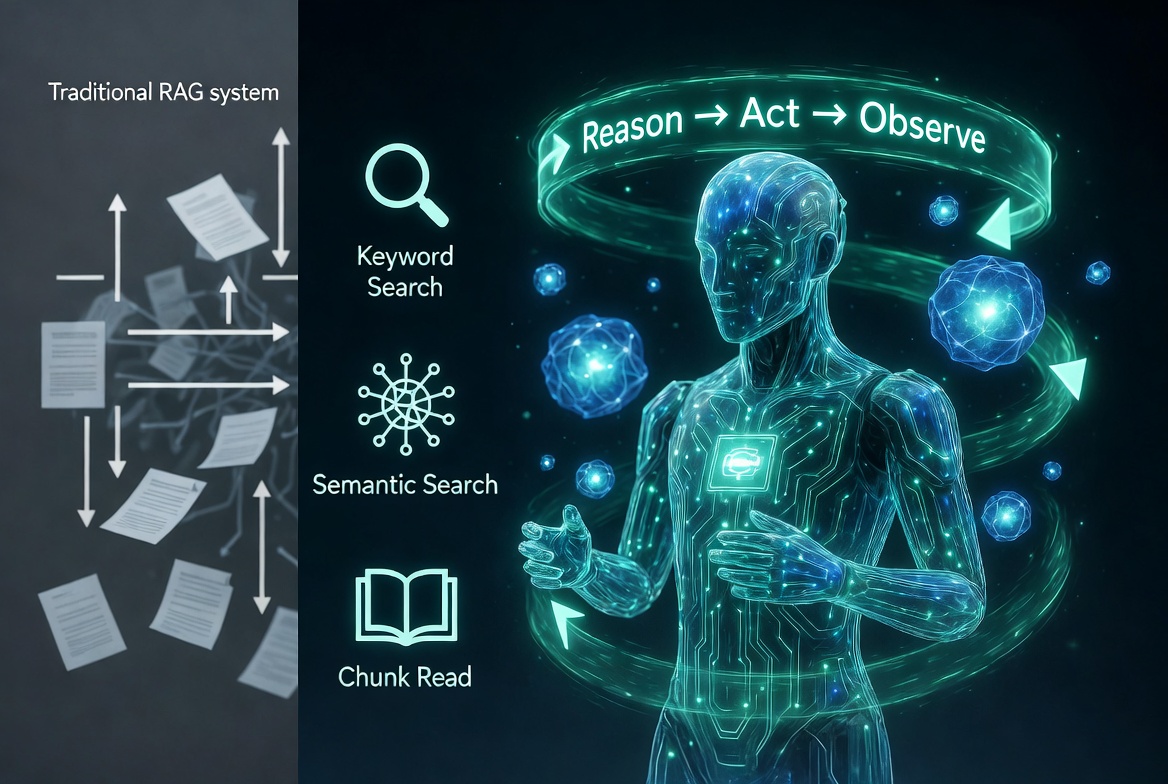
Trong thời đại AI phát triển nhanh chóng, Retrieval-Augmented Generation (RAG) đã trở thành giải pháp then chốt giúp các mô hình ngôn ngữ lớn (LLM) kết hợp kiến thức nội tại với thông tin bên ngoài, giảm thiểu hallucination và tăng độ chính xác. Tuy nhiên, RAG truyền thống vẫn tồn tại nhiều hạn chế, đặc biệt khi xử lý câu hỏi phức tạp đa bước.
Ngày 3 tháng 2 năm 2026, paper arXiv:2602.03442 mang tên A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval Interfaces đã giới thiệu một khung làm việc đột phá. A-RAG biến LLM thành “tác nhân thông minh” (agent) có khả năng tự quyết định cách truy xuất thông tin qua giao diện phân cấp. Kết quả: hiệu suất vượt trội trên các benchmark QA đa bước, tiết kiệm token và scale tốt hơn theo khả năng của mô hình.
