by
Duong Nguyen
June 7, 2026
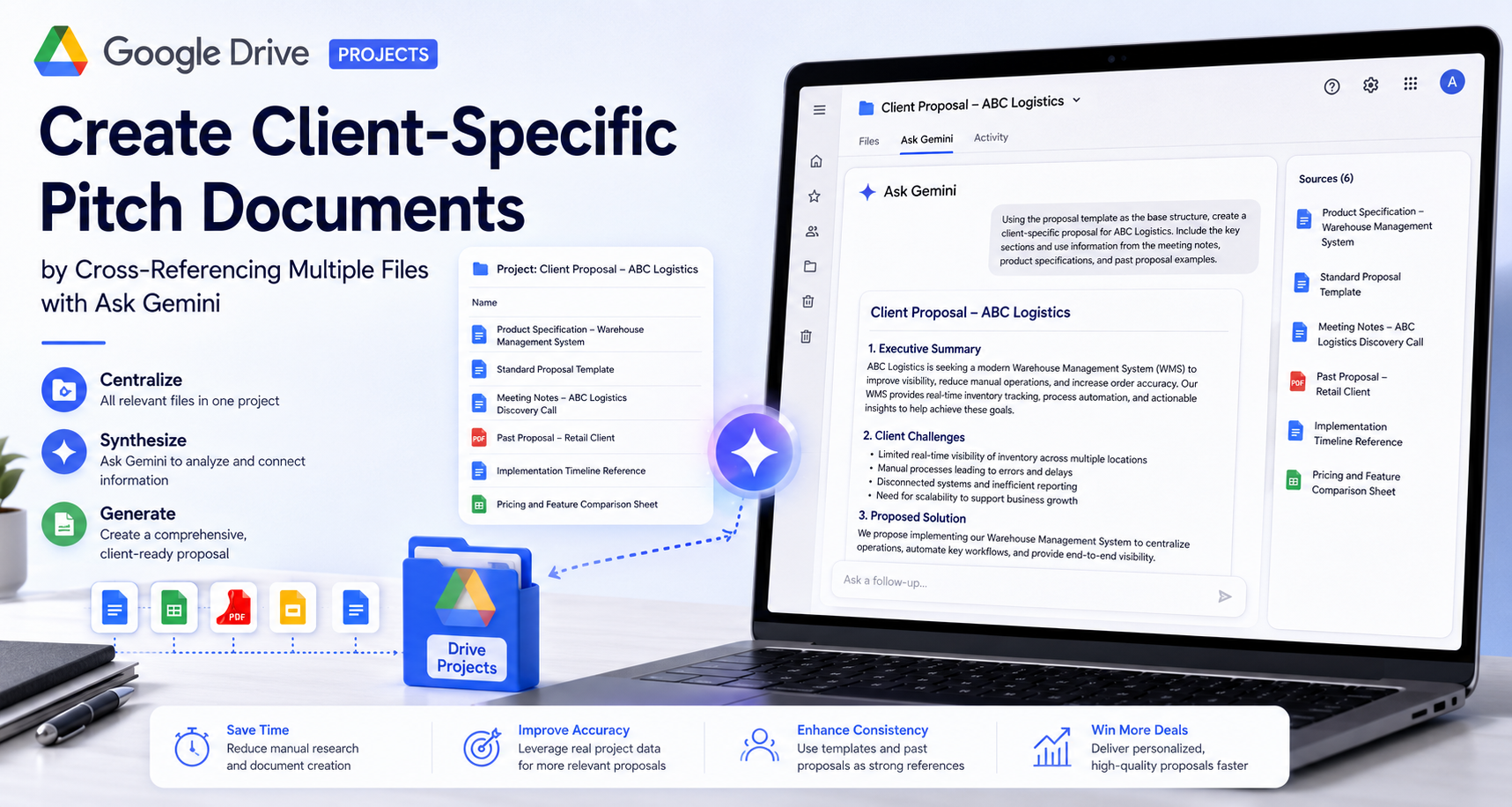
Introduction Preparing a client proposal often requires information scattered across many internal documents: product specifications, previous proposal templates, meeting notes, pricing references, implementation plans,...