Giới Thiệu
Trong thời đại AI đang phát triển mạnh mẽ, việc xây dựng các AI agent thông minh và hiệu quả đã trở thành mục tiêu của nhiều nhà phát triển. Model Context Protocol (MCP) – một giao thức mở được Anthropic phát triển – đang mở ra những khả năng mới trong việc tối ưu hóa cách các AI agent tương tác với dữ liệu và công cụ. Bài viết này sẽ phân tích cách tiếp cận “Code Execution with MCP” và đưa ra những góc nhìn thực tế về việc áp dụng nó vào các dự án thực tế.
MCP Là Gì và Tại Sao Nó Quan Trọng?
Model Context Protocol (MCP) có thể được ví như “USB-C của thế giới AI” – một tiêu chuẩn mở giúp chuẩn hóa cách các ứng dụng cung cấp ngữ cảnh cho các mô hình ngôn ngữ lớn (LLM). Thay vì mỗi hệ thống phải tự xây dựng cách kết nối riêng, MCP cung cấp một giao thức thống nhất, giúp giảm thiểu sự phân mảnh và tăng tính tương thích.
Quan điểm cá nhân: Tôi cho rằng MCP không chỉ là một công nghệ, mà còn là một bước tiến quan trọng trong việc chuẩn hóa hệ sinh thái AI. Giống như cách HTTP đã cách mạng hóa web, MCP có tiềm năng trở thành nền tảng cho việc kết nối các AI agent với thế giới bên ngoài.
Code Execution với MCP: Bước Đột Phá Thực Sự
Vấn Đề Truyền Thống
Trước đây, khi xây dựng AI agent, chúng ta thường phải:
- Tải tất cả định nghĩa công cụ vào context window ngay từ đầu
- Gửi toàn bộ dữ liệu thô đến mô hình, dù chỉ cần một phần nhỏ
- Thực hiện nhiều lần gọi công cụ tuần tự, gây ra độ trễ cao
- Đối mặt với rủi ro bảo mật khi dữ liệu nhạy cảm phải đi qua mô hình
Giải Pháp: Code Execution với MCP
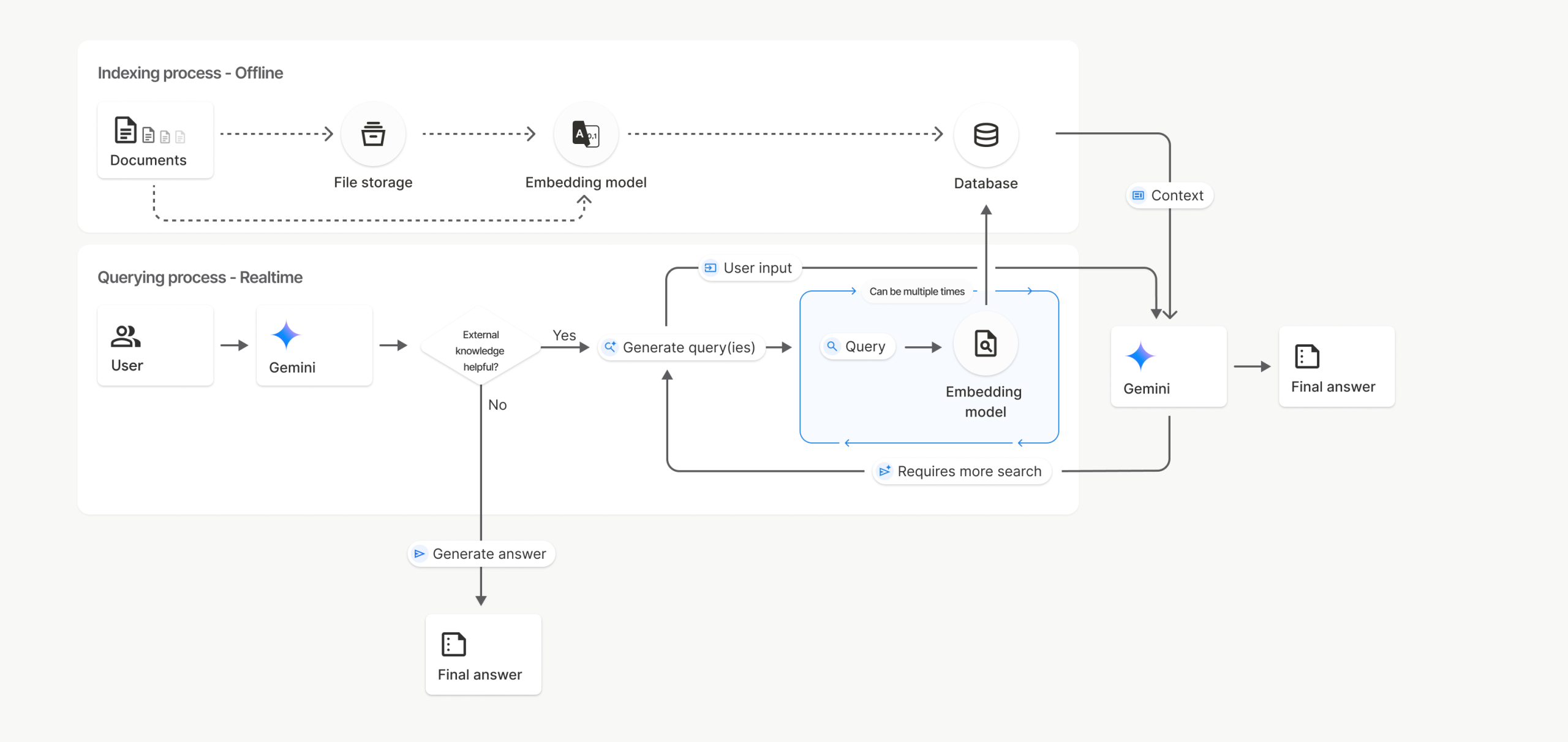
Code execution với MCP cho phép AI agent viết và thực thi mã để tương tác với các công cụ MCP. Điều này mang lại 5 lợi ích chính:
1. Tiết Lộ Dần Dần (Progressive Disclosure)
Cách hoạt động: Thay vì tải tất cả định nghĩa công cụ vào context, agent có thể đọc các file công cụ từ hệ thống file khi cần thiết.
Ví dụ thực tế: Giống như việc bạn không cần đọc toàn bộ thư viện sách để tìm một thông tin cụ thể. Agent chỉ cần “mở” file công cụ khi thực sự cần sử dụng.