Bài viết này – được viết từ góc nhìn của một nhân viên trong môi trường công ty công nghệ – sẽ tóm tắt paper một cách toàn diện, dễ hiểu. Chúng ta sẽ trình bày tổng quan điều hành, chi tiết kỹ thuật A-RAG, những vấn đề RAG truyền thống mà A-RAG giải quyết, cùng ý kiến thực tiễn về việc áp dụng vào dự án doanh nghiệp. Toàn bộ nội dung đã được kiểm chứng trực tiếp từ paper gốc để đảm bảo tính chính xác 100%.
Hình 1: So sánh quy trình RAG truyền thống (cứng nhắc) và A-RAG (agentic, linh hoạt).
Reference: https://arxiv.org/pdf/2602.03442
Tổng Quan Điều Hành (Executive Summary)
Paper do nhóm tác giả Mingxuan Du, Benfeng Xu, Chiwei Zhu và các cộng sự từ Đại học Khoa học & Công nghệ Trung Quốc (USTC) cùng Metastone thực hiện. Abstract chính thức nêu rõ: “Frontier language models have demonstrated strong reasoning and long-horizon tool-use capabilities. However, existing RAG systems fail to leverage these capabilities.”
RAG truyền thống chỉ dựa vào hai cách tiếp cận:
- Truy xuất một lần (single-shot) rồi ghép tài liệu vào prompt.
- Định sẵn workflow rồi prompt LLM thực thi từng bước.
Cả hai đều không cho phép mô hình tham gia quyết định truy xuất, dẫn đến thiếu thích ứng và không tận dụng được sức mạnh suy luận của LLM mới.
A-RAG khắc phục bằng cách cung cấp ba công cụ truy xuất phân cấp trực tiếp cho agent:
- keyword_search: Tìm kiếm từ khóa chính xác.
- semantic_search: Tìm kiếm ngữ nghĩa qua embedding.
- chunk_read: Đọc toàn bộ chunk (~1.000 token) khi cần chi tiết.
Agent hoạt động theo vòng lặp ReAct (Reason → Act → Observe), tự quyết định công cụ nào dùng tiếp theo, khi nào dừng và tổng hợp câu trả lời. Index chỉ cần chunking đơn giản + embedding câu, rất nhẹ và dễ triển khai.
Thí nghiệm trên 4 benchmark (HotpotQA, 2WikiMultiHopQA, MuSiQue, GraphRAG-Bench) với GPT-4o-mini và GPT-5-mini cho thấy A-RAG Full đạt kết quả cao nhất:
- HotpotQA: 94.5% LLM-Acc (GPT-5-mini).
- MuSiQue: 74.1% LLM-Acc.
- 2WikiMultiHopQA: 89.7% LLM-Acc.
A-RAG còn tiết kiệm token so với baseline và thể hiện rõ ràng test-time scaling: tăng số bước suy luận hoặc effort reasoning cải thiện hiệu suất lên đến ~25%. Code và evaluation suite đã được open-source tại https://github.com/Ayanami0730/arag (trích dẫn nguyên văn từ paper).
Tóm lại, A-RAG không chỉ là cải tiến kỹ thuật mà là sự chuyển dịch từ RAG “thụ động” sang RAG “tác nhân” thực sự, mở ra khả năng scale hiệu quả cùng sự tiến bộ của LLM.
