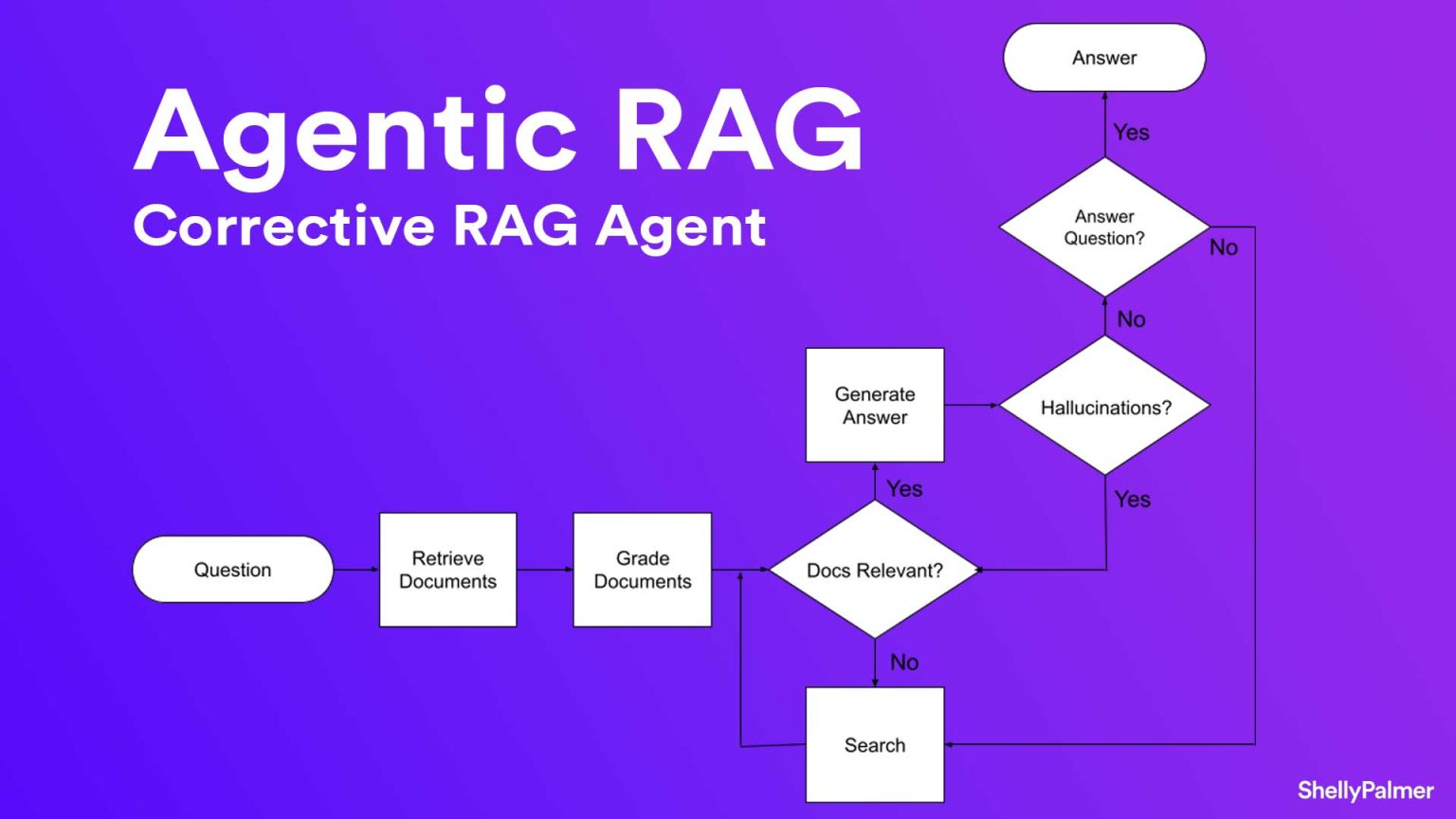
Chào bạn, lại là mình, Quỳnh Nga đây! Chào mừng bạn đến với bài viết mới của mình. Dạo gần đây, công việc của...
We make services people love by the power of Gen AI.