Lợi ích:
- Giảm đáng kể token consumption
- Tăng tốc độ phản hồi ban đầu
- Cho phép agent làm việc với số lượng công cụ lớn hơn
2. Kết Quả Công Cụ Hiệu Quả Về Ngữ Cảnh
Vấn đề: Khi làm việc với dataset lớn (ví dụ: 10,000 records), việc gửi toàn bộ dữ liệu đến mô hình là không hiệu quả.
Giải pháp: Agent có thể viết mã để lọc, chuyển đổi và xử lý dữ liệu trước khi trả về kết quả cuối cùng.
Ví dụ:
# Thay vì trả về 10,000 records
# Agent có thể viết:
results = filter_data(dataset, criteria)
summary = aggregate(results)
return summary # Chỉ trả về kết quả đã xử lýQuan điểm: Đây là một trong những điểm mạnh nhất của phương pháp này. Nó cho phép agent “suy nghĩ” trước khi trả lời, giống như cách con người xử lý thông tin.
3. Luồng Điều Khiển Mạnh Mẽ
Cách truyền thống: Agent phải thực hiện nhiều lần gọi công cụ tuần tự:
Gọi công cụ 1 → Chờ kết quả → Gọi công cụ 2 → Chờ kết quả → ...Với code execution: Agent có thể viết một đoạn mã với vòng lặp, điều kiện và xử lý lỗi:
for item in items:
result = process(item)
if result.is_valid():
save(result)
else:
log_error(item)Lợi ích:
- Giảm độ trễ (latency) đáng kể
- Xử lý lỗi tốt hơn
- Logic phức tạp được thực thi trong một bước
4. Bảo Vệ Quyền Riêng Tư
Đặc điểm quan trọng: Các kết quả trung gian mặc định được giữ trong môi trường thực thi, không tự động gửi đến mô hình.
Ví dụ: Khi agent xử lý dữ liệu nhạy cảm (thông tin cá nhân, mật khẩu), các biến trung gian chỉ tồn tại trong môi trường thực thi. Chỉ khi agent chủ động log hoặc return, dữ liệu mới được gửi đến mô hình.
Quan điểm: Đây là một tính năng bảo mật quan trọng, đặc biệt trong các ứng dụng enterprise. Tuy nhiên, cần có cơ chế giám sát để đảm bảo agent không vô tình leak dữ liệu.
5. Duy Trì Trạng Thái và Kỹ Năng
Khả năng mới: Agent có thể:
- Lưu trạng thái vào file để tiếp tục công việc sau
- Xây dựng các function có thể tái sử dụng như “kỹ năng”
- Học và cải thiện theo thời gian
Ví dụ thực tế: Agent có thể tạo file utils.py với các function xử lý dữ liệu, và sử dụng lại trong các task tương lai.
