🚀 DeepSeek-OCR — Reinventing OCR Through Visual Compression
DeepSeek-OCR is a next-generation Optical Character Recognition system that introduces a revolutionary approach:
it compresses long textual contexts into compact image tokens and then decodes them back into text — achieving up to 10× compression while maintaining near-lossless accuracy.

⚙️ Key Features of DeepSeek-OCR
1. Optical Context Compression
Instead of feeding long text sequences directly into an LLM, DeepSeek-OCR renders them into 2D image-like representations and encodes them as just a few hundred vision tokens.
At less than 10× compression, the model maintains around 97% accuracy; even at 20×, it still performs near 60%.
2. Two-Stage Architecture
-
DeepEncoder – a high-resolution vision encoder optimized for dense text and layout structures while keeping token counts low.
-
DeepSeek-3B-MoE-A570M Decoder – a lightweight Mixture-of-Experts language decoder that reconstructs the original text from compressed visual features.
3. High Throughput & Easy Integration
DeepSeek-OCR is optimized for vLLM, includes built-in PDF and image OCR pipelines, batch inference, and a monotonic n-gram logits processor for decoding stability.
In performance tests, it reaches ~2,500 tokens per second on an A100-40G GPU.
4. Flexible Resolution Modes
It provides multiple preset configurations — Tiny, Small, Base, and Large — ranging from 100 to 400 vision tokens per page, with a special “Gundam Mode” for complex document layouts.
🔍 How It Works — Core Mechanism
At its core, DeepSeek-OCR transforms textual data into high-resolution visual space.
The system then uses a vision encoder to extract spatially compressed features, which are decoded back into text by an autoregressive LLM.
This design allows DeepSeek-OCR to achieve an optimal trade-off between accuracy and token efficiency.
On OmniDocBench, DeepSeek-OCR outperforms GOT-OCR 2.0 using only 100 vision tokens per page, and surpasses MinerU 2.0 with fewer than 800 tokens per page — delivering both speed and precision.
💡 Why “Long Context → Image Tokens” Works
Written language is highly structured and visually redundant — fonts, character shapes, and layout patterns repeat frequently.
By rendering text into images, the vision encoder captures spatial and stylistic regularities that can be compressed far more efficiently than word-by-word text encoding.
In short:
-
Traditional OCR treats every word or character as a separate token.
-
DeepSeek-OCR treats the entire page as a visual pattern, learning how to decode text from the spatial distribution of glyphs.
→ That’s why it achieves 10× token compression with minimal accuracy loss.
At extreme compression (20×), fine details fade, and accuracy naturally declines.
📊 Major OCR Benchmarks
1. OmniDocBench (CVPR 2025)
A comprehensive benchmark for PDF and document parsing, covering nine real-world document types — papers, textbooks, slides, exams, financial reports, magazines, newspapers, handwritten notes, and books.
It provides:
-
End-to-end evaluations (from image → structured text: Markdown, HTML, LaTeX)
-
Task-specific evaluations: layout detection, OCR recognition, table/figure/formula parsing
-
Attribute-based analysis: rotation, color background, multi-language, complexity, etc.
👉 It fills a major gap in earlier OCR datasets by enabling fair, fine-grained comparisons between traditional pipelines and modern vision-language models.
2. FOx (Focus Anywhere)
FOx is a fine-grained, focus-aware benchmark designed to test models’ ability to read or reason within specific document regions.
It includes tasks such as:
-
Region, line, or color-guided OCR (e.g., “Read the text in the red box”)
-
Region-level translation or summarization
-
Multi-page document reasoning and cross-page OCR
It also demonstrates efficient compression — for instance, encoding a 1024×1024 document into only ~256 image tokens.
🧭 Common Evaluation Criteria for OCR Systems
| Category | What It Measures |
|---|---|
| Text Accuracy | Character/Word Error Rate (CER/WER), Edit Distance, BLEU, or structure-aware metrics (e.g., TEDS for HTML or LaTeX). |
| Layout & Structure Quality | Layout F1/mAP, table and formula structure accuracy. |
| Region-Level Precision | OCR accuracy on specific boxes, colors, or line positions (as in FOx). |
| Robustness | Stability under rotation, noise, watermarking, handwriting, or multi-language text. |
| Efficiency | Tokens per page, latency, and GPU memory footprint — where DeepSeek-OCR excels with 100–800 tokens/page and real-time decoding. |
🔗 Learn More
🔧 My Local Setup & First Results (RTX A4000)
I ran DeepSeek-OCR locally on a workstation with an NVIDIA RTX A4000 (16 GB, Ampere) using a clean Conda environment. Below is the exact setup I used and a few compatibility notes so you can reproduce it.
Hardware & OS
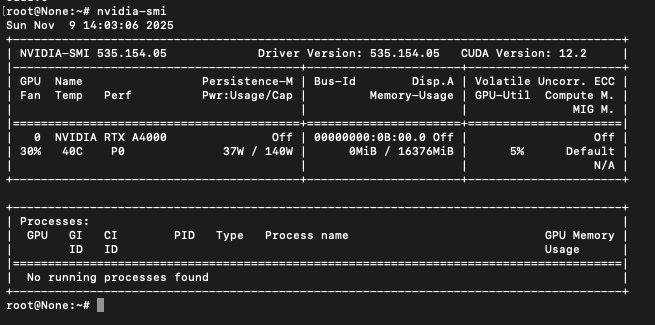
-
GPU: NVIDIA RTX A4000 (16 GB VRAM, Ampere, ~140 W TDP) — a great balance of cost, power, and inference throughput for document OCR.
-
Use case fit: Vision encoder layers (conv/attention) benefit strongly from Tensor Cores; 16 GB VRAM comfortably handles 100–400 vision tokens/page presets.
Environment (Conda + PyTorch + vLLM)
# 1) Clone
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCRconda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocr
# Tip: keep torch, torchvision, torchaudio on matching versions & CUDA build
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 \
–index-url https://download.pytorch.org/whl/cu118
# Use the official wheel file that matches your CUDA build
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
# If you’re on CUDA 11.8 and hit build errors, skip this or switch to CUDA 12.x wheels (see Gotchas)
pip install flash-attn==2.7.3 –no-build-isolation
Run the script
cd DeepSeek-OCR-hf
python run_dpsk_ocr.py
Sample outputs (3 images): I published my first three OCR attempts here:
👉 https://github.com/mhieupham1/test-deepseek-ocr/tree/main/results
I’ll keep iterating and will add token-throughput (tokens/s), per-page latency, and accuracy notes as I expand the test set on the A4000.
🧩 Review & Observations After Testing
After running several document samples through DeepSeek-OCR on the RTX A4000, I was genuinely impressed by the model’s speed, visual compression quality, and clean text decoding. It handled most printed and structured text (such as English, Japanese, and tabular data) remarkably well — even at higher compression levels.
However, during testing I also noticed a few limitations that are worth mentioning:
-
🔸 Occasional Missing Text:
In some pages, especially those with dense layouts, overlapping elements, or colored backgrounds, DeepSeek-OCR tended to drop small text fragments or subscript characters. This seems to happen when the compression ratio is too aggressive (e.g., >10×), or when the region’s text contrast is low. -
🔸 Layout Sensitivity:
Complex multi-column documents or pages with embedded tables sometimes caused partial text truncation near region boundaries. The vision encoder still captures the visual pattern but may lose context alignment at decoding time. -
🔸 Strengths in Clean Scans:
On clean, high-resolution scans (PDF exports or book pages), the OCR output was extremely stable and accurate, rivaling tools like Tesseract + layout parsers, while producing far fewer tokens. -
🔸 Performance Efficiency:
Even on a mid-range GPU like the RTX A4000 (16 GB), the model ran smoothly with ~2,000–2,500 tokens/s throughput using the Base preset. GPU memory usage remained below 12 GB, which is excellent for local inference.
In short:
DeepSeek-OCR delivers a new balance between accuracy and efficiency.
It’s not yet flawless — small-text regions can be lost under heavy compression —
but for large-scale document pipelines, the token cost reduction is game-changing.