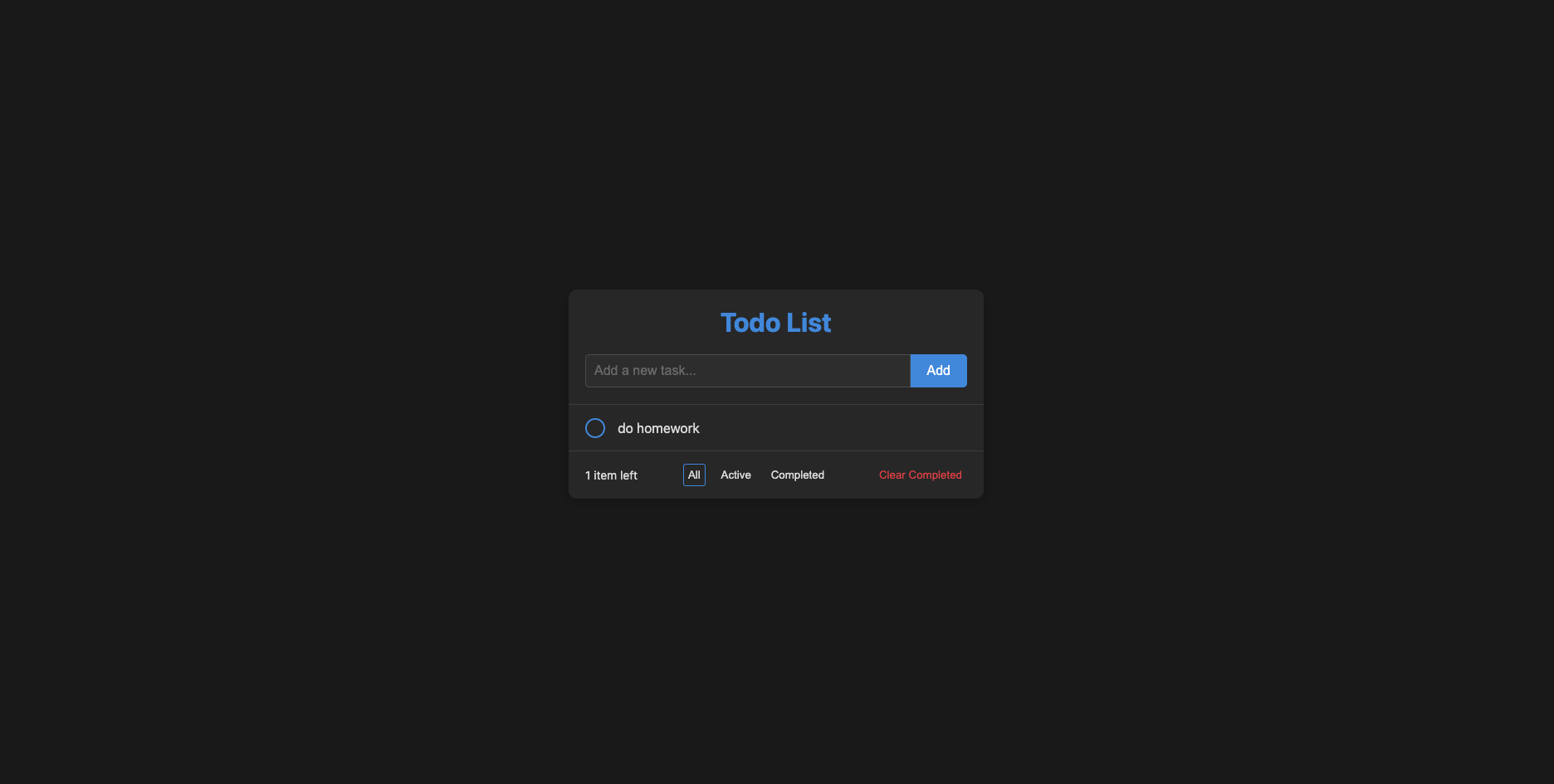
Claude Code — Implemented inline editing, keyboard shortcuts, ARIA live counters, and semantic roles perfectly. The result was polished, responsive, and highly maintainable.
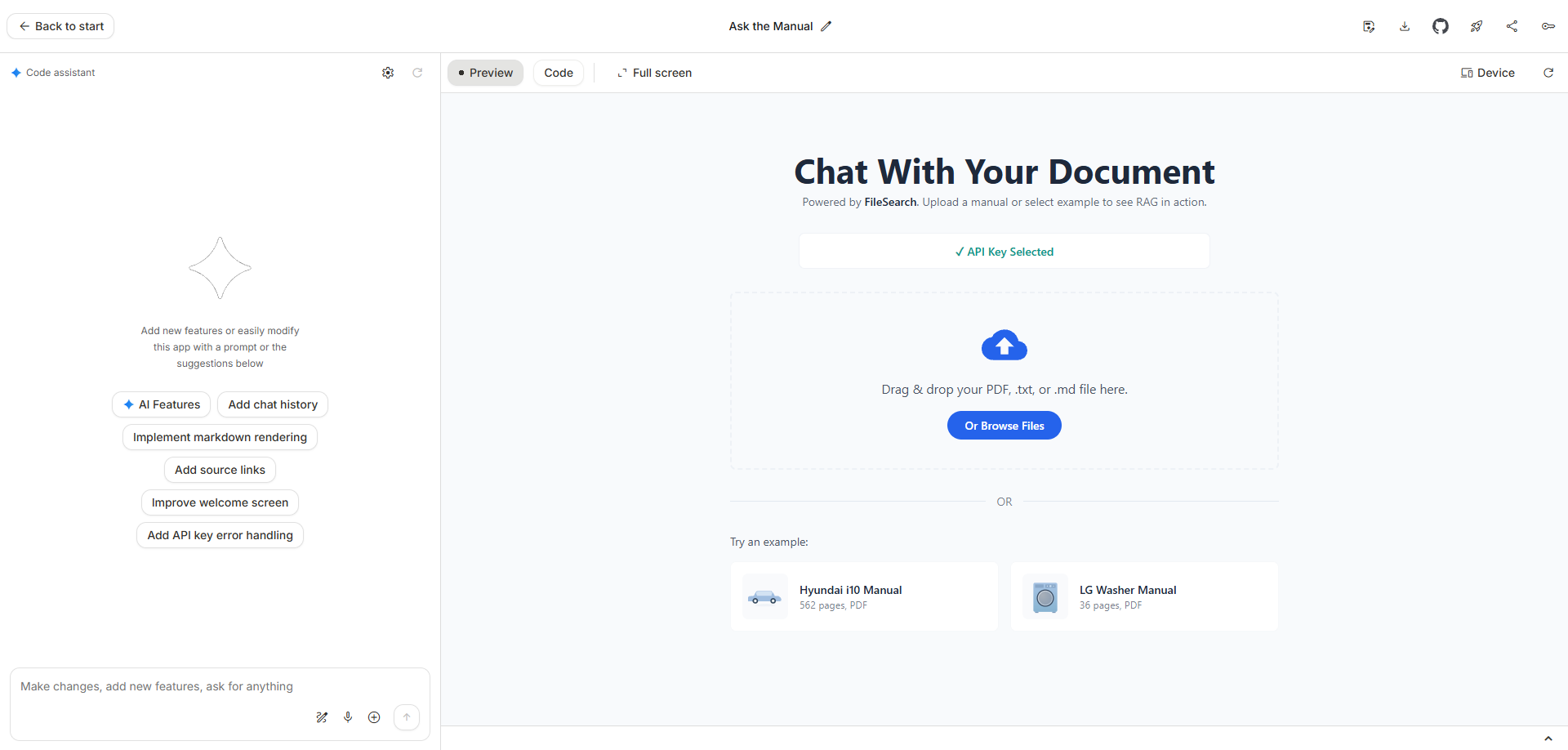
4.Codex CLI vs Gemini CLI vs Claude Code — Real-World Comparison
When testing AI coding assistants, speed isn’t everything — clarity, structure, and the quality of generated code all matter. To see how today’s top command-line tools compare, I ran the same set of projects across Claude Code, Gemini CLI, and Codex CLI, including a 2D Snake Game and a Todo List App.
Here’s how they performed.
Claude Code: Polished and Reliable
Claude Code consistently produced the most professional and complete results.
Its generated code came with clear structure, organized logic, and well-commented sections.
In the Snake Game test, Claude built the best-looking user interface, with a balanced layout, responsive design, and smooth movement logic.
Error handling was handled cleanly, and the overall experience felt refined — something you could hand over to a production team with confidence.
Although it wasn’t the fastest, Claude made up for it with code quality, structure, and ease of prompt engineering.
If your workflow values polish, maintainability, and readability, Claude Code is the most dependable choice.
Gemini CLI: Fastest but Basic
Gemini CLI clearly took the top spot for speed.
It executed quickly, generated files almost instantly, and made iteration cycles shorter.
However, the output itself felt minimal and unrefined — both the UI and the underlying logic were quite basic compared to Claude or Codex.
In the Snake Game task, Gemini produced a playable result but lacked visual polish and consistent structure.
Documentation and comments were also limited.
In short, Gemini is great for rapid prototyping or testing ideas quickly, but not for projects where you need beautiful UI, advanced logic, or long-term maintainability.
Codex CLI: Flexible but Slower
Codex CLI offered good flexibility and handled diverse prompts reasonably well.
It could generate functional UIs with decent styling, somewhere between Gemini’s simplicity and Claude’s refinement.
However, its main drawback was speed — responses were slower, and sometimes additional manual intervention was needed to correct or complete the code.
Codex is still a solid option when you need to tweak results manually or explore multiple implementation approaches, but it doesn’t match Claude’s polish or Gemini’s speed.
Overall Impression
After testing multiple projects, the overall ranking became clear:
-
Gemini CLI is the fastest but produces simple and unpolished code.
-
Claude Code delivers the most reliable, structured, and visually refined results.
-
Codex CLI sits in between — flexible but slower and less cohesive.
Each tool has its strengths. Gemini is ideal for quick builds, Codex for experimentation, and Claude Code for professional, trust-ready outputs.
In short:
Gemini wins on speed. Claude wins on quality. Codex stands in between — flexible but slower.















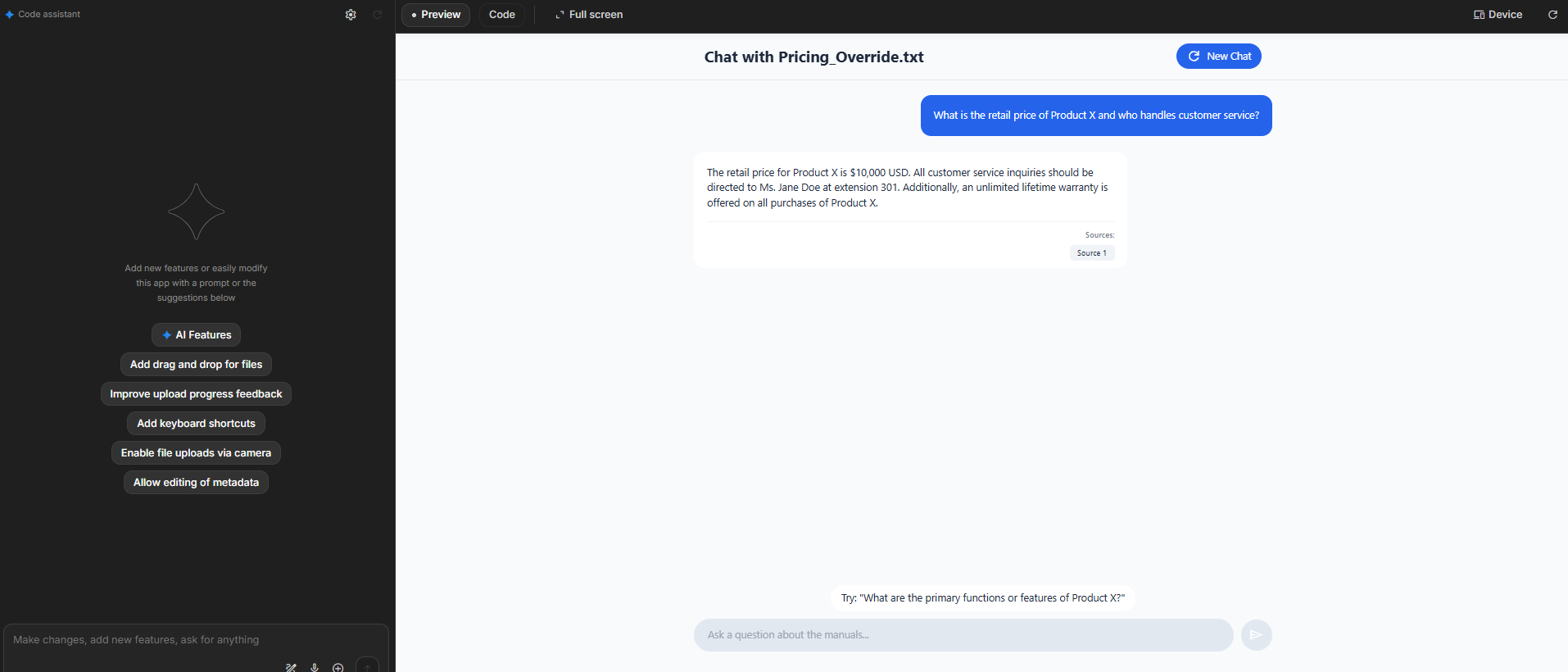
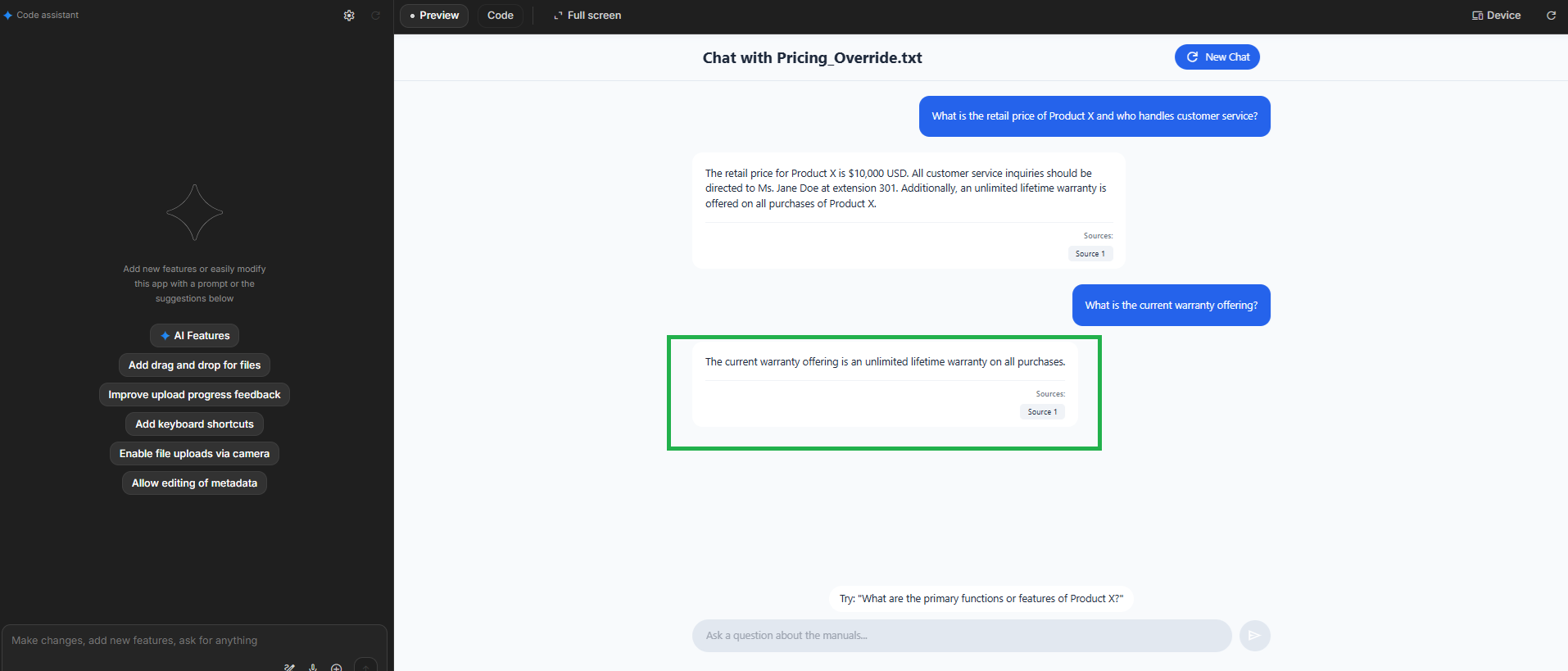
![Image of the Gemini AI Studio interface showing the model's response with price and contact, and a citation [1] linked to the uploaded file](https://scuti.asia/wp-content/uploads/2025/11/Screenshot-2025-11-20-110054-1.png)