Struggling to make your content stand out? With Ideogram and ChatGPT, you can create eye-catching visual hooks in just seconds that will captivate your...
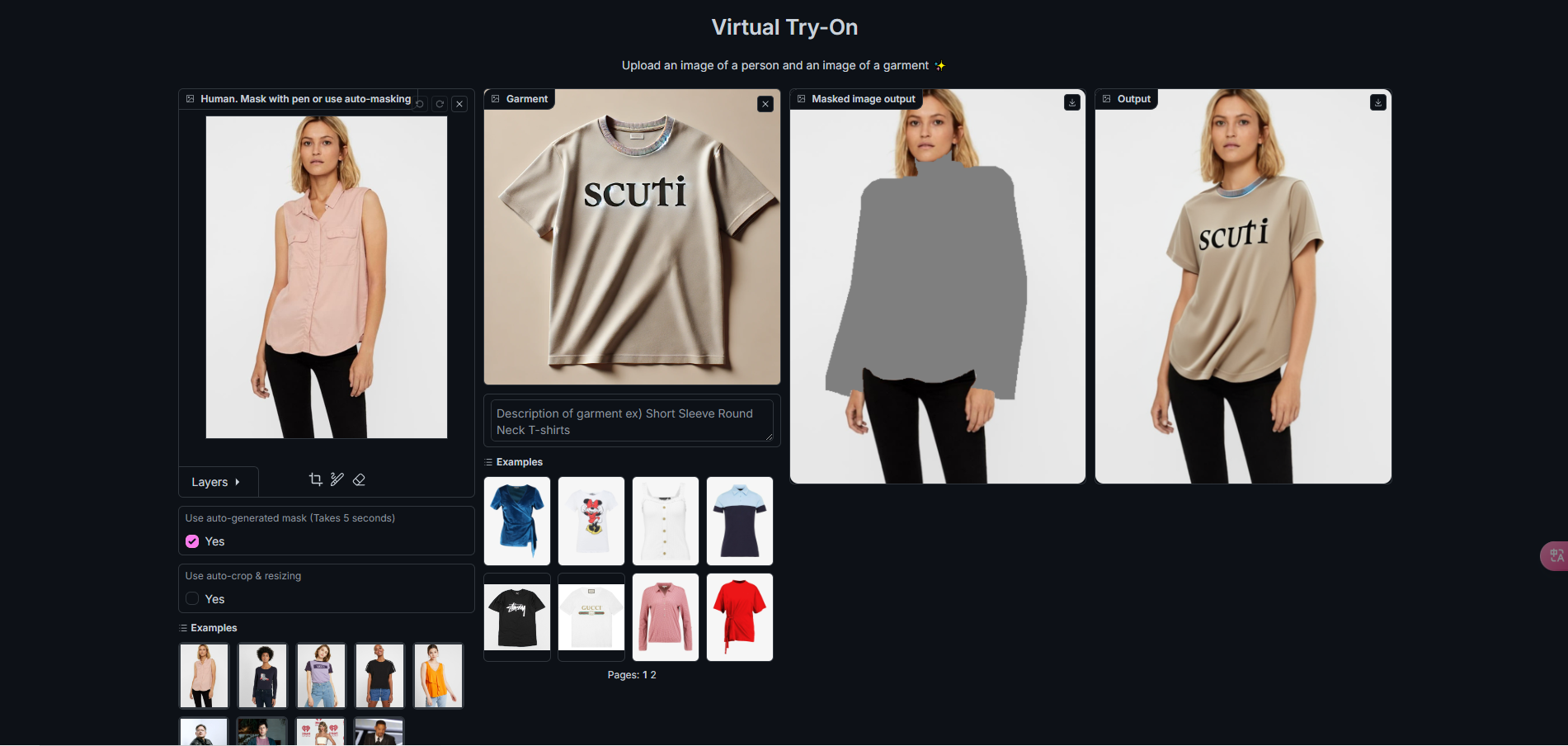
Virtual Try-On is an advanced technology in the field of e-commerce and user experience, particularly in the fashion and beauty industries. This technology allows...
Eleven Labs is a company specializing in advanced AI-driven solutions, particularly in the realm of natural language processing and speech synthesis. Founded with the...