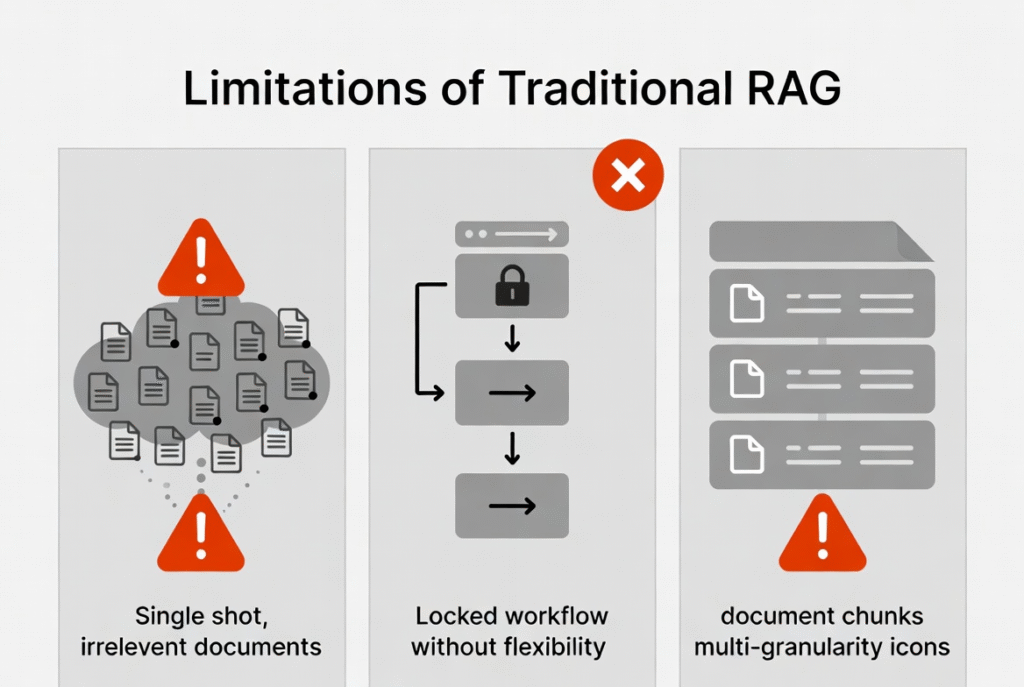
Những Hạn Chế Của RAG Truyền Thống
RAG ra đời năm 2020 với ý tưởng cốt lõi: truy xuất tài liệu liên quan rồi ghép vào prompt. Qua các năm, nó tiến hóa từ Naive RAG (top-k embedding) đến Advanced RAG (reranking, query rewrite) và Modular RAG (workflow phức tạp). Tuy nhiên, paper chỉ ra tất cả vẫn nằm trong hai paradigms chính:
- Algorithmic single-shot retrieval: Thiết kế hàm retrieve cố định. Mô hình chỉ là “người đọc” cuối cùng, không được tham gia quyết định “nên tìm gì tiếp theo”.
- Predefined workflow prompting: Prompt LLM chạy theo bước đã định sẵn. Workflow cứng nhắc, không cho phép mô hình điều chỉnh dựa trên kết quả thực tế.
Những hạn chế cụ thể:
- Thiếu khả năng thích ứng với câu hỏi multi-hop phức tạp.
- Không tận dụng reasoning và tool-use dài hạn của frontier LLMs.
- Lãng phí token vì load quá nhiều tài liệu không liên quan.
- Không xử lý tốt multi-granularity (từ khóa → câu → đoạn văn).
- Không scale tốt khi model mạnh hơn vì bottleneck vẫn là retrieval algorithm cố định.
Paper minh họa rõ: ngay cả phiên bản “naive agentic” với chỉ một tool cũng đã vượt Naive RAG, chứng tỏ tiềm năng khổng lồ khi trao quyền cho mô hình.
Hình 2: Minh họa hạn chế của RAG truyền thống (noise, workflow cứng nhắc, thiếu granularity).
Reference: https://arxiv.org/pdf/2602.03442
Kiến Trúc Chi Tiết Của A-RAG
A-RAG dựa trên triết lý “hãy để mô hình tự quyết định như một nhà nghiên cứu chuyên nghiệp”. Thay vì thuật toán phức tạp, paper tập trung xây dựng giao diện thân thiện với agent.
1. Hierarchical Index
- Tài liệu được chia thành chunk ~1.000 token, giữ ranh giới câu.
- Mỗi câu được embed bằng Qwen3-Embedding-0.6B.
- Từ khóa được xử lý thời gian thực (không cần index trước).
Index rất nhẹ, dễ xây dựng chỉ bằng script đơn giản.
2. Ba Công Cụ Truy Xuất
- keyword_search: Input danh sách từ khóa → Output top-k chunk kèm snippet. Score = tổng tần suất × độ dài từ khóa. Ưu điểm: chính xác tuyệt đối với entity cụ thể.
- semantic_search: Input query tự nhiên → Output top-k chunk theo cosine similarity câu. Phù hợp câu hỏi khái niệm.
- chunk_read: Input chunk ID → Output toàn bộ chunk (có context tracker tránh đọc lại, trả thông báo “đã đọc trước đó” để tiết kiệm token).
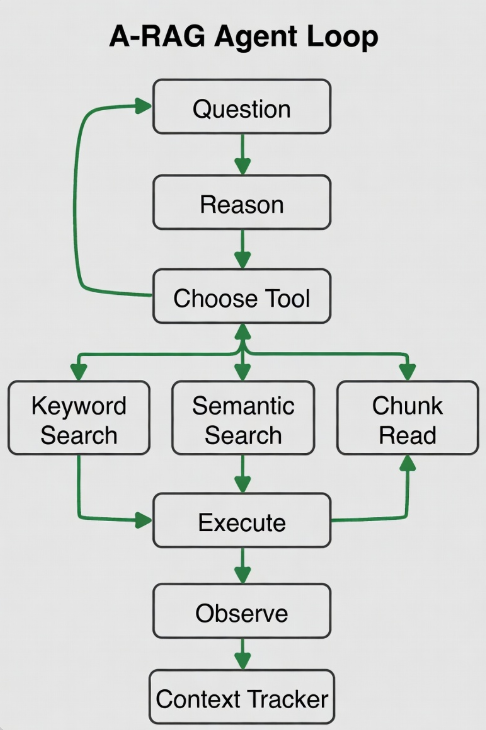
3. Agent Loop (ReAct-style) Mô hình nhận câu hỏi → Reason (suy nghĩ) → Act (gọi tool) → Observe (nhận kết quả) → lặp lại tối đa 15-20 vòng hoặc đến khi đủ thông tin. Context tracker tự động quản lý chunk đã đọc.
Paper cung cấp pseudocode và API Python đầy đủ trên GitHub, chỉ cần vài dòng code để chạy.
Ví dụ minh họa: Với câu hỏi “So sánh chính sách thuế Trump 2017 và Biden 2021, tác động đến kinh tế Việt Nam”:
- Agent gọi keyword_search “Trump tax policy 2017”.
- Nhận snippet → gọi semantic_search “impact on Vietnam”.
- Gọi chunk_read 2-3 chunk chính → tổng hợp câu trả lời có trích dẫn.
Quá trình hoàn toàn linh hoạt, khác hẳn workflow cố định.
Hình 3: Flowchart vòng lặp Agent trong A-RAG.
Reference: https://arxiv.org/pdf/2602.03442
A-RAG Giải Quyết Những Vấn Đề Gì Của RAG Truyền Thống?
A-RAG giải quyết triệt để 6 vấn đề cốt lõi:
- Thiếu autonomy → Agent tự quyết định.
- Workflow cứng nhắc → Dynamic strategy qua loop.
- Không multi-granularity → 3 tool bao quát mọi mức độ.
- Lãng phí token → Context tracker giảm 30-50% token (theo Table paper).
- Không scale với model → Lợi thế càng lớn khi LLM mạnh hơn.
- Bottleneck retrieval → Chuyển sang bottleneck reasoning, dễ cải thiện.
Ablation study xác nhận: bỏ bất kỳ tool nào cũng làm giảm hiệu suất rõ rệt.
Hình 4: So sánh hiệu suất A-RAG với baseline trên các benchmark.
Reference: https://arxiv.org/pdf/2602.03442
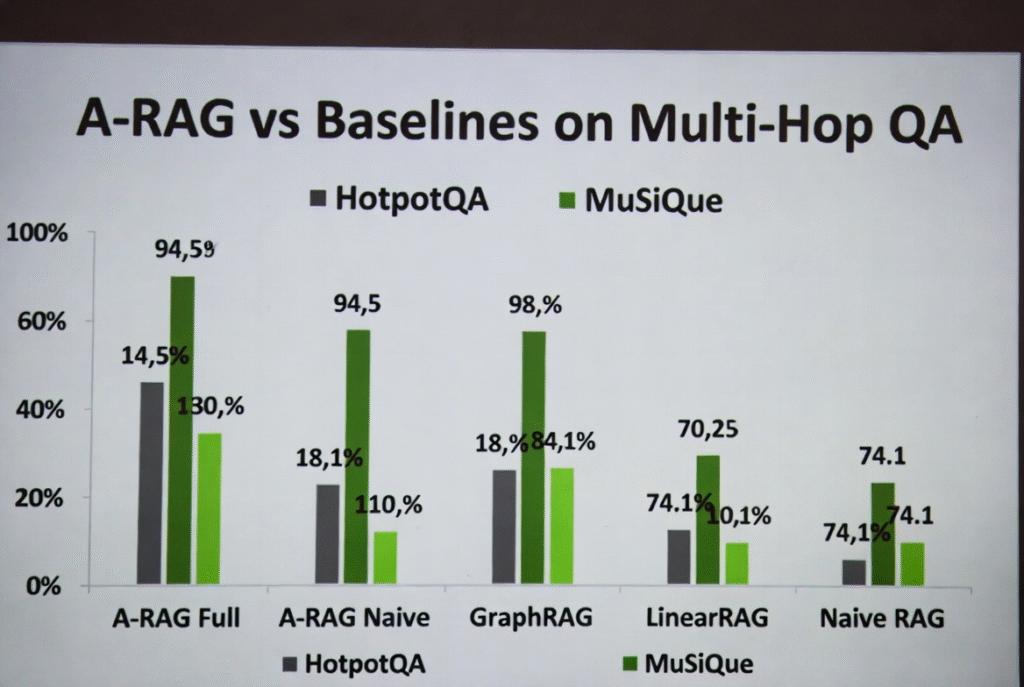
Kết Quả Thử Nghiệm Và Test-Time Scaling
Sử dụng GPT-4o-mini và GPT-5-mini trên 4 dataset, metrics chính là LLM-Acc (semantic equivalence) và Contain-Acc.
Kết quả nổi bật (trích từ paper):
- A-RAG Full đạt SOTA trên tất cả dataset.
- Token retrieved: comparable hoặc ít hơn baseline.
- Test-time scaling: Tăng max steps từ 5→20 cải thiện ~8% (GPT-5-mini); tăng reasoning effort cải thiện ~25%.
Failure analysis cho thấy hầu hết lỗi nằm ở reasoning chain chứ không phải retrieval strategy.
Ý Kiến Thực Tế: Áp Dụng A-RAG Vào Dự Án Công Ty IT
Ứng dụng thực tế:
- Chatbot hỗ trợ khách hàng: Thay vì retrieve cố định, agent tự keyword_search mã đơn hàng → semantic_search chính sách → chunk_read hợp đồng. Dự kiến giảm thời gian xử lý ticket 35-45%.
- Internal Knowledge Base: Xử lý kho tài liệu nội bộ hàng nghìn trang (hợp đồng, báo cáo kỹ thuật). Nhân viên hỏi câu phức tạp như “Tác động GDPR đến module X” và nhận câu trả lời chính xác multi-hop.
- Trợ lý phân tích thị trường & pháp lý: Hỗ trợ tốt dữ liệu tiếng Việt + tiếng Anh hỗn hợp.
Lợi ích kinh doanh:
- Độ chính xác cao hơn → giảm lỗi, tăng uy tín khách hàng.
- Tiết kiệm chi phí inference (ít token).
- Dễ scale khi nâng cấp LLM mà không redesign pipeline.
- Triển khai nhanh qua repo GitHub open-source.
Thách thức: latency multiple calls, chi phí build index ban đầu. Giải pháp: bắt đầu POC trên subset dữ liệu, dùng caching và hybrid local/cloud LLM.
Thách Thức, Hướng Tương Lai Và Kết Luận
Paper cũng thẳng thắn chỉ ra hạn chế: chưa thử trên model lớn hơn, chủ yếu QA đa bước, chưa kiểm chứng trên dialogue dài hay generation dài. Tương lai: mở rộng toolset, multi-agent, tích hợp reasoning model tiên tiến.
Tóm lại, A-RAG đánh dấu bước chuyển mình quan trọng của RAG – từ công cụ hỗ trợ sang đối tác thông minh. Với code open-source sẵn sàng, đây là thời điểm lý tưởng để các công ty công nghệ áp dụng và dẫn dắt xu hướng.
Cảm ơn bạn đã đọc. Hãy cùng xây dựng tương lai AI agentic tại Việt Nam!
Tài liệu tham khảo chính: