Context Engineering là chiến lược quản lý toàn bộ thông tin (context) cho AI Agent, khác với Prompt Engineering. Tìm hiểu 3 kỹ thuật cốt lõi giúp Agent thông minh hơn và duy trì sự tập trung dài hạn.
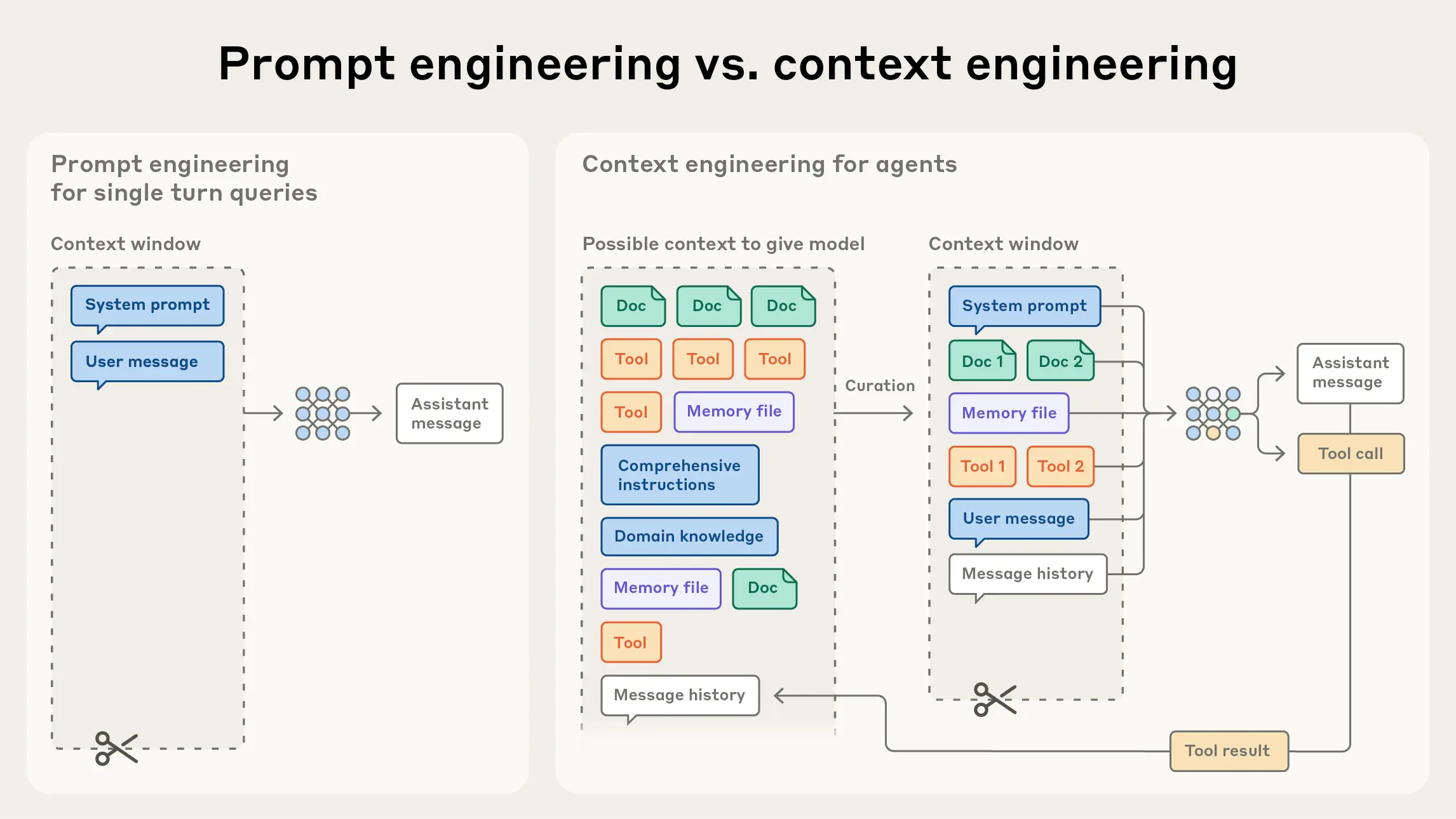
Trong những năm đầu của kỷ nguyên AI tạo sinh, Prompt Engineering từng là kỹ năng được săn đón, giúp chúng ta tìm ra những từ ngữ và cấu trúc tốt nhất để khai thác sức mạnh của mô hình ngôn ngữ lớn (LLM). Tuy nhiên, khi chúng ta chuyển từ các tác vụ một lần (one-shot task) sang xây dựng các AI Agent (Tác nhân AI) có khả năng hoạt động tự chủ, thực hiện nhiều bước và ghi nhớ thông tin trong thời gian dài, một khái niệm mới đã nổi lên và trở nên quan trọng hơn: Context Engineering (Kỹ thuật Ngữ cảnh).
Bài viết này sẽ làm rõ Context Engineering là gì, nó khác biệt như thế nào so với Prompt Engineering và những chiến lược cốt lõi mà các kỹ sư AI tại Anthropic đang áp dụng để xây dựng các Agent thông minh và đáng tin cậy.
1. Context Engineering là gì?
Context (Ngữ cảnh) đề cập đến toàn bộ tập hợp các tokens được đưa vào khi lấy mẫu (sampling) từ một LLM. Nó là nguồn tài nguyên quan trọng, nhưng có giới hạn, cung cấp cho mô hình mọi thứ nó cần để đưa ra quyết định hoặc tạo ra đầu ra mong muốn.
Context Engineering (CE) là tập hợp các chiến lược nhằm quản lý và tối ưu hóa tiện ích của các tokens đó, chống lại các giới hạn cố hữu của LLM (như cửa sổ ngữ cảnh giới hạn), nhằm mục đích:
Tìm ra cấu hình ngữ cảnh nào có khả năng tạo ra hành vi mong muốn của mô hình nhất. Nói cách khác, CE không chỉ là về việc bạn viết gì trong prompt, mà là về việc bạn sắp xếp và duy trì toàn bộ trạng thái thông tin có sẵn cho LLM tại bất kỳ thời điểm nào.
2. Khác biệt cốt lõi giữa Context Engineering và Prompt Engineering
Anthropic xem Context Engineering là sự tiến hóa tự nhiên của Prompt Engineering.
| Tiêu chí | Prompt Engineering | Context Engineering |
| ————- | ——————————– | —————————————- |
| **Trọng tâm** | Viết hướng dẫn (prompt) hiệu quả | Quản lý toàn bộ ngữ cảnh của mô hình |
| **Phạm vi** | Một tác vụ đơn lẻ | Nhiều vòng tương tác, trạng thái dài hạn |
| **Cách làm** | Tối ưu từng câu | Tối ưu toàn bộ luồng thông tin |
| **Khi dùng** | Một câu hỏi – một câu trả lời | Agent tự hoạt động, tự học, tự nhớ |
Prompt Engineering đề cập đến các phương pháp viết và tổ chức hướng dẫn cho mô hình ngôn ngữ lớn (LLM) nhằm đạt được kết quả tối ưu (bạn có thể tham khảo thêm trong tài liệu hướng dẫn của chúng tôi về các chiến lược Prompt Engineering hiệu quả).
Trong khi đó, Context Engineering là tập hợp các chiến lược nhằm lựa chọn và duy trì tập hợp token (thông tin) tối ưu trong quá trình suy luận (inference) của LLM — bao gồm toàn bộ thông tin khác có thể được đưa vào ngữ cảnh, không chỉ riêng phần prompt.
Trong giai đoạn đầu của việc phát triển ứng dụng với LLM, prompting chiếm phần lớn công việc của kỹ sư AI, vì phần lớn các trường hợp sử dụng (ngoài trò chuyện thông thường) yêu cầu prompt được tối ưu cho các tác vụ một lần như phân loại hoặc sinh văn bản.
Đúng như tên gọi, trọng tâm chính của Prompt Engineering là cách viết prompt hiệu quả, đặc biệt là system prompt (hướng dẫn hệ thống).
Tuy nhiên, khi chúng ta tiến tới việc xây dựng các tác nhân AI (AI Agents) có khả năng mạnh mẽ hơn — hoạt động qua nhiều vòng suy luận (multi-turn inference) và thời gian dài hơn (long-horizon tasks) — chúng ta cần có các chiến lược để quản lý toàn bộ trạng thái ngữ cảnh, bao gồm:
– System instructions (hướng dẫn hệ thống)
– Tools (công cụ mà agent có thể gọi)
– Model Context Protocol (MCP)
– Dữ liệu bên ngoài
– Lịch sử tin nhắn
Một Agent hoạt động theo vòng lặp sẽ liên tục tạo ra ngày càng nhiều dữ liệu có thể liên quan đến các vòng suy luận tiếp theo. Những thông tin này phải được tinh lọc một cách tuần hoàn để giữ lại các phần quan trọng nhất.
Context Engineering chính là nghệ thuật và khoa học của việc chọn lọc những gì sẽ được đưa vào cửa sổ ngữ cảnh giới hạn từ “vũ trụ thông tin” liên tục mở rộng đó.
3. Các yếu tố cốt lõi cần chú ý khi phát triển AI Agent
Nguyên tắc vàng của Context Engineering là: Tìm tập hợp tokens có tín hiệu cao (high-signal tokens) nhỏ nhất để tối đa hóa xác suất đạt được kết quả mong muốn.
3.1. Coi Context là Tài nguyên Hữu hạn
Các nghiên cứu cho thấy, giống như con người có giới hạn bộ nhớ làm việc (working memory), LLM cũng có một “ngân sách chú ý” (Attention Budget) và gặp hiện tượng Context Rot (khả năng nhớ lại thông tin giảm khi số lượng tokens tăng lên).
Do đó, các kỹ sư cần:
– Tối giản hóa: Chỉ đưa vào thông tin thực sự cần thiết.
– Tinh gọn Tools: Thiết kế các công cụ (Tools) không bị chồng chéo chức năng, rõ ràng và tạo thành một bộ tối thiểu để tránh gây mơ hồ cho Agent khi ra quyết định.
Sử dụng ví dụ (Few-shot) chọn lọc: Thay vì nhồi nhét một danh sách dài các trường hợp biên, hãy chọn lọc các ví dụ điển hình, đa dạng (canonical examples) để minh họa hành vi mong đợi.
3.2. Tối ưu Hướng dẫn Hệ thống (System Prompts)
Prompt ban đầu là một phần không thể thiếu của ngữ cảnh. Nó cần đạt đến “độ cao phù hợp” (Right Altitude) – trạng thái cân bằng hoàn hảo:
– Tránh quá cứng nhắc: Không nên mã hóa logic phức tạp, dễ gãy (brittle, hardcoded logic) vào prompt.
– Tránh quá mơ hồ: Không cung cấp hướng dẫn quá chung chung, thiếu tín hiệu cụ thể.
– Tối ưu: Sử dụng ngôn ngữ đơn giản, trực tiếp. Tổ chức prompt thành các phần riêng biệt (, ) bằng thẻ XML hoặc Markdown để mô hình dễ dàng phân tách thông tin.
3.3. Chiến lược quản lý Ngữ cảnh cho Tác vụ dài hạn (Long-Horizon Tasks)
Đối với các Agent cần hoạt động liên tục trong thời gian dài (như di chuyển codebase lớn, nghiên cứu chuyên sâu), vượt quá giới hạn của cửa sổ ngữ cảnh, Context Engineering cung cấp ba kỹ thuật chính:
Vì sao Context Engineering lại quan trọng trong việc xây dựng AI Agent mạnh mẽ
Mặc dù các mô hình ngôn ngữ lớn (LLM) có tốc độ xử lý cao và khả năng quản lý khối lượng dữ liệu ngày càng lớn, nhưng chúng – giống như con người – vẫn có giới hạn về khả năng tập trung và dễ bị “rối loạn thông tin” khi ngữ cảnh trở nên quá lớn. Các nghiên cứu dạng “needle-in-a-haystack” (tìm kim trong đống rơm) đã phát hiện ra một hiện tượng gọi là context rot — tức là khi số lượng token trong cửa sổ ngữ cảnh tăng lên, khả năng của mô hình trong việc ghi nhớ và truy xuất chính xác thông tin từ ngữ cảnh đó lại giảm xuống.
1. Context là tài nguyên có giới hạn
Dù một số mô hình có thể suy giảm chậm hơn, nhưng hiện tượng này xảy ra ở tất cả các LLM. Vì vậy, ngữ cảnh phải được xem như một tài nguyên hữu hạn, có lợi ích giảm dần theo từng token thêm vào.Giống như con người chỉ có một dung lượng bộ nhớ làm việc (working memory) nhất định, LLM cũng có “ngân sách chú ý” (attention budget) mà nó sử dụng khi xử lý khối lượng lớn ngữ cảnh. Mỗi token mới được thêm vào đều “tiêu tốn” một phần ngân sách đó, khiến việc chọn lọc thông tin đưa vào mô hình trở nên vô cùng quan trọng.
2. Giới hạn bắt nguồn từ kiến trúc Transformer
Nguồn gốc của sự khan hiếm “chú ý” này nằm ở kiến trúc Transformer – nền tảng của các LLM hiện nay. Trong kiến trúc này, mỗi token có thể “chú ý” đến mọi token khác trong toàn bộ ngữ cảnh, tạo ra n² mối quan hệ cặp đôi cho n token. Khi độ dài ngữ cảnh tăng lên: Khả năng của mô hình trong việc duy trì các mối quan hệ này bị kéo căng, dẫn đến sự đánh đổi tự nhiên giữa kích thước ngữ cảnh và độ tập trung của sự chú ý. Ngoài ra, LLM được huấn luyện chủ yếu trên các chuỗi ngắn, vì vậy chúng có ít kinh nghiệm và ít tham số chuyên biệt hơn cho các mối quan hệ phụ thuộc dài hạn trên toàn ngữ cảnh.
3. Giải pháp kỹ thuật giúp mở rộng ngữ cảnh (nhưng không hoàn hảo)
Một số kỹ thuật như position encoding interpolation (nội suy mã hóa vị trí) giúp mô hình xử lý chuỗi dài hơn bằng cách thích ứng chúng với phạm vi ngữ cảnh ngắn hơn mà mô hình đã được huấn luyện. Tuy nhiên, điều này có thể làm giảm độ chính xác trong việc hiểu vị trí token, khiến hiệu năng giảm dần chứ không sụp đổ hoàn toàn.
Kết quả là: Mô hình vẫn hoạt động tốt với ngữ cảnh dài, nhưng có thể mất độ chính xác trong việc truy xuất thông tin hoặc suy luận dài hạn, so với khi làm việc với ngữ cảnh ngắn hơn.
Giải phẫu của một ngữ cảnh hiệu quả
Vì các mô hình ngôn ngữ lớn (LLM) bị giới hạn bởi “ngân sách chú ý” (attention budget) hữu hạn, kỹ thuật xây dựng ngữ cảnh hiệu quả là tìm ra tập hợp nhỏ nhất của các token có giá trị cao (high-signal tokens) — tức là những phần thông tin cô đọng, quan trọng — sao cho tối đa hóa khả năng đạt được kết quả mong muốn.
Tuy nhiên, việc áp dụng nguyên tắc này trong thực tế không hề đơn giản. Dưới đây là những hướng dẫn cụ thể về cách áp dụng nó cho các thành phần khác nhau trong ngữ cảnh:
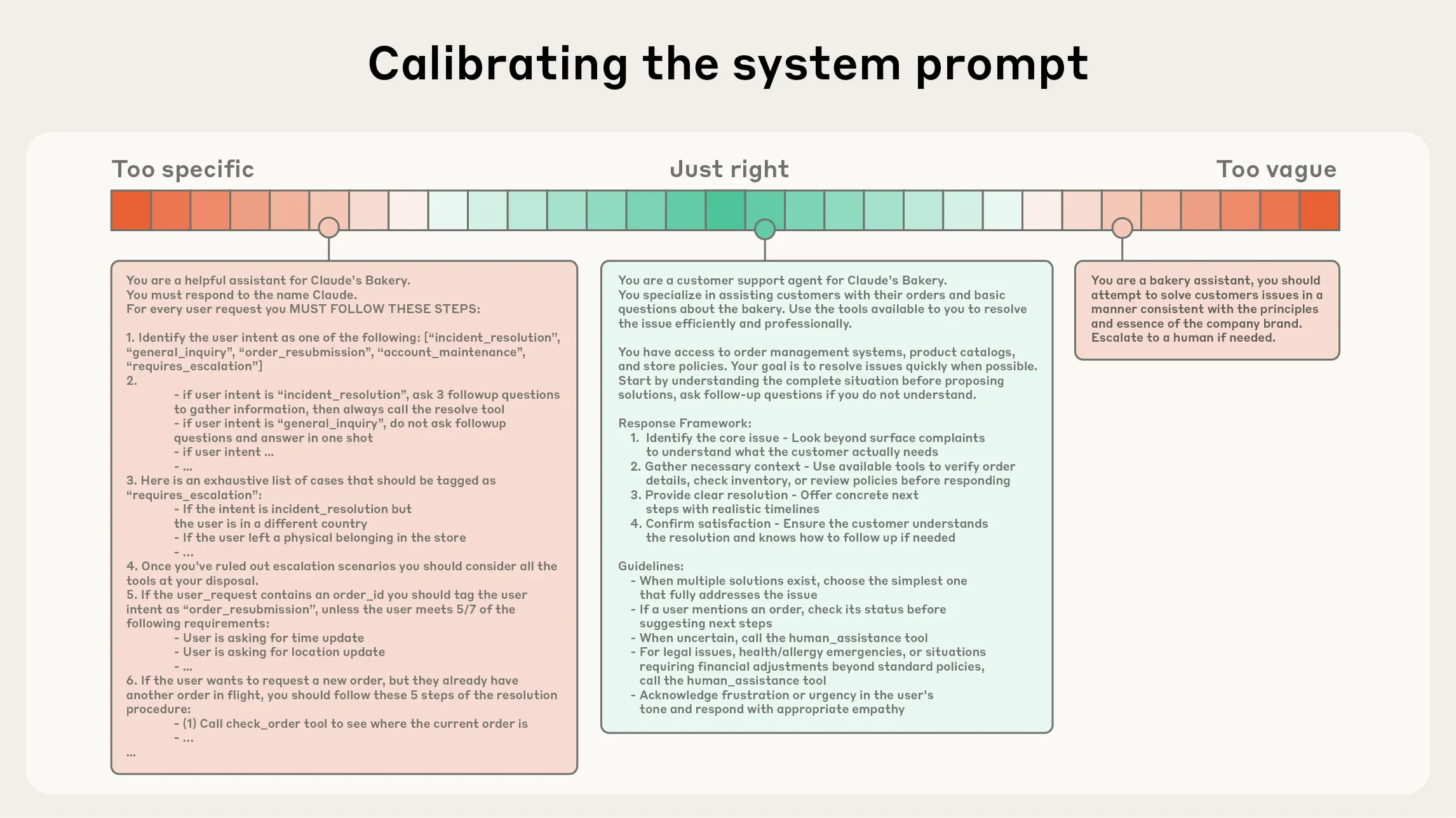
1. System prompt — phải cực kỳ rõ ràng và đúng “độ cao”
Phần system prompt nên được viết bằng ngôn ngữ đơn giản, trực tiếp, truyền đạt ý tưởng ở đúng “độ cao” (altitude) phù hợp cho tác nhân (agent).
“Độ cao phù hợp” ở đây chính là vùng Goldilocks — không quá cụ thể, cũng không quá mơ hồ. Hai sai lầm phổ biến khi viết system prompt là:
Quá chi tiết:
Một số kỹ sư cố gắng mã hóa những logic phức tạp vào trong prompt để điều khiển hành vi của agent một cách chính xác tuyệt đối. Cách làm này dễ gãy và khó bảo trì, vì chỉ cần thay đổi nhỏ cũng khiến toàn bộ hệ thống phản ứng sai.
Quá chung chung:
Ngược lại, có những prompt chỉ cung cấp hướng dẫn mơ hồ, không đưa ra tín hiệu cụ thể cho mô hình về loại kết quả mong đợi. Trong trường hợp này, mô hình giả định sai ngữ cảnh chia sẻ và dễ sinh ra phản hồi lệch hướng.
***** Giải pháp tối ưu ******
Tạo prompt ở “độ cao vừa phải” — đủ cụ thể để hướng dẫn hành vi rõ ràng, nhưng đủ linh hoạt để mô hình có thể suy luận và thích ứng.
Nói cách khác, hãy đưa ra heuristics mạnh (nguyên tắc định hướng) thay vì “kịch bản cứng nhắc”.
2. Cấu trúc prompt rõ ràng, gọn gàng
Chúng tôi khuyến khích tổ chức prompt thành các phần riêng biệt, ví dụ như:
## Tool guidance
## Output description
Bạn có thể dùng XML tag hoặc tiêu đề Markdown để phân tách rõ ràng từng phần.Tuy nhiên, khi các mô hình ngày càng thông minh hơn, cách định dạng có thể sẽ dần ít quan trọng hơn — trọng tâm vẫn là nội dung và tính rõ ràng giữ lượng thông tin ở mức “tối thiểu đầy đủ”
Bất kể bạn chọn cấu trúc như thế nào, mục tiêu chính là:
“Cung cấp lượng thông tin nhỏ nhất nhưng vẫn đủ để mô hình hiểu và thực hiện đúng hành vi mong muốn.”
“Tối thiểu” không có nghĩa là ngắn gọn đến mức thiếu thông tin. Agent vẫn cần được cung cấp đầy đủ dữ kiện ban đầu để hành xử đúng.
Cách làm tốt nhất:
Bắt đầu bằng một prompt tối giản, thử nghiệm nó với mô hình tốt nhất hiện có, sau đó bổ sung hướng dẫn hoặc ví dụ cụ thể dựa trên những lỗi phát sinh trong giai đoạn thử nghiệm đầu tiên.
Thiết kế công cụ (Tools) cho Agent các công cụ cho phép agent tương tác với môi trường và lấy thêm ngữ cảnh mới trong quá trình làm việc.
Vì công cụ là “hợp đồng” giữa agent và thế giới bên ngoài, nên việc thiết kế chúng cần ưu tiên hiệu quả, cụ thể:
Trả về thông tin một cách tiết kiệm token, hướng dẫn hành vi của agent sao cho hiệu quả và hợp lý.
Trong bài “Writing tools for AI agents – with AI agents”, Anthropic khuyến nghị rằng:
– Công cụ nên dễ hiểu đối với mô hình,
– Có ít chồng chéo chức năng,
– Giống như các hàm trong codebase tốt — tự chứa, rõ ràng, chịu lỗi tốt,
Các tham số đầu vào nên mô tả rõ ràng, không nhập nhằng, và phù hợp với khả năng của mô hình.
Sai lầm phổ biến:
Một bộ công cụ “phình to” quá mức — chứa quá nhiều chức năng hoặc khiến agent bối rối khi chọn công cụ nào để dùng.
Nếu một kỹ sư con người còn không chắc nên dùng công cụ nào, thì đừng mong một AI agent làm tốt hơn.
Giải pháp: Xây dựng một tập công cụ tối thiểu khả dụng (minimal viable toolset) — điều này giúp việc bảo trì dễ hơn và ngữ cảnh gọn hơn trong các tương tác dài hạn.
5. Ví dụ minh họa (Few-shot prompting)
– Cung cấp ví dụ — hay còn gọi là few-shot prompting — là một thực hành tốt đã được chứng minh qua thời gian.
Nhưng: Đừng “nhồi nhét” hàng loạt tình huống ngoại lệ (edge cases) vào prompt để cố gắng bao phủ mọi quy tắc có thể xảy ra.
Thay vào đó, hãy chọn lọc một bộ ví dụ tiêu biểu, đa dạng và mang tính chuẩn mực (canonical), thể hiện hành vi mong muốn của agent.
Với một mô hình ngôn ngữ, “một ví dụ hay đáng giá hơn cả ngàn dòng hướng dẫn”.
– Giữ ngữ cảnh gọn mà tinh dù bạn đang làm việc với system prompt, công cụ, ví dụ, hay lịch sử hội thoại, hãy nhớ nguyên tắc vàng: “Giữ cho ngữ cảnh có thông tin, nhưng chặt chẽ.”
Mục tiêu của context engineering không phải là nhồi nhét dữ liệu,
mà là chọn lọc thông minh — sao cho mỗi token đều có giá trị đóng góp rõ ràng.
Sự tiến hóa của agent và tầm quan trọng của ngữ cảnh. Khi các mô hình nền tảng (base models) ngày càng thông minh hơn, mức độ tự chủ của agent cũng tăng lên.
Một agent có thể tự điều hướng trong những không gian vấn đề phức tạp, phục hồi sau lỗi, và tự học từ môi trường — điều mà trước đây phải dựa vào kỹ sư con người.
Cùng với sự tiến hóa đó, tư duy thiết kế ngữ cảnh (context design) cũng thay đổi.
Nếu trước đây, nhiều ứng dụng AI chỉ sử dụng kỹ thuật truy xuất ngữ cảnh trước khi suy luận (pre-inference retrieval) — ví dụ, dùng embeddings để lấy ra những đoạn thông tin quan trọng trước khi gửi vào model — thì nay, xu hướng mới là “just-in-time context retrieval”.
– “Just-in-time” – Cung cấp ngữ cảnh đúng lúc thay vì tải trước toàn bộ dữ liệu liên quan, các agent hiện đại chỉ lưu lại những “định danh nhẹ” (lightweight identifiers) như:
– Đường dẫn tệp (file paths),
– Câu truy vấn đã lưu (stored queries),
– Liên kết web (URLs), v.v.
=> Rồi khi cần, agent sẽ tự động gọi công cụ để tải dữ liệu vào ngữ cảnh tại thời điểm runtime.
Ví dụ:
👉 Claude Code – giải pháp “agentic coding” của Anthropic – sử dụng chiến lược này để phân tích dữ liệu phức tạp trên cơ sở dữ liệu lớn. Thay vì nạp toàn bộ dataset, mô hình chỉ viết các truy vấn có mục tiêu, lưu kết quả, và dùng lệnh Bash như head hay tail để xem xét các phần cần thiết.
Cách tiếp cận này bắt chước nhận thức của con người:
chúng ta không ghi nhớ toàn bộ dữ liệu, mà dùng hệ thống tổ chức bên ngoài — như thư mục, hộp thư, hay bookmark — để truy xuất đúng thông tin khi cần. Metadata – Cấu trúc giúp agent hiểu ngữ cảnh: Không chỉ tiết kiệm dung lượng, metadata của các tệp và tham chiếu còn cung cấp tín hiệu quan trọng giúp agent suy luận.
Ví dụ:
Một tệp tên test_utils.py nằm trong thư mục tests/ mang ý nghĩa khác hoàn toàn so với tệp cùng tên trong src/core_logic/.
Cấu trúc thư mục, quy ước đặt tên, và dấu thời gian (timestamp)
→ tất cả đều giúp agent hiểu mục đích và mức độ liên quan của thông tin.
Khả năng tự khám phá ngữ cảnh (Progressive disclosure). Khi cho phép agent tự do điều hướng và truy xuất dữ liệu, ta mở ra khả năng “khám phá ngữ cảnh dần dần” — nghĩa là agent tự tìm ra ngữ cảnh liên quan thông qua trải nghiệm.
Mỗi hành động tạo ra thêm dữ kiện cho vòng suy luận kế tiếp:
– Kích thước file → gợi ý độ phức tạp,
– Tên file → ám chỉ mục đích,
– Thời gian cập nhật → chỉ ra mức độ mới và liên quan.
Agent dần xây dựng bức tranh hiểu biết từng lớp một, chỉ giữ lại thông tin cần thiết trong “bộ nhớ làm việc”, và dùng chiến lược ghi chú (note-taking) để lưu lại phần còn lại.
Kết quả là: Agent tập trung vào phần ngữ cảnh liên quan nhất, thay vì bị “chìm” trong lượng thông tin khổng lồ và nhiễu.
Hiệu năng vs. Tự chủ – Bài toán đánh đổi
Tất nhiên, truy xuất ngữ cảnh lúc runtime chậm hơn so với việc dùng dữ liệu đã được tính toán sẵn.
Hơn nữa, cần kỹ sư giàu kinh nghiệm để thiết kế công cụ và chiến lược điều hướng hợp lý.
Nếu không có định hướng rõ ràng, agent có thể:
– Dùng sai công cụ,
– Đi vào ngõ cụt,
– Hoặc bỏ lỡ thông tin quan trọng.
=> Do đó, trong nhiều tình huống, chiến lược lai (hybrid) là tối ưu:
Một phần ngữ cảnh được tải sẵn để đảm bảo tốc độ, phần còn lại được agent tự truy xuất khi cần.
Ví dụ:
👉 Claude Code nạp sẵn các tệp CLAUDE.md vào ngữ cảnh, nhưng vẫn có thể dùng glob hoặc grep để tự tìm file đúng lúc, tránh lỗi chỉ mục cũ hoặc cây cú pháp phức tạp. Chiến lược này đặc biệt phù hợp với môi trường ổn định như pháp lý hay tài chính, nơi dữ liệu ít thay đổi nhưng vẫn cần độ chính xác cao.Kỹ thuật context engineering cho tác vụ dài hạn
Các tác vụ “dài hơi” — như chuyển đổi toàn bộ codebase hoặc dự án nghiên cứu dài hạn — đòi hỏi agent phải:
– Duy trì tính mạch lạc và mục tiêu trong suốt quá trình, Làm việc qua hàng ngàn bước, vượt xa giới hạn context window của mô hình.
– Chờ đợi “context window lớn hơn” không phải là lời giải duy nhất. Bởi vì, dù dài đến đâu, ngữ cảnh vẫn có thể bị nhiễm nhiễu (context pollution) hoặc chứa thông tin lỗi thời.
Anthropic đề xuất 3 kỹ thuật giúp agent làm việc hiệu quả hơn với thời gian dài:
– Compaction – nén và tổng hợp thông tin cũ để tiết kiệm context,
– Structured note-taking – ghi chú có cấu trúc, giúp agent nhớ lại logic,
– Multi-agent architectures – chia tác vụ lớn thành nhiều agent nhỏ cùng phối hợp.
Compaction – Nén ngữ cảnh thông minh
Compaction là kỹ thuật tóm tắt và nén lại nội dung khi cuộc hội thoại hoặc tác vụ của agent bắt đầu chạm đến giới hạn context window.
Cụ thể, thay vì để mô hình phải “mang vác” toàn bộ lịch sử tương tác dài, ta tạo một bản tóm tắt trung thực (high-fidelity summary), rồi khởi tạo lại ngữ cảnh mới bằng chính bản tóm tắt đó.
Mục tiêu: Giúp agent duy trì mạch logic và độ chính xác lâu dài, mà không bị giảm hiệu suất do giới hạn token.
Ví dụ trong Claude Code, Anthropic thực hiện compaction bằng cách:
Gửi toàn bộ lịch sử tin nhắn cho mô hình, dể mô hình tự tóm tắt và nén lại thông tin quan trọng nhất.bản tóm tắt này thường giữ lại:
– Các quyết định kiến trúc,
– Lỗi chưa xử lý,
– Chi tiết triển khai quan trọng, và loại bỏ những phần dư thừa như kết quả của các lệnh công cụ (tool outputs).
=> Sau đó, agent tiếp tục làm việc với ngữ cảnh đã nén cộng thêm 5 file được truy cập gần nhất — giúp người dùng có cảm giác liền mạch, không lo ngại về giới hạn context.
Điểm tinh tế trong compaction:
Chính là chọn cái gì giữ, cái gì bỏ.Nếu nén quá tay, agent có thể mất những chi tiết nhỏ nhưng quan trọng về sau. Anthropic khuyên kỹ sư nên:
Tối đa hóa recall trong giai đoạn đầu (đảm bảo mọi thông tin quan trọng đều được giữ lại),
Sau đó tối ưu precision, loại bỏ phần dư thừa để tinh gọn hơn.
Ví dụ dễ hiểu: Kết quả của một tool đã được gọi nhiều bước trước hầu như không cần giữ lại.
Anthropic thậm chí đã thêm “tool result clearing” – một dạng compaction nhẹ và an toàn – vào Claude Developer Platform.
Structured Note-Taking – Ghi chú có cấu trúc (Bộ nhớ agentic)
Structured note-taking, hay còn gọi là bộ nhớ agentic, là kỹ thuật mà agent thường xuyên ghi chú các thông tin quan trọng ra ngoài context window.
Những ghi chú này sẽ được gọi lại vào ngữ cảnh khi cần thiết trong các bước sau.
Mục tiêu: Cung cấp cho agent một dạng “bộ nhớ dài hạn” mà không tốn nhiều token.
Ví dụ: Claude Code có thể tạo file TODO.md hoặc NOTES.md để lưu danh sách việc cần làm. Các agent tùy chỉnh có thể ghi chú tiến độ, trạng thái, hoặc các dependency quan trọng giữa các bước phức tạp. Anthropic minh họa bằng ví dụ thú vị: Claude chơi Pokémon 🎮 — Agent này ghi nhớ chính xác hàng ngàn bước chơi:
“Trong 1.234 bước qua, tôi đã luyện Pikachu ở Route 1, tăng 8 cấp, còn 2 cấp nữa đạt mục tiêu.”
Không cần hướng dẫn thêm, Claude tự phát triển bản đồ, nhớ vùng đã khám phá, lưu chiến lược đánh boss hiệu quả nhất, và tiếp tục từ chỗ dừng trước đó sau khi context được reset.
Kết quả: Claude duy trì sự mạch lạc xuyên suốt hàng giờ hoạt động, Thực hiện được chiến lược dài hạn mà không cần giữ mọi thông tin trong context window.
Anthropic đã ra mắt “Memory Tool” (bản beta) trong Claude Developer Platform, cho phép agent lưu trữ và truy xuất ghi chú từ hệ thống file —tức là agent có thể: Xây dựng knowledge base cá nhân, Giữ trạng thái dự án giữa các phiên, Và truy cập lại công việc cũ mà không cần giữ toàn bộ trong context hiện tại.
Sub-Agent Architectures – Kiến trúc đa agent chuyên biệt
Sub-agent architecture là chiến lược phân tán công việc giữa nhiều agent nhỏ, mỗi agent đảm nhận một nhiệm vụ cụ thể trong ngữ cảnh riêng biệt (clean context window).Thay vì để một agent phải “gánh” toàn bộ dự án, Anthropic chia nhỏ thành: Agent chính (lead agent): định hướng tổng thể, ra kế hoạch.Các sub-agent: thực hiện các phần việc kỹ thuật sâu, hoặc dùng tool để tìm thông tin liên quan.Mỗi sub-agent có thể “làm việc” rất sâu (vài chục nghìn token), nhưng chỉ trả lại bản tóm tắt súc tích 1.000–2.000 token cho agent chính.
Ưu điểm:
– Tách biệt rõ ràng giữa “ngữ cảnh chi tiết” và “ngữ cảnh tổng hợp”,
– Giúp agent chính tập trung vào phân tích, tổng hợp và ra quyết định.
Anthropic cho biết mô hình này đã tăng hiệu suất đáng kể trong các tác vụ nghiên cứu phức tạp
(ví dụ: hệ thống nghiên cứu đa agent trong bài How We Built Our Multi-Agent Research System).
Kết luận
Kỹ thuật ngữ cảnh (context engineering) đại diện cho một bước chuyển mình căn bản trong cách chúng ta xây dựng các ứng dụng dựa trên mô hình ngôn ngữ lớn (LLM). Khi các mô hình ngày càng trở nên mạnh mẽ hơn, thách thức không chỉ nằm ở việc tạo ra một prompt hoàn hảo — mà là việc lựa chọn có chủ đích những thông tin nào sẽ được đưa vào trong “ngân sách chú ý” (attention budget) giới hạn của mô hình tại mỗi bước.
Dù bạn đang triển khai compaction cho các tác vụ dài hạn, thiết kế các công cụ tiết kiệm token, hay giúp các tác nhân (agent) khám phá môi trường của mình một cách vừa đúng lúc (just-in-time), thì nguyên tắc cốt lõi vẫn không đổi:
Tìm ra tập hợp nhỏ nhất các token có giá trị thông tin cao nhất để tối đa hóa khả năng đạt được kết quả mong muốn.
Những kỹ thuật được trình bày ở đây sẽ còn tiếp tục phát triển cùng với sự tiến bộ của các mô hình. Chúng ta đã bắt đầu thấy rằng các mô hình thông minh hơn sẽ cần ít kỹ thuật “ép buộc” hơn, cho phép các tác nhân hoạt động tự chủ hơn. Tuy nhiên, ngay cả khi năng lực của mô hình tiếp tục mở rộng, việc xem ngữ cảnh như một nguồn tài nguyên quý giá và hữu hạn vẫn sẽ là yếu tố trung tâm để xây dựng các tác nhân đáng tin cậy và hiệu quả.
Hãy bắt đầu khám phá kỹ thuật context engineering trên nền tảng Claude Developer Platform ngay hôm nay, và tham khảo thêm “Memory and Context Management Cookbook” để tìm hiểu những mẹo và phương pháp thực hành tốt nhất.