

Xin chào, tôi là Kakeya, đại diện của công ty Scuti.
Công ty chúng tôi chuyên cung cấp các dịch vụ như phát triển phần mềm offshore và phát triển theo hình thức Labo tại Việt Nam, cũng như giải pháp AI tạo sinh. Gần đây, chúng tôi rất vinh dự khi nhận được nhiều yêu cầu phát triển hệ thống kết hợp với AI tạo sinh.
Bạn đã từng nghe đến Tesseract OCR chưa? Đây là một công cụ ngày càng được nhắc đến nhiều, nhưng vẫn có nhiều người chưa hiểu rõ về nó hoặc chưa chắc chắn liệu nó có phù hợp với nhu cầu của mình hay không. Một số người có thể cảm thấy quá trình cài đặt hơi phức tạp và lo lắng liệu họ có thể sử dụng nó một cách hiệu quả hay không. Nếu bạn cũng đang có những băn khoăn đó, thì Tesseract OCR chính là giải pháp hoàn hảo dành cho bạn.
Tesseract OCR là một công cụ OCR mã nguồn mở có khả năng trích xuất văn bản từ hình ảnh. Nó hỗ trợ hơn 100 ngôn ngữ và hoàn toàn miễn phí. Hơn nữa, nó có thể tích hợp dễ dàng với Python, giúp mở rộng khả năng ứng dụng cho nhiều mục đích khác nhau.
Trong bài viết này, chúng tôi sẽ hướng dẫn bạn một cách chi tiết về Tesseract OCR, từ kiến thức cơ bản, cách cài đặt, các trường hợp ứng dụng thực tế, đến so sánh với công nghệ mới nhất LLMWhisperer. Sau khi đọc xong bài viết này, chắc chắn bạn sẽ làm chủ được Tesseract OCR!
Nào, hãy cùng khám phá thế giới của Tesseract OCR nhé!
Tesseract OCR là gì?

Nếu bạn muốn tìm hiểu trước về AI-OCR, hãy xem bài viết này trước nhé.
Bài viết liên quan: AI OCR là gì? Giải thích chi tiết về công nghệ mới nhất và các trường hợp ứng dụng trong ngành
Tổng quan về Tesseract OCR
Tesseract OCR là một công cụ OCR mã nguồn mở do Google phát triển. Vì được cung cấp miễn phí, nó được nhiều công ty và nhà phát triển sử dụng rộng rãi. Công cụ này hỗ trợ hơn 100 ngôn ngữ và là một công cụ mạnh mẽ để trích xuất văn bản từ hình ảnh.
Ngoài ra, Tesseract OCR có khả năng nhận dạng văn bản với độ chính xác cao, đặc biệt là trong việc nhận dạng văn bản in. Nó có thể hoạt động trên nhiều nền tảng, cho phép sử dụng đa nền tảng.
Điều này giúp việc triển khai trong nhiều môi trường trở nên dễ dàng và mang lại sự linh hoạt trong vận hành. Vì là mã nguồn mở, Tesseract OCR nhận được sự hỗ trợ mạnh mẽ từ cộng đồng, đảm bảo sự cải tiến liên tục. Hơn nữa, công cụ này cung cấp nhiều tính năng xử lý trước và xử lý sau hình ảnh, giúp trích xuất văn bản một cách chính xác hơn.
Nhờ vào những đặc điểm này, Tesseract OCR được sử dụng rộng rãi trong nhiều ngành công nghiệp và ứng dụng khác nhau. Đặc biệt, nó được thiết kế để có thể xử lý văn bản viết tay và tài liệu có bố cục phức tạp, giúp đáp ứng đa dạng các trường hợp sử dụng. Tesseract OCR có lịch sử phát triển từ những năm 1980 và đã trải qua nhiều phiên bản nâng cấp để cung cấp các chức năng tiên tiến hơn. So với các công nghệ OCR khác, nó được đánh giá cao về độ chính xác và tính linh hoạt.
Tích hợp Tesseract OCR với Python: Pytesseract
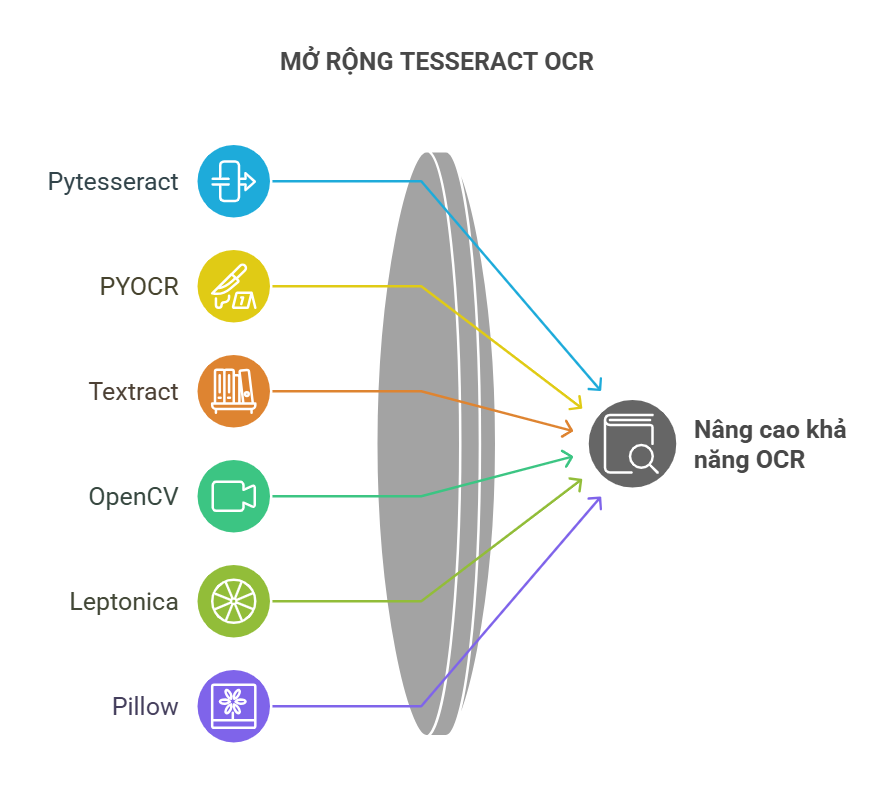
Tesseract OCR có thể được sử dụng dễ dàng trong Python thông qua Pytesseract, một trình bao bọc (wrapper) của Python dành cho Tesseract OCR. Pytesseract đóng vai trò là cầu nối giữa mã Python và Tesseract OCR, đảm bảo khả năng tương thích và tính linh hoạt khi làm việc với nhiều cấu trúc phần mềm khác nhau. Ngoài Pytesseract, còn có các thư viện và trình bao bọc OCR khác có thể tích hợp với Tesseract OCR, chẳng hạn như:
- PYOCR: Cung cấp nhiều tùy chọn để nhận diện văn bản, số và từ ngữ.
- Textract: Hỗ trợ trích xuất dữ liệu từ các tệp có dung lượng lớn và tệp PDF đóng gói.
- OpenCV: Thư viện mã nguồn mở tập trung vào xử lý hình ảnh và thị giác máy tính (Computer Vision) theo thời gian thực.
- Leptonica: Hỗ trợ xử lý hình ảnh và các ứng dụng phân tích hình ảnh bằng thư viện đồ họa.
- Pillow: Thư viện xử lý hình ảnh của Python, hỗ trợ mở, chỉnh sửa và lưu hình ảnh.
Bằng cách tận dụng các thư viện này, Tesseract OCR có thể được mở rộng thêm nhiều chức năng, cho phép xử lý hình ảnh nâng cao và trích xuất dữ liệu chính xác hơn. Đặc biệt, kết hợp Tesseract OCR với OpenCV rất hiệu quả trong việc xử lý ảnh trước và giảm nhiễu, giúp cải thiện độ chính xác của Tesseract OCR. Ngoài ra, Pytesseract giúp tích hợp với hệ sinh thái thư viện phong phú của Python để phát triển nhiều ứng dụng khác nhau.
