Generative AI is rapidly reshaping how we build intelligent systems — from text-to-image applications to multi-agent orchestration. But behind all that creativity lies a serious engineering challenge: how to design scalable, cost-efficient backends that handle unpredictable, compute-heavy AI workloads.
In Part 1: https://scuti.asia/serverless-generative-ai-architectural-patterns-part-1/
In Part 2 of AWS’s series “Serverless Generative AI Architectural Patterns,” the introduce three non-real-time patterns for running generative AI at scale — where workloads can be asynchronous, parallelized, or scheduled in bulk.
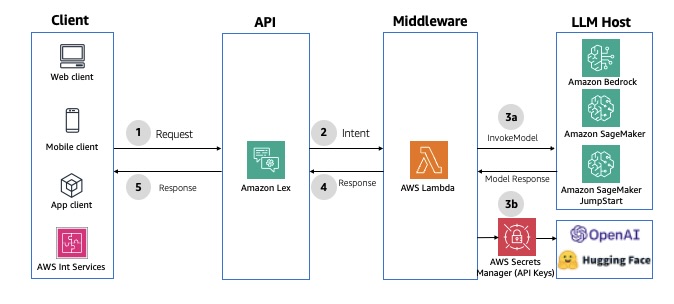
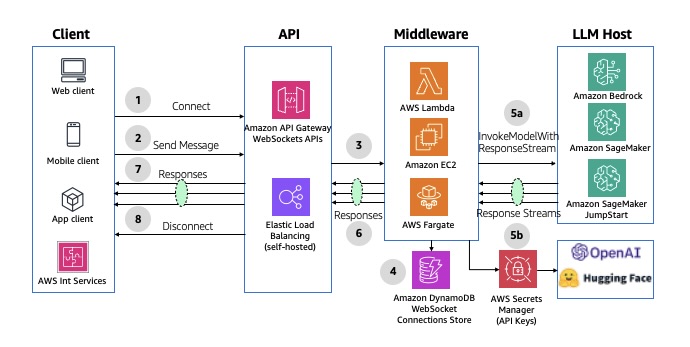
🧩 Pattern 4: Buffered Asynchronous Request–Response
When to Use
This pattern is perfect for tasks that take time — such as:
-
Text-to-video or text-to-music generation
-
Complex data analysis or simulations
-
AI-assisted design, art, or high-resolution image rendering
Instead of waiting for immediate results, the system processes requests in the background and notifies users once done.
Architecture Flow
-
Amazon API Gateway (REST / WebSocket) receives incoming requests.
-
Amazon SQS queues the requests to decouple frontend and backend.
-
A compute backend (AWS Lambda, Fargate, or EC2) pulls messages, calls the model (via Amazon Bedrock or custom inference), and stores results in DynamoDB or S3.
-
The client polls or listens via WebSocket for completion.

Benefits
-
Highly scalable and resilient to spikes.
-
Reduces load on real-time systems.
-
Ideal for workflows where a few minutes of delay is acceptable.
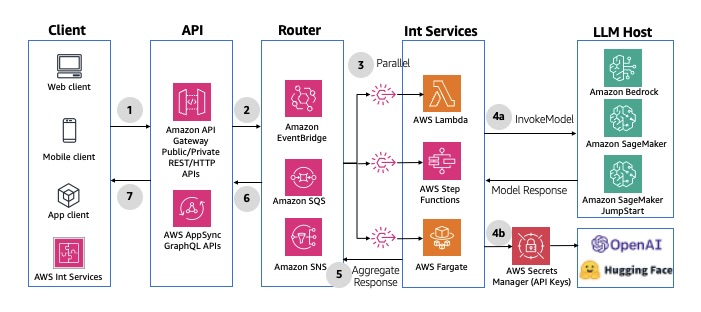
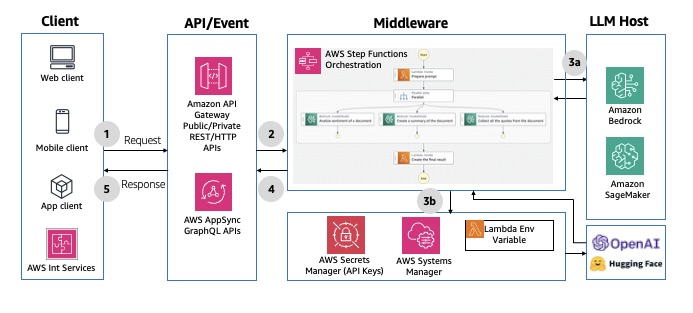
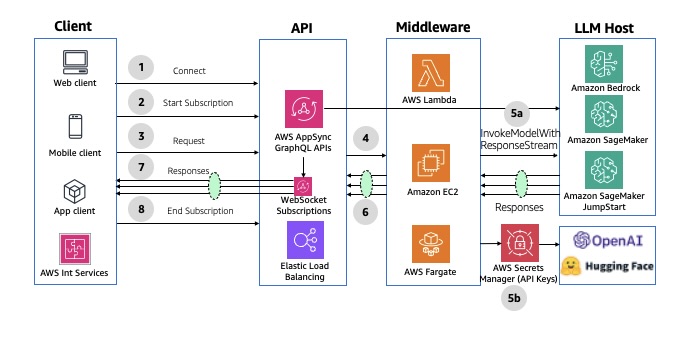
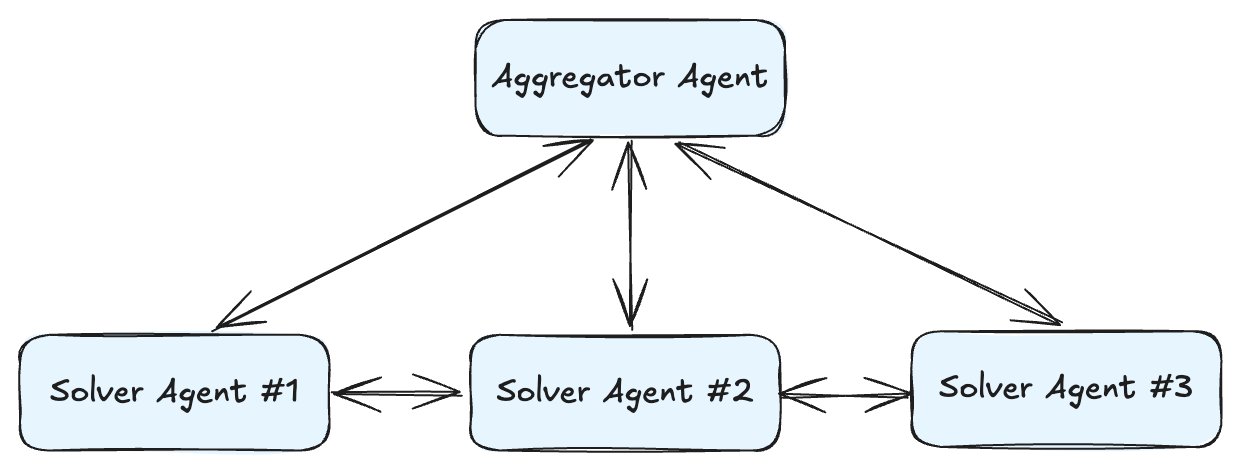
🔀 Pattern 5: Multimodal Parallel Fan-Out
When to Use
For multi-model or multi-agent workloads — for example:
-
Combining text, image, and audio generation
-
Running multiple LLMs for different subtasks
-
Parallel pipelines that merge into one consolidated output
Architecture Flow
-
An event (API call, S3 upload, etc.) publishes to Amazon SNS or EventBridge.
-
The message fans out to multiple targets — queues or Lambda functions.
-
Each target performs a separate inference or operation.
-
AWS Step Functions or EventBridge Pipes aggregate results when all sub-tasks finish.
Benefits
-
Enables concurrent processing for faster results.
-
Fault isolation between sub-tasks.
-
Scales elastically with demand.
This pattern is especially useful in multi-agent AI systems, where independent reasoning units run in parallel before combining their insights.
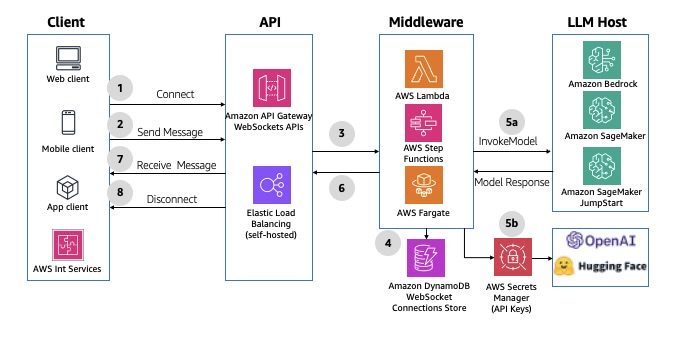
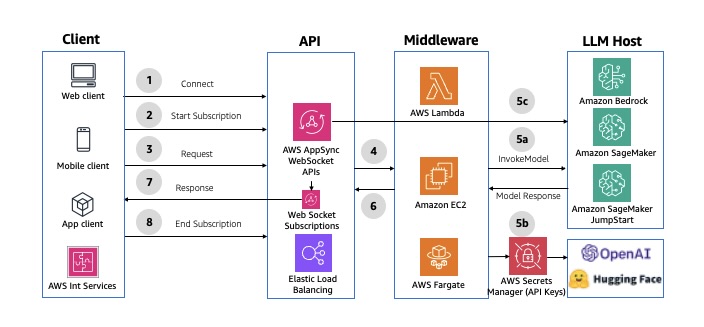
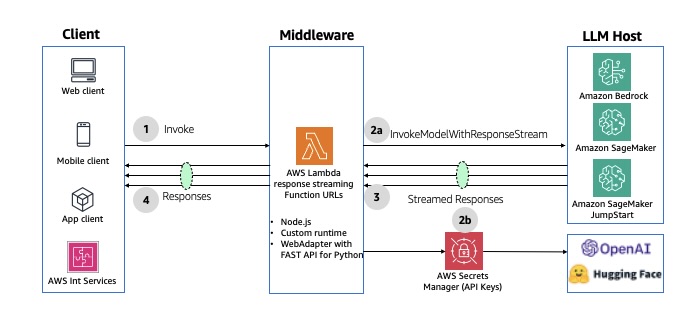
🕒 Pattern 6: Non-Interactive Batch Processing
When to Use
Use this pattern for large-scale or scheduled workloads that don’t involve user interaction — such as:
-
Generating embeddings for millions of records
-
Offline document summarization or translation
-
Periodic content refreshes or nightly analytics jobs
Architecture Flow
-
A scheduled event (via Amazon EventBridge Scheduler or CloudWatch Events) triggers the batch workflow.