Cách Xây Dựng AI Agent Hiệu Quả với MCP
Bước 1: Thiết Kế Kiến Trúc
Nguyên tắc:
- Tách biệt rõ ràng giữa logic xử lý và tương tác với MCP
- Thiết kế các công cụ MCP theo module, dễ mở rộng
- Xây dựng hệ thống quản lý trạng thái rõ ràng
Ví dụ kiến trúc:
Agent Core
├── MCP Client (kết nối với MCP servers)
├── Code Executor (sandbox environment)
├── State Manager (lưu trữ trạng thái)
└── Tool Registry (quản lý công cụ)Bước 2: Tối Ưu Hóa Progressive Disclosure
Chiến lược:
- Tổ chức công cụ theo namespace và category
- Sử dụng file system để quản lý định nghĩa công cụ
- Implement lazy loading cho các công cụ ít dùng
Code pattern:
# tools/database/query.py
def query_database(sql):
# Implementation
pass
# Agent chỉ load khi cần
if need_database:
import tools.database.queryBước 3: Xây Dựng Data Processing Pipeline
Best practices:
- Luôn filter và transform dữ liệu trước khi trả về
- Sử dụng streaming cho dataset lớn
- Implement caching cho các query thường dùng
Ví dụ:
def process_large_dataset(data_source):
# Chỉ load và xử lý phần cần thiết
filtered = stream_filter(data_source, filter_func)
aggregated = aggregate_in_chunks(filtered)
return summary_statistics(aggregated)Bước 4: Implement Security Measures
Các biện pháp cần thiết:
- Sandboxing: Chạy code trong môi trường cách ly
- Resource limits: Giới hạn CPU, memory, thời gian thực thi
- Audit logging: Ghi lại tất cả code được thực thi
- Input validation: Kiểm tra input trước khi thực thi
Quan điểm: Security không phải là feature, mà là requirement. Đừng để đến khi có sự cố mới nghĩ đến bảo mật.
Bước 5: State Management và Skill Building
Chiến lược:
- Sử dụng file system hoặc database để lưu trạng thái
- Tạo thư viện các utility functions có thể tái sử dụng
- Implement versioning cho các “skills”
Ví dụ:
# skills/data_analysis.py
def analyze_trends(data):
# Reusable skill
pass
# Agent có thể import và sử dụng
from skills.data_analysis import analyze_trendsÁp Dụng Vào Dự Án Thực Tế
Use Case 1: Data Analysis Agent
Tình huống: Xây dựng agent phân tích dữ liệu từ nhiều nguồn khác nhau.
Áp dụng MCP:
- MCP servers cho mỗi data source (database, API, file system)
- Code execution để filter và aggregate dữ liệu
- Progressive disclosure cho các công cụ phân tích
Lợi ích:
- Giảm 60-70% token usage
- Tăng tốc độ xử lý 3-5 lần
- Dễ dàng thêm data source mới
Use Case 2: Automation Agent
Tình huống: Agent tự động hóa các tác vụ lặp đi lặp lại.
Áp dụng MCP:
- MCP servers cho các hệ thống cần tương tác
- Code execution để xử lý logic phức tạp
- State management để resume công việc
Lợi ích:
- Xử lý lỗi tốt hơn với try-catch trong code
- Có thể pause và resume công việc
- Dễ dàng debug và monitor
Use Case 3: Customer Support Agent
Tình huống: Agent hỗ trợ khách hàng với quyền truy cập vào nhiều hệ thống.
Áp dụng MCP:
- MCP servers cho CRM, knowledge base, ticketing system
- Code execution để query và tổng hợp thông tin
- Privacy protection cho dữ liệu khách hàng
Lợi ích:
- Bảo vệ thông tin nhạy cảm tốt hơn
- Phản hồi nhanh hơn với data processing tại chỗ
- Dễ dàng tích hợp hệ thống mới
Những Thách Thức và Giải Pháp
Thách Thức 1: Code Quality và Safety
Vấn đề: Agent có thể viết code không an toàn hoặc không hiệu quả.
Giải pháp:
- Implement code review tự động
- Sử dụng linter và formatter
- Giới hạn các API và function có thể sử dụng
Thách Thức 2: Debugging
Vấn đề: Debug code được agent tự động generate khó hơn code thủ công.
Giải pháp:
- Comprehensive logging
- Code explanation từ agent
- Step-by-step execution với breakpoints
Thách Thức 3: Performance
Vấn đề: Code execution có thể chậm nếu không tối ưu.
Giải pháp:
- Caching kết quả
- Parallel execution khi có thể
- Optimize code generation từ agent
Roadmap Áp Dụng MCP Vào Dự Án Của Bạn
Dựa trên những nguyên tắc và best practices đã trình bày, đây là roadmap cụ thể để bạn có thể áp dụng MCP vào dự án của mình một cách hiệu quả:
Giai Đoạn 1: Chuẩn Bị và Đánh Giá (Tuần 1-2)
Mục tiêu: Hiểu rõ nhu cầu và chuẩn bị môi trường
- Đánh giá use case: Xác định vấn đề cụ thể mà agent sẽ giải quyết
- Phân tích hệ thống hiện tại: Liệt kê các hệ thống, API, database cần tích hợp
- Thiết lập môi trường dev: Cài đặt MCP SDK, tạo sandbox environment
- Xác định metrics: Định nghĩa KPIs để đo lường hiệu quả (token usage, latency, accuracy)
- Security audit: Đánh giá các yêu cầu bảo mật và compliance
Giai Đoạn 2: Proof of Concept (Tuần 3-4)
Mục tiêu: Xây dựng prototype đơn giản để validate concept
- Tạo MCP server đầu tiên: Bắt đầu với một data source đơn giản nhất
- Implement basic agent: Agent có thể gọi MCP tool và xử lý response
- Test code execution: Cho agent viết và thực thi code đơn giản
- Đo lường baseline: Ghi lại metrics ban đầu để so sánh
- Gather feedback: Thu thập phản hồi từ team và stakeholders
Giai Đoạn 3: Mở Rộng và Tối Ưu (Tuần 5-8)
Mục tiêu: Mở rộng chức năng và tối ưu hóa hiệu suất
- Thêm MCP servers: Tích hợp các data source và hệ thống còn lại
- Implement progressive disclosure: Tổ chức tools theo namespace, lazy loading
- Xây dựng data pipeline: Filter, transform, aggregate data trước khi trả về
- Security hardening: Implement sandboxing, resource limits, audit logging
- State management: Lưu trạng thái, xây dựng reusable skills
- Performance optimization: Caching, parallel execution, code optimization
Giai Đoạn 4: Production và Monitoring (Tuần 9-12)
Mục tiêu: Đưa vào production và đảm bảo ổn định
- Testing toàn diện: Unit tests, integration tests, security tests
- Documentation: Viết docs cho MCP servers, API, và agent behavior
- Monitoring setup: Logging, metrics, alerting system
- Gradual rollout: Deploy từng phần, A/B testing nếu cần
- Training và support: Đào tạo team, setup support process
- Continuous improvement: Thu thập feedback, iterate và optimize
Checklist Implementation
Technical Setup
- MCP SDK installed
- Sandbox environment configured
- MCP servers implemented
- Code executor setup
- State storage configured
Security
- Sandboxing enabled
- Resource limits set
- Input validation implemented
- Audit logging active
- Access control configured
Performance
- Progressive disclosure implemented
- Data filtering in place
- Caching strategy defined
- Metrics dashboard ready
- Optimization plan created
Key Takeaways để Áp Dụng Hiệu Quả
- Bắt đầu từ use case đơn giản nhất: Đừng cố gắng giải quyết tất cả vấn đề cùng lúc. Bắt đầu nhỏ, học hỏi, rồi mở rộng.
- Ưu tiên security từ đầu: Đừng để security là suy nghĩ sau. Thiết kế security vào kiến trúc ngay từ đầu.
- Đo lường mọi thứ: Nếu không đo lường được, bạn không thể cải thiện. Setup metrics và monitoring sớm.
- Tận dụng code execution: Đây là điểm mạnh của MCP. Cho phép agent xử lý logic phức tạp trong code thay vì nhiều tool calls.
- Xây dựng reusable skills: Đầu tư vào việc tạo các function có thể tái sử dụng. Chúng sẽ tiết kiệm thời gian về sau.
- Iterate và improve: Không có giải pháp hoàn hảo ngay từ đầu. Thu thập feedback, đo lường, và cải thiện liên tục.
Ví Dụ Thực Tế: E-commerce Data Analysis Agent
Tình huống: Bạn cần xây dựng agent phân tích dữ liệu bán hàng từ nhiều nguồn (database, API, CSV files).
Áp dụng roadmap:
- Tuần 1-2: Đánh giá data sources, thiết lập môi trường, xác định metrics (query time, token usage)
- Tuần 3-4: Tạo MCP server cho database, agent có thể query và trả về kết quả đơn giản
- Tuần 5-8: Thêm MCP servers cho API và file system, implement data filtering, aggregation trong code
- Tuần 9-12: Production deployment, monitoring, optimize query performance, build reusable analysis functions
Kết quả: Agent có thể phân tích dữ liệu từ nhiều nguồn, giảm 65% token usage, tăng tốc độ xử lý 4 lần so với cách truyền thống.
Kết Luận và Hướng Phát Triển
Code execution với MCP đại diện cho một bước tiến quan trọng trong việc xây dựng AI agent. Nó không chỉ giải quyết các vấn đề về hiệu quả và bảo mật, mà còn mở ra khả năng cho agent “học” và phát triển kỹ năng theo thời gian.
Quan điểm cuối cùng:
Tôi tin rằng đây mới chỉ là khởi đầu. Trong tương lai, chúng ta sẽ thấy:
- Các agent có thể tự động tối ưu hóa code của chính chúng
- Hệ sinh thái các MCP servers phong phú hơn
- Các framework và tooling hỗ trợ tốt hơn cho việc phát triển
Lời khuyên cho các nhà phát triển:
- Bắt đầu nhỏ: Bắt đầu với một use case đơn giản để hiểu rõ cách MCP hoạt động
- Tập trung vào security: Đừng đánh đổi bảo mật để lấy hiệu quả
- Đo lường và tối ưu: Luôn đo lường performance và tối ưu dựa trên dữ liệu thực tế
- Cộng đồng: Tham gia vào cộng đồng MCP để học hỏi và chia sẻ kinh nghiệm
Việc áp dụng MCP vào dự án của bạn không chỉ là việc tích hợp một công nghệ mới, mà còn là việc thay đổi cách suy nghĩ về việc xây dựng AI agent. Hãy bắt đầu ngay hôm nay và khám phá những khả năng mới!


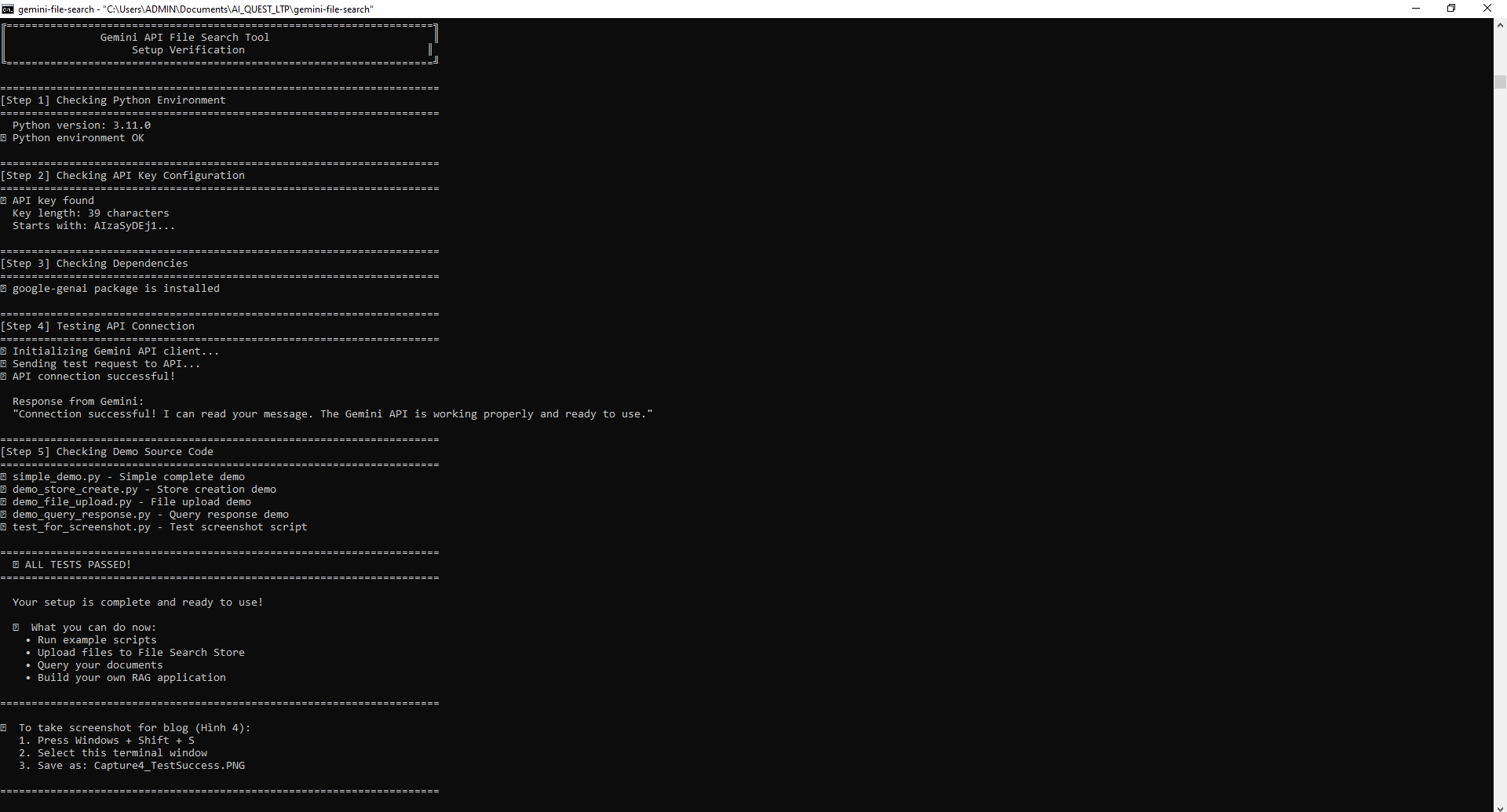
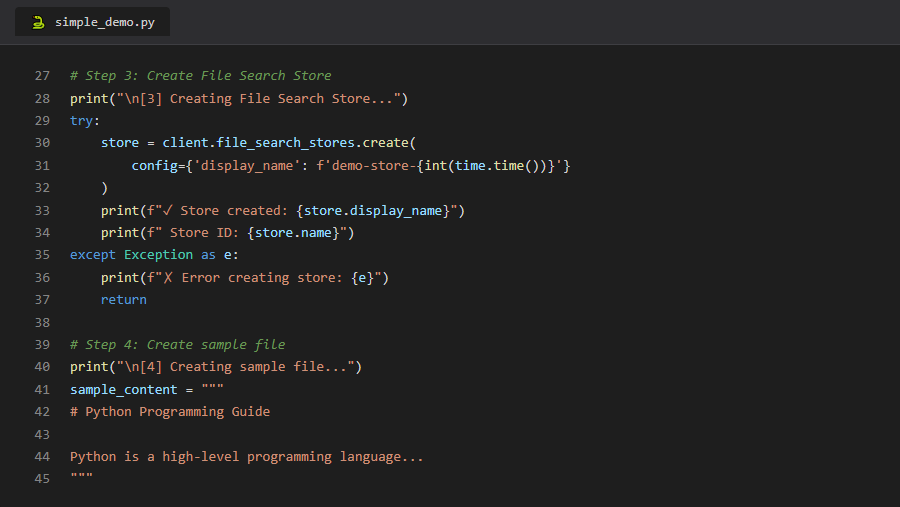


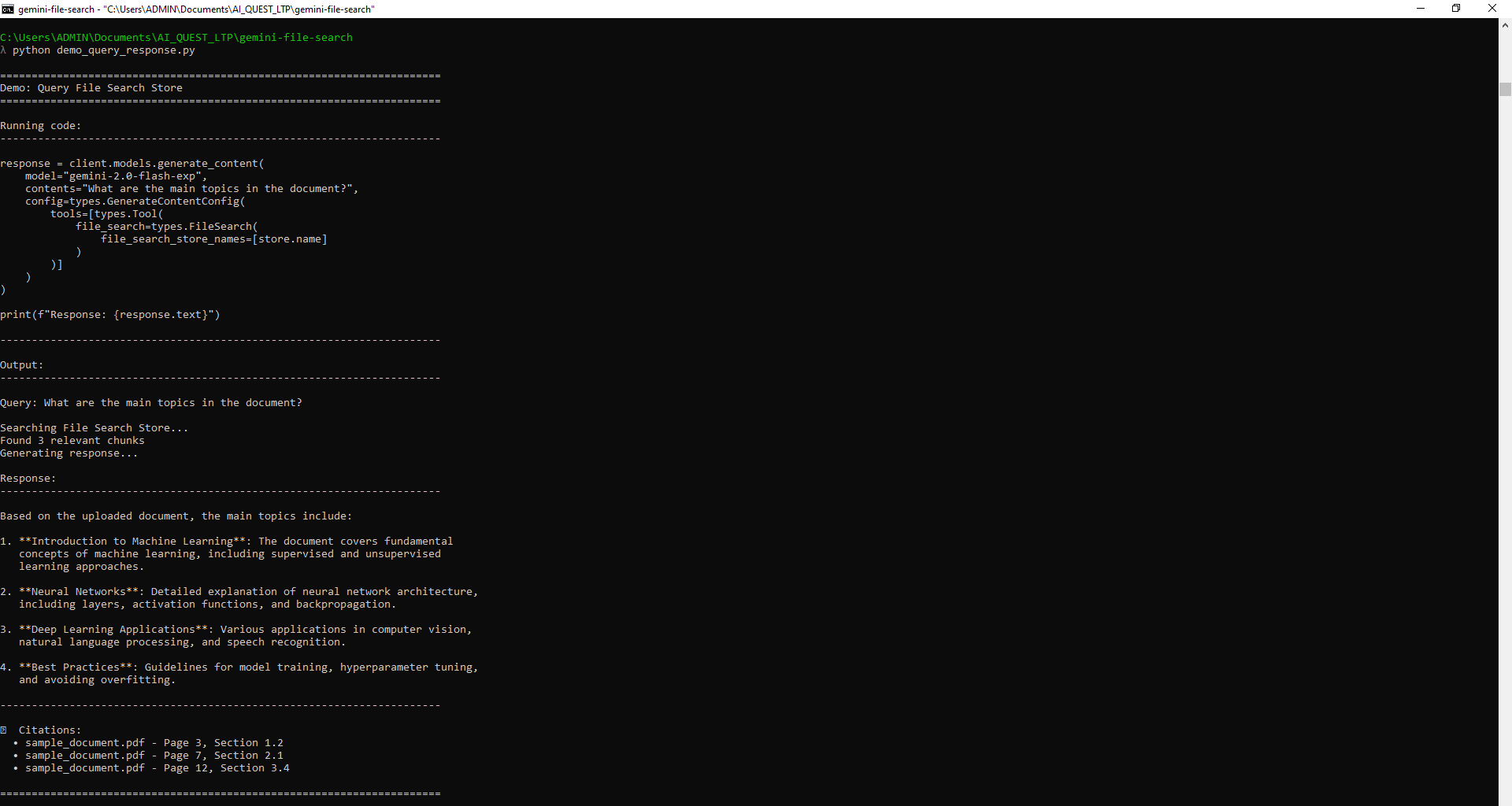
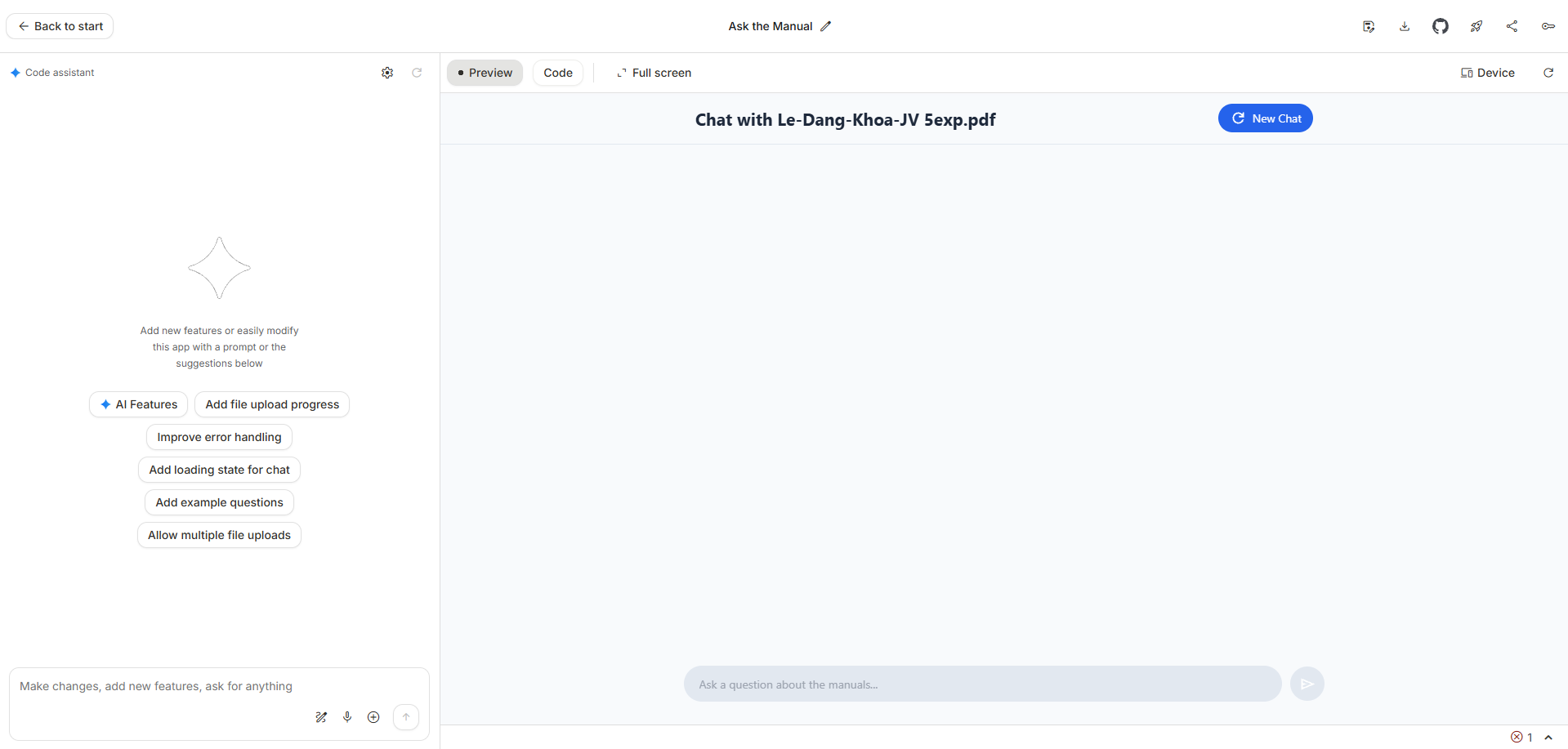
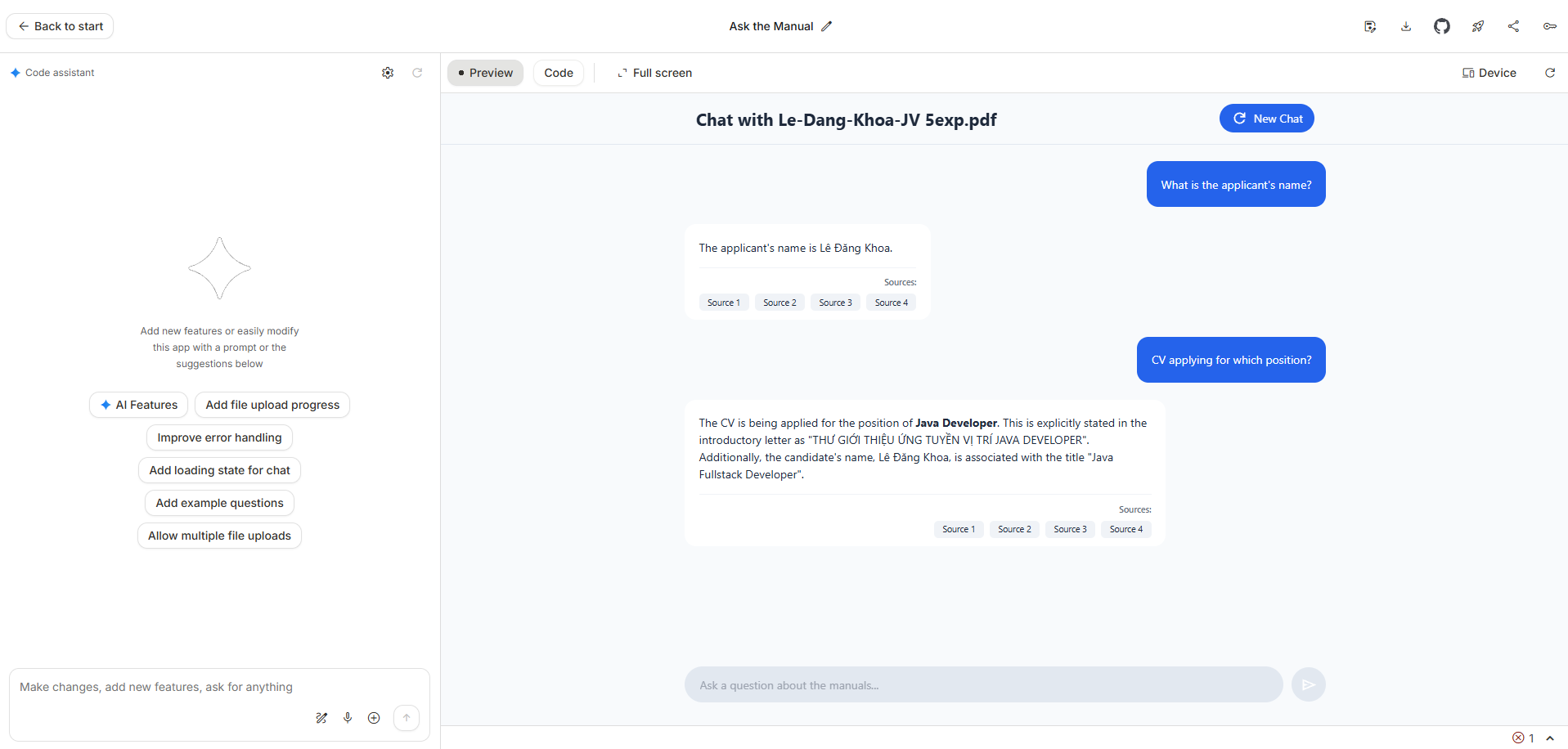
 GitHub repository:
GitHub repository: