Many organizations have already succeeded in launching generative AI pilots. The real challenge begins afterward: how to turn a successful proof-of-concept into a stable production system.
This article explores the key ideas behind building production-ready generative AI applications on AWS, with a focus on Retrieval-Augmented Generation (RAG) architectures and scalable infrastructure.
Why Production Readiness Matters
Early GenAI prototypes often prioritize speed and experimentation. However, once real users start depending on the system, new requirements appear:
- Scalability – infrastructure must handle growing traffic while maintaining fast response times.
- Cost efficiency – designs that are acceptable during pilots may become expensive at production scale.
- Security & privacy – preventing data exposure and reducing new attack surfaces introduced by LLM systems.
- Multi-tenancy – supporting different users or organizations with isolated data contexts.
- Operations – observability, continuous deployment, and reliability are essential after launch.
The transition from pilot to production is not only a technical upgrade — it is an operational and architectural shift.
The Challenge of Probabilistic Systems
Unlike traditional software, LLMs are probabilistic. The same input can generate slightly different outputs each time. Because of this:
- Monitoring and evaluation become critical
- Output quality must be tested continuously
- Traceability and observability are necessary for production reliability
This changes how teams think about testing and quality assurance.
A Typical Production GenAI Stack
A production-ready architecture usually includes:
- User-facing application layer (often containerized services)
- Model inference layer optimized for ML workloads
- Vector storage for RAG-based context retrieval
- Data pipelines for ingestion and embedding generation
In other words, production GenAI systems are ecosystems rather than single models.
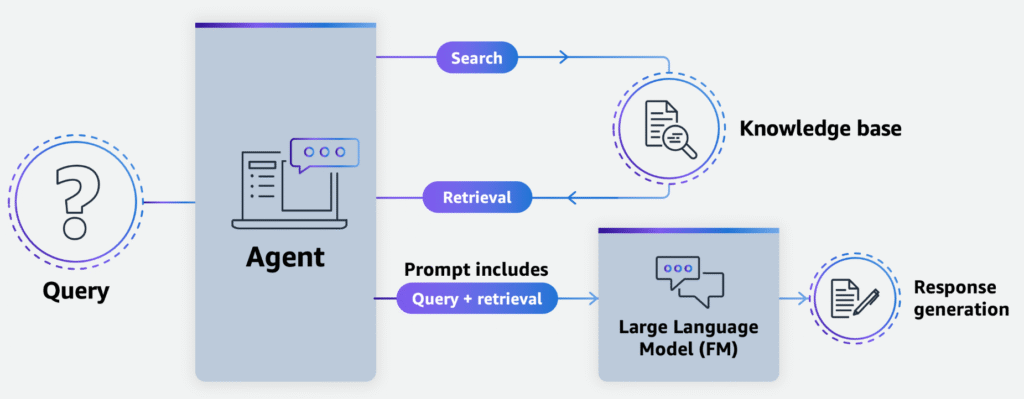
AWS Approach: Bedrock + Vector Database
The article highlights a common architecture combining:
- Amazon Bedrock for model hosting, inference, fine-tuning tools, and managed AI operations.
- Pinecone vector database for low-latency similarity search and scalable RAG data storage.
Key advantages mentioned:
- Managed infrastructure reduces operational overhead
- Fast vector retrieval suitable for interactive applications
- Built-in governance, monitoring, and security features
- Easy integration via Bedrock Knowledge Bases (data ingestion + retrieval automation)
This design helps teams move faster without building complex pipelines manually.
Production-Ready Means More Than Just Models
A strong takeaway from the article is that production readiness is mostly about system design — not model choice.
Important focus areas include:
- Response latency and user experience
- Observability and monitoring
- Security compliance (SOC2, HIPAA, etc.)
- Automated data ingestion and updates
- Cost control at scale
The model is only one component in a much larger system.
Key Lesson for Builders
The biggest insight is simple:
A successful GenAI pilot proves the idea — but production success requires engineering discipline.
Organizations moving to production should think in terms of:
- Architecture scalability
- Operational maturity
- Data governance
- Reliable RAG pipelines
Tools like Amazon Bedrock and managed vector databases help reduce complexity, allowing teams to focus more on business value rather than infrastructure management.
My Personal Takeaway
Generative AI adoption is quickly shifting from experimentation to real business applications. The teams that succeed are not just those with the best prompts or models — but those who design systems that scale reliably, securely, and economically.
Production-ready GenAI is ultimately about engineering maturity, not just AI innovation.