-
AWS Step Functions, Glue, or Lambda orchestrate the sequence of tasks.
-
Data is read from S3, processed through generative or analytical models, and written back to storage or a database.
-
Optional post-processing (indexing, notifications, reports) completes the cycle.
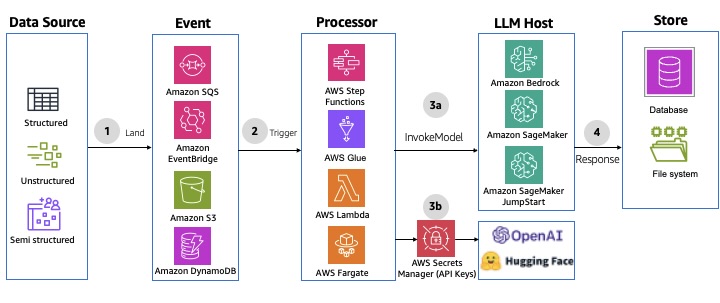
Benefits
-
Handles high-volume workloads without human interaction.
-
Scales automatically with AWS’s serverless services.
-
Cost-efficient since resources run only during job execution.
This pattern is common in data pipelines, RAG preprocessing, or periodic AI content generation where timing, not interactivity, matters.
⚙️ Key Takeaways
-
Serverless + Generative AI provides elasticity, scalability, and simplicity — letting teams focus on creativity instead of infrastructure.
-
Event-driven architectures (SQS, SNS, EventBridge) keep systems modular, fault-tolerant, and reactive.
-
With building blocks like Lambda, Fargate, Step Functions, DynamoDB, Bedrock, and S3, developers can move from experiments to production-grade systems seamlessly.
-
These patterns make it easier to build cost-efficient, always-available AI pipelines — from real-time chatbots to scheduled large-scale content generation.
💡 Final Thoughts
Generative AI isn’t just about model power — it’s about the architecture that delivers it reliably at scale.
AWS’s serverless ecosystem offers a powerful foundation for building asynchronous, parallel, and batch AI workflows that adapt to user and business needs alike.
👉 Explore the full article here: Serverless Generative AI Architectural Patterns – Part 2
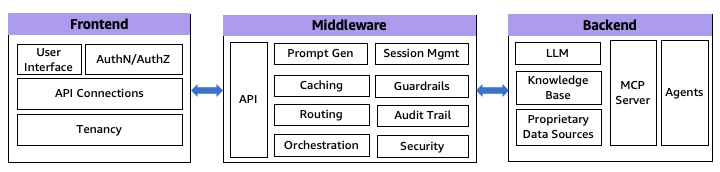
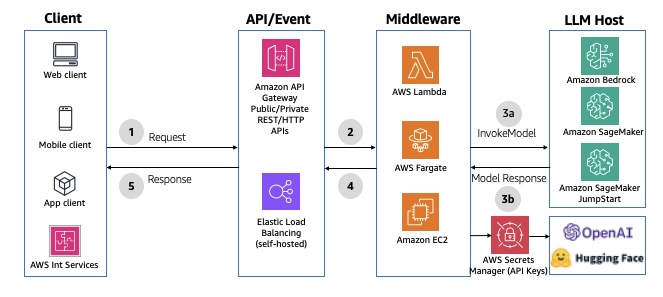
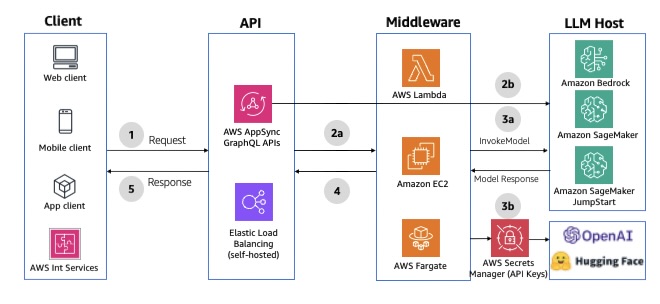
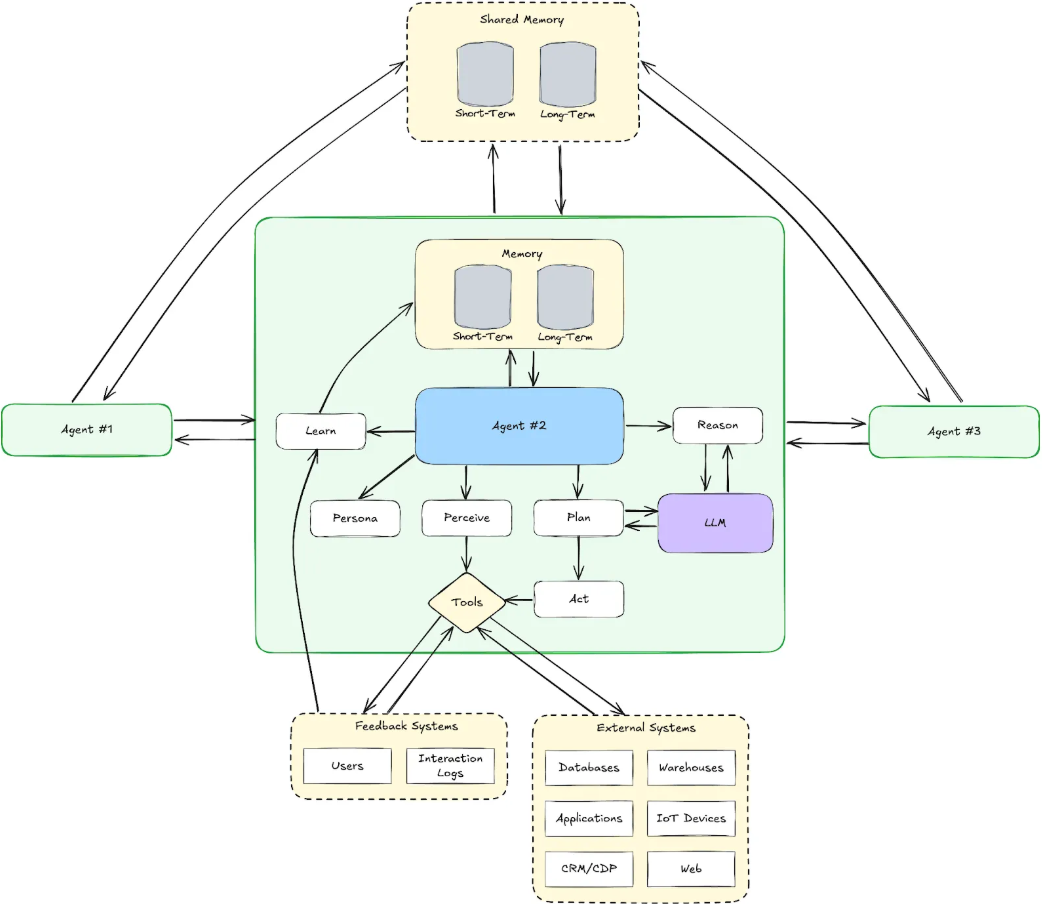
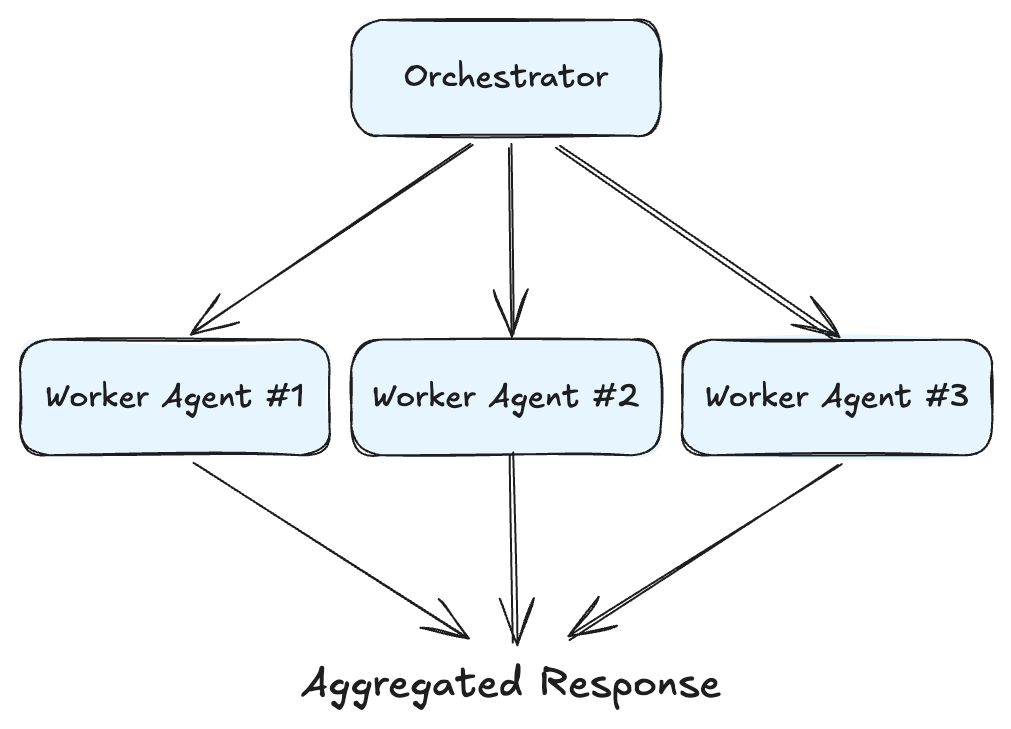
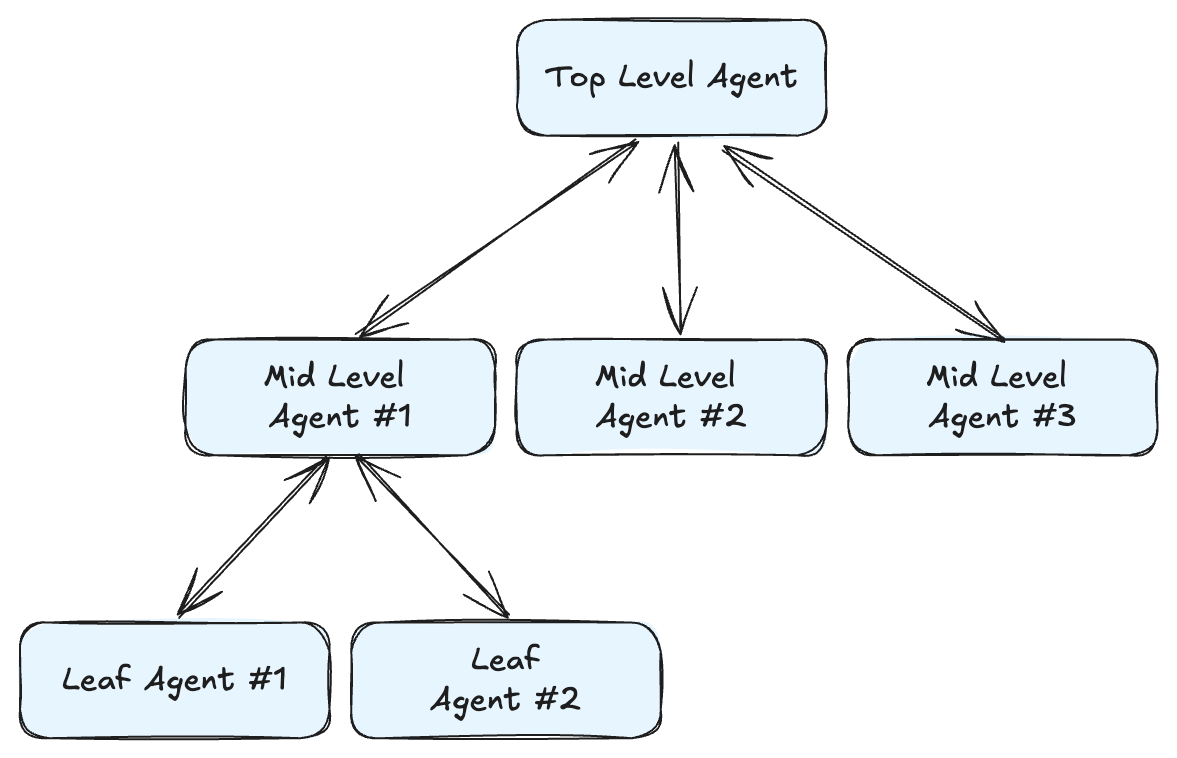
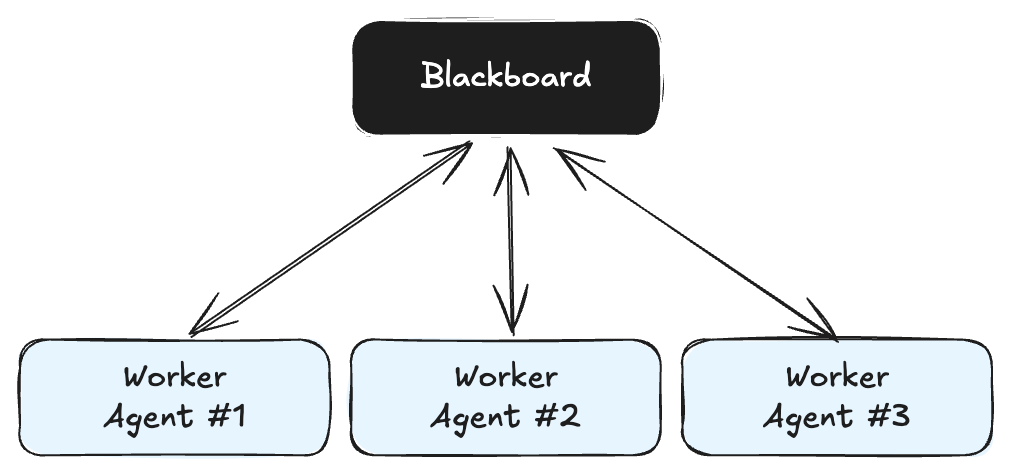


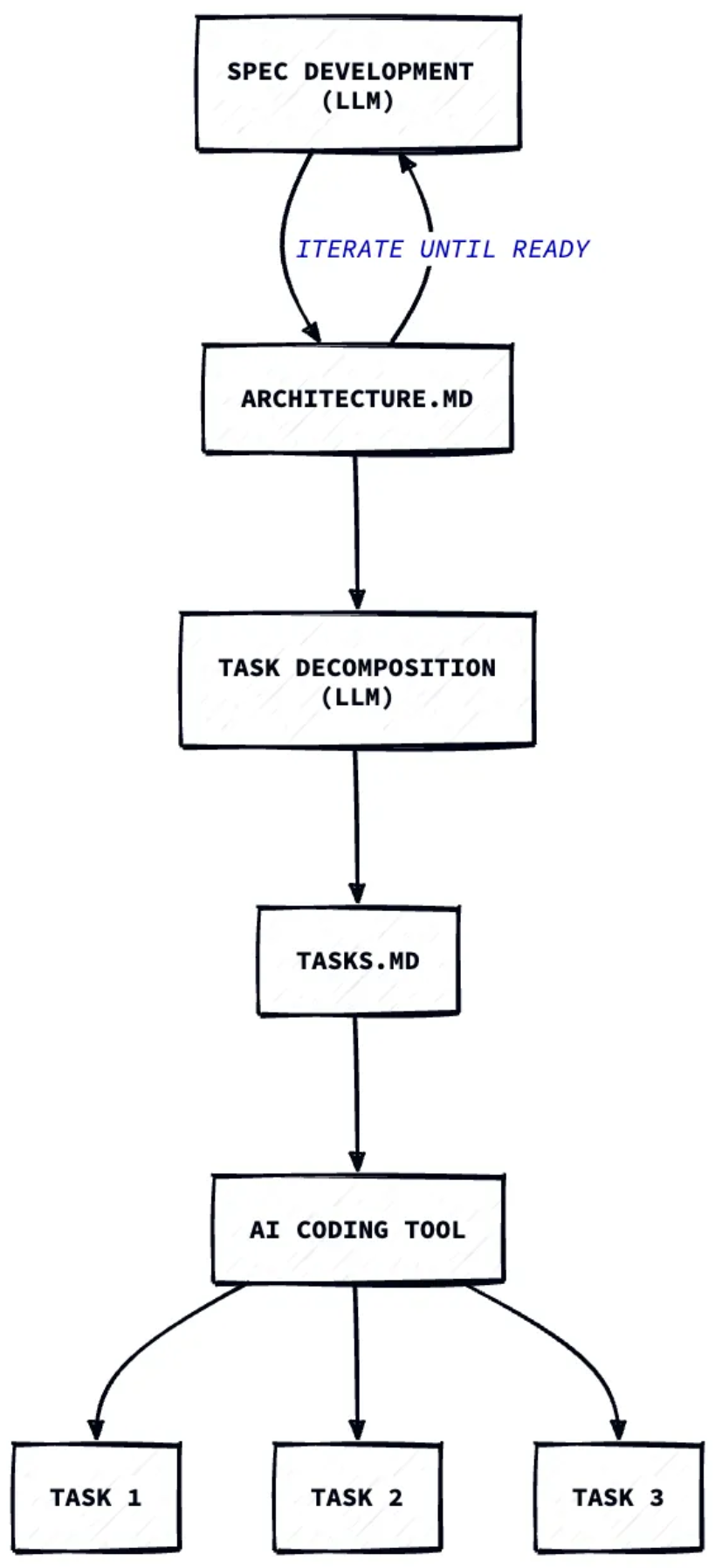
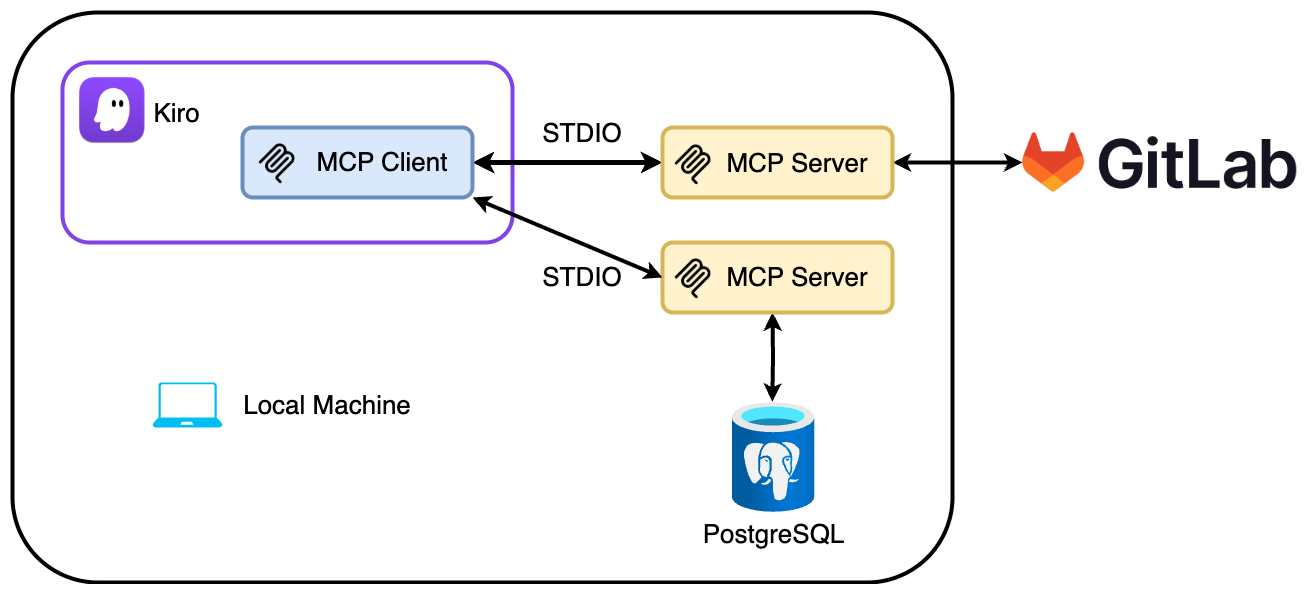
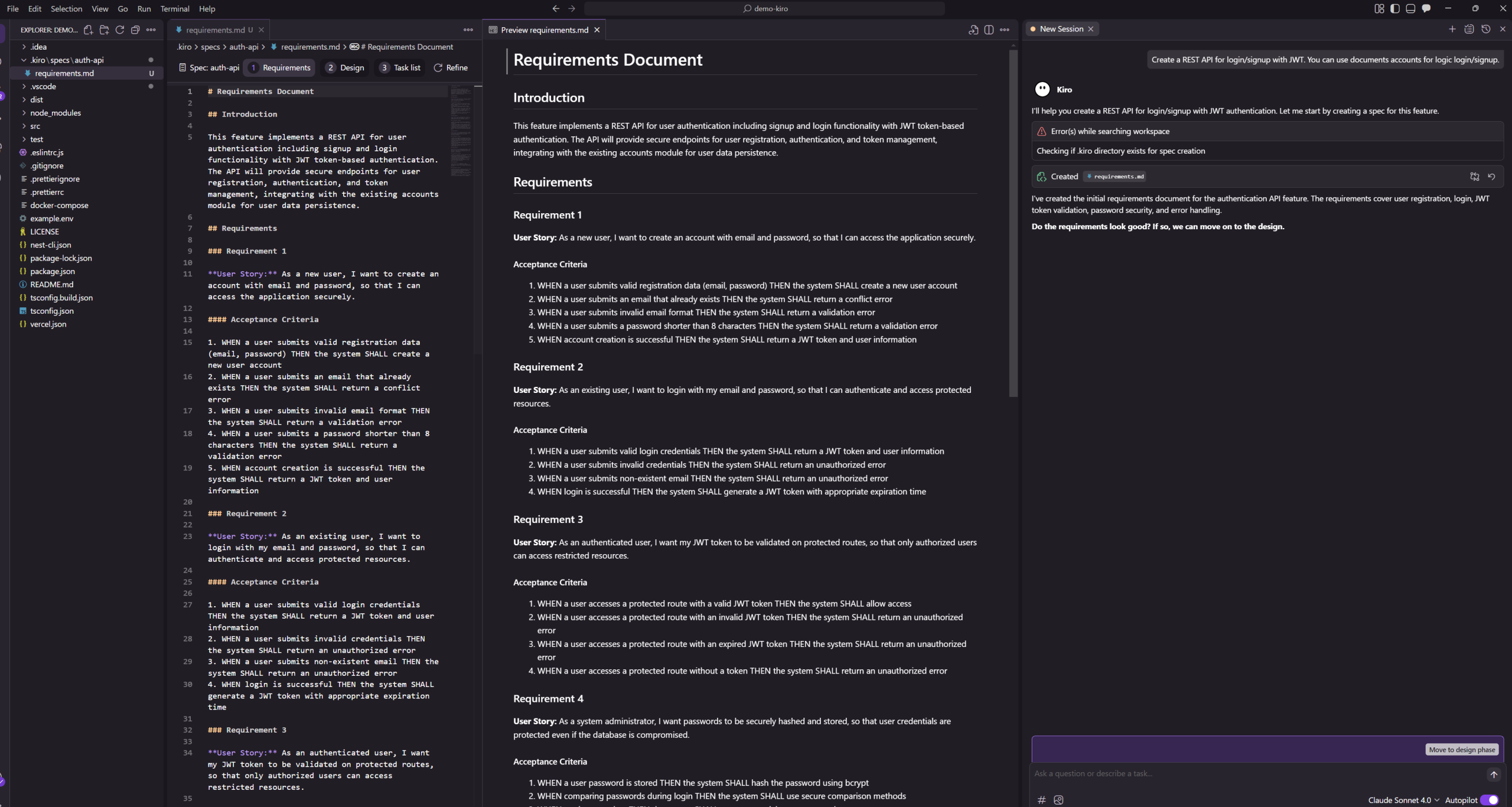
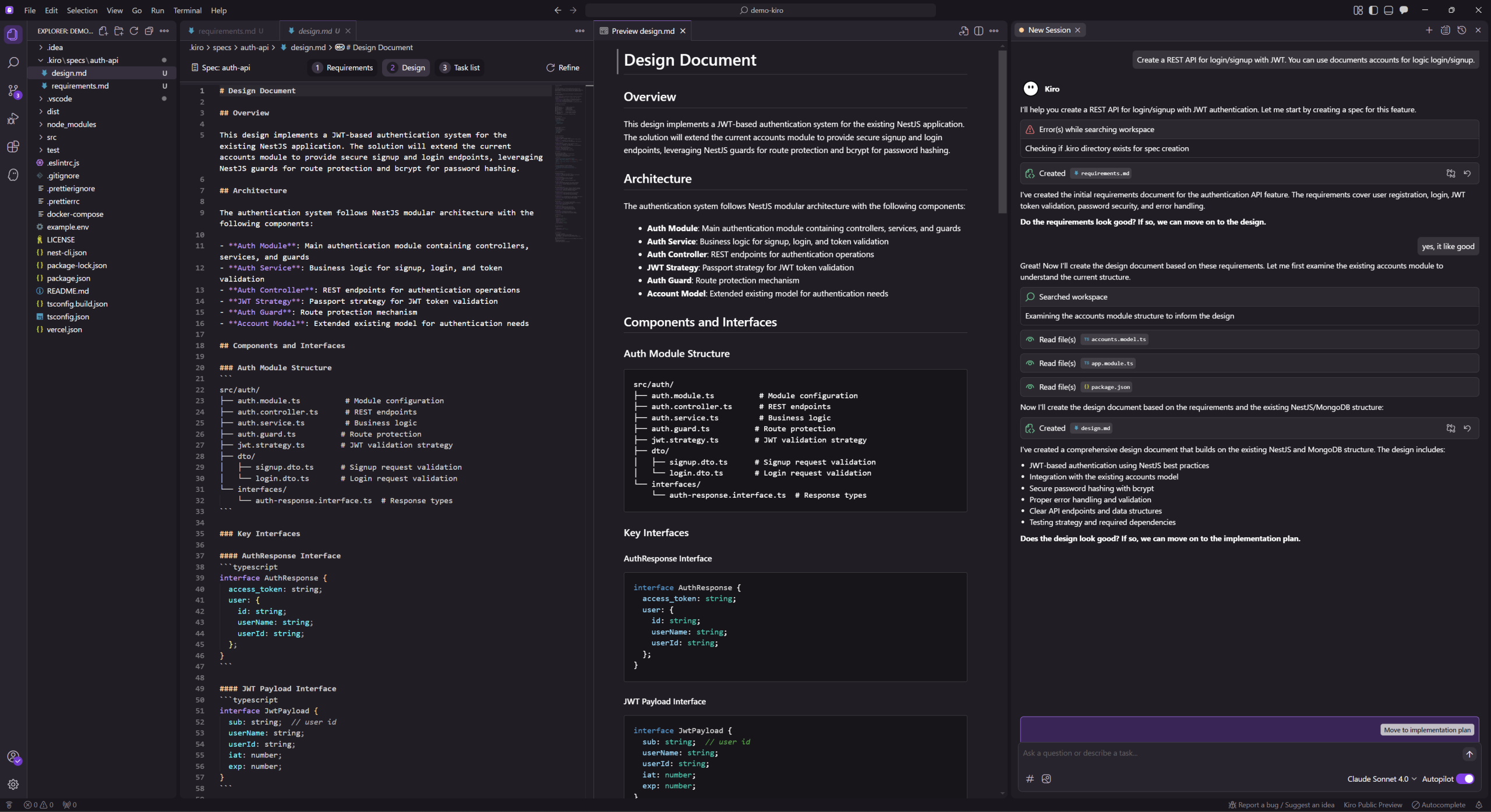
 Most AI coding tools today focus on speed & productivity for individuals. Cursor, Copilot, and Windsurf enable a single developer to prototype an MVP in days. But when it’s time to scale or work in a team, these prototypes often become liabilities:
Most AI coding tools today focus on speed & productivity for individuals. Cursor, Copilot, and Windsurf enable a single developer to prototype an MVP in days. But when it’s time to scale or work in a team, these prototypes often become liabilities: