The Azure Batch Transcription provides a powerful solution for transcribing large quantities of audio stored in Azure Blob Storage.
It is designed to help organizations process large-scale transcription tasks efficiently.

Use Cases:
- Large-Scale Audio Transcription: Ideal for organizations needing to transcribe large volumes of audio data in storage, such as customer service calls, podcasts, or media content.
- Azure Blob Storage Integration: Supports batch transcription of audio files stored in Azure Blob Storage, allowing users to provide multiple files per request for transcription.
- Asynchronous Processing: Submitting jobs for batch transcription is done asynchronously, allowing for parallel processing and faster turnaround times.
- Power Platform Integration: The Batch Speech to Text Connector allows for low-code or no-code solutions, making it easier to integrate into business workflows like Power Automate, Power Apps, and Logic Apps.

Strengths:
- Scalability: Efficiently handles large transcription tasks by processing multiple files concurrently, which helps in reducing overall transcription time.
- Asynchronous Operation: The service works asynchronously, meaning users can submit jobs without having to wait for real-time processing, making it more scalable for high volumes of audio.
- Storage Integration: It seamlessly integrates with Azure Blob Storage, providing an easy-to-use system for managing audio files.
- Cost-Effective: It is well-suited for projects involving a large amount of audio data, offering a solution that scales with user needs.
Weaknesses:
- Job Start Delays: At peak times, batch transcription jobs may experience delays in processing, sometimes taking up to 30 minutes or longer for the transcription job to begin.
- Real-Time Processing: Unlike some other transcription APIs, the batch transcription service is not designed for real-time transcription and may not be ideal for applications that require immediate transcription results.
- Dependency on Azure Storage: Requires audio files to be stored in Azure Blob Storage, which might require additional setup and maintenance.
Models:
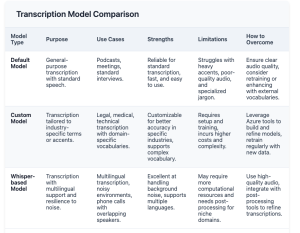
The API allows to specify which transcription model you want to use for a given batch job. The available models are:
- Default Model:
- Custom Model:
- Whisper-based Model (Whisper from OpenAI):
When you submit a batch transcription job using the Azure Batch Transcription API, you specify which model to use as part of the job parameters.
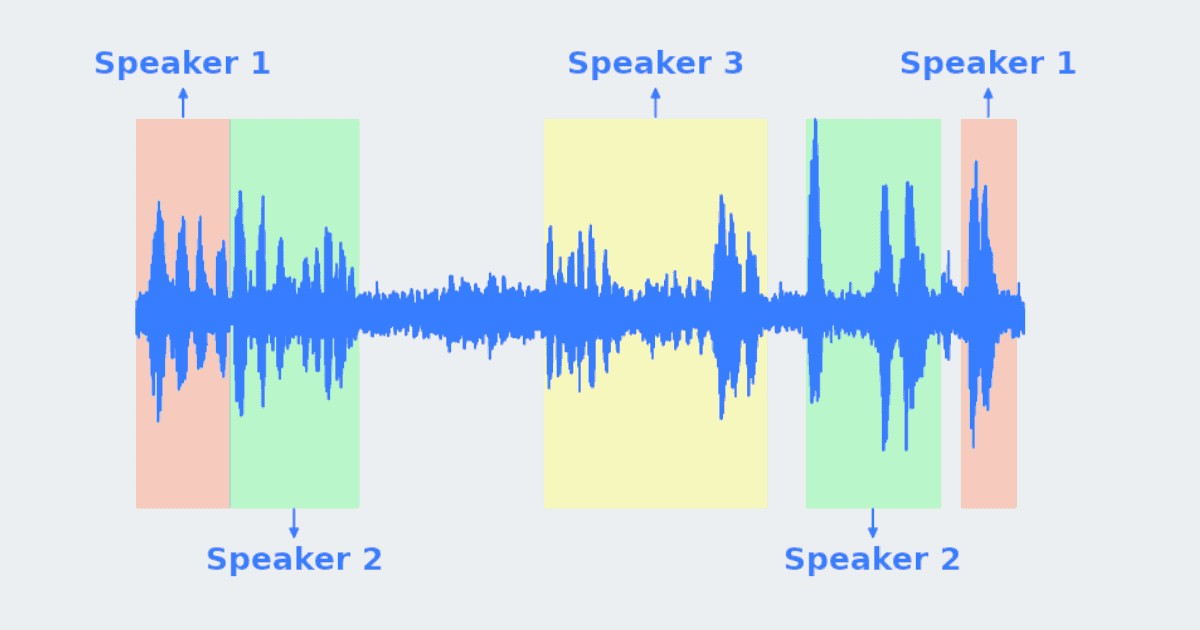
Diarization:
- Automatic Speaker Identification: The API automatically segments the audio into different speaker turns. Each segment is then labeled with a speaker identifier (e.g., Speaker 1, Speaker 2).
- Output Format: The transcription output includes timestamps for each speaker segment and identifies which speaker was talking at that particular time. This is especially useful for meetings, interviews, podcasts, or other multi-speaker content.
- Supported Audio: Diarization works with audio files that contain multiple speakers. The system can differentiate and transcribe each speaker’s dialogue separately.
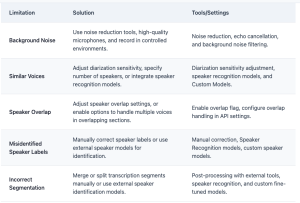
Limitations of Diarization:
Summary:
Azure Batch Transcription efficiently transcribes large audio files stored in Azure Blob Storage. It processes multiple files concurrently and asynchronously, reducing turnaround time. While it offers scalability and integration with Azure, there may be delays during peak times. It’s best suited for large-scale transcription projects and offers low-code solutions like Power Automate.