Quy trình xử lý của Tesseract OCR
Quy trình xử lý của Tesseract OCR bao gồm 6 bước sau:
Yêu cầu API (API Request): Tesseract OCR chỉ có thể truy cập thông qua tích hợp API. Sau khi kết nối giữa giải pháp và Tesseract OCR được thiết lập, một yêu cầu API có thể được gửi đến Tesseract OCR engine.
Hình ảnh đầu vào (Input Image): Hình ảnh cần trích xuất văn bản sẽ được gửi thông qua yêu cầu API.
Xử lý ảnh trước (Image Preprocessing): Trước khi trích xuất dữ liệu, Tesseract OCR sẽ kích hoạt chức năng xử lý ảnh trước. Mục đích của bước này là tối ưu hóa chất lượng hình ảnh nhằm đảm bảo kết quả trích xuất dữ liệu chính xác nhất. Trong nhiều trường hợp, OpenCV và Tesseract OCR được kết hợp để nâng cao chất lượng hình ảnh trước khi trích xuất dữ liệu.
Trích xuất dữ liệu (Data Extraction): Tesseract OCR engine sẽ xử lý hình ảnh đầu vào bằng cách sử dụng bộ dữ liệu đã được huấn luyện trước (pre-trained datasets) cùng với Leptonica hoặc OpenCV để trích xuất dữ liệu.
Chuyển đổi văn bản (Text Conversion): Sau khi trích xuất dữ liệu (văn bản) từ hình ảnh đầu vào, Tesseract OCR có thể chuyển đổi dữ liệu này thành nhiều định dạng khác nhau như PDF, văn bản thuần (plain text), HTML, TSV và XML.
Phản hồi API (API Response): Khi dữ liệu đầu ra đã sẵn sàng, giải pháp sẽ nhận được phản hồi API kèm theo kết quả cuối cùng.
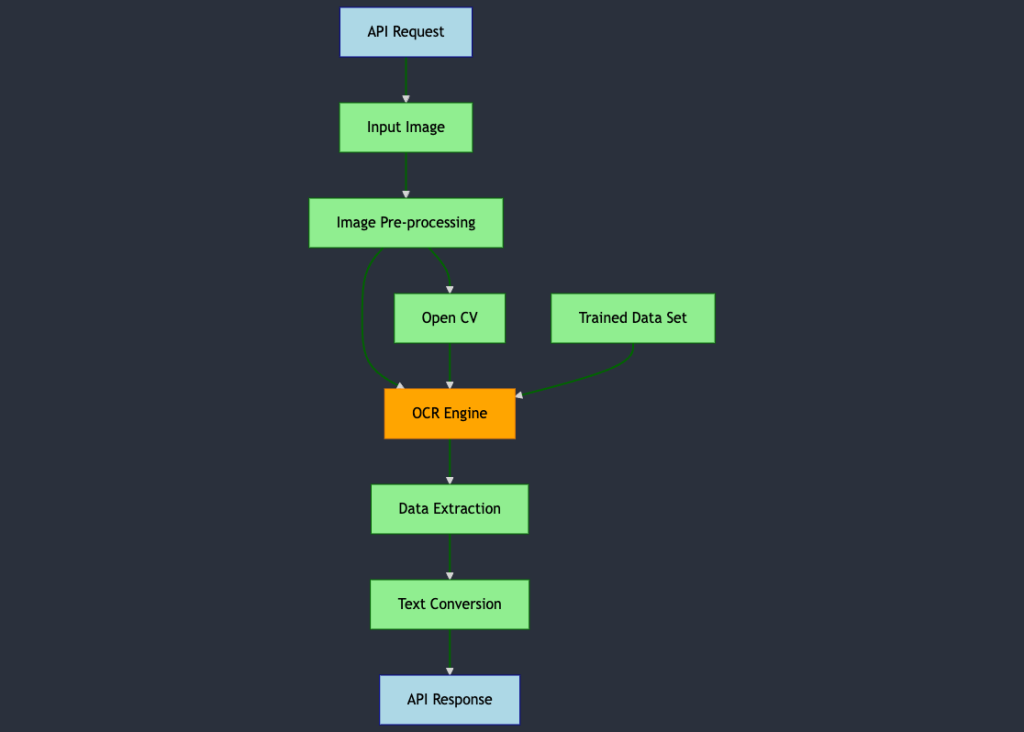
Quy trình xử lý này giúp Tesseract OCR có thể trích xuất văn bản từ hình ảnh một cách hiệu quả. Đặc biệt, trong bước xử lý ảnh trước, các kỹ thuật như loại bỏ nhiễu (noise reduction) và điều chỉnh độ tương phản (contrast adjustment) được áp dụng để nâng cao chất lượng hình ảnh. Điều này giúp cải thiện độ chính xác của Tesseract OCR, cho phép trích xuất văn bản một cách chính xác hơn. Ngoài ra, bằng cách sử dụng Tesseract OCR thông qua API, nó có thể dễ dàng tích hợp với các hệ thống và ứng dụng khác.
Cải thiện xử lý hình ảnh bằng sự kết hợp giữa OpenCV và Tesseract OCR
OpenCV là một thư viện mã nguồn mở về thị giác máy tính (computer vision), giúp tăng cường khả năng trích xuất dữ liệu của các công cụ OCR như Tesseract OCR. Khi sử dụng thư viện OpenCV, có thể tích hợp các chức năng sau vào giải pháp OCR:
- Nhận diện đối tượng (Object Detection): Cho phép giải pháp phát hiện các đối tượng khác nhau.
- Mạng nơ-ron sâu (Deep Neural Networks – DNN): Giúp giải pháp có thể phân loại hình ảnh.
- Xử lý hình ảnh (Image Processing): Hỗ trợ các kỹ thuật như phát hiện cạnh, thao tác điểm ảnh, và chỉnh sửa độ nghiêng, giúp xử lý hình ảnh đầu vào một cách hiệu quả hơn.
Nếu không có OpenCV, Tesseract OCR sẽ không thể trở nên tinh vi như các giải pháp OCR hiện đại ngày nay. Hiện tại, nhiều giải pháp OCR đã áp dụng các công nghệ AI khác nhau. Bằng cách sử dụng OpenCV, khả năng xử lý hình ảnh trước (preprocessing) của Tesseract OCR được nâng cao đáng kể. Điều này đặc biệt hữu ích khi cần trích xuất văn bản từ hình ảnh có nhiều nhiễu hoặc độ phân giải thấp với độ chính xác cao. Nhờ đó, Tesseract OCR có thể áp dụng cho nhiều trường hợp sử dụng hơn.
Cài đặt Tesseract OCR trong Python

Việc cài đặt Pytesseract không phải lúc nào cũng đơn giản, và bạn có thể gặp khó khăn trong quá trình cài đặt. Hãy bắt đầu với các bước cài đặt cơ bản. Trước tiên, bạn cần cài đặt Tesseract OCR, sau đó mới cài đặt gói pytesseract trong Python.
Đối với Windows:
Đối với Linux (Ubuntu/Debian):
Đây là các bước cơ bản ban đầu để cài đặt pytesseract. Tuy nhiên, có một số vấn đề có thể xảy ra trong quá trình cài đặt. Dưới đây là các bước bạn có thể thực hiện để khắc phục chúng.
Để giải quyết các lỗi trong quá trình cài đặt, trước tiên, bạn cần kiểm tra thông báo lỗi và áp dụng các biện pháp thích hợp. Đặc biệt, việc cấu hình biến môi trường và kiểm tra các phụ thuộc (dependencies) là điều quan trọng để đảm bảo quá trình cài đặt diễn ra suôn sẻ.
Lợi ích của Python Tesseract

Các trường hợp ứng dụng của Tesseract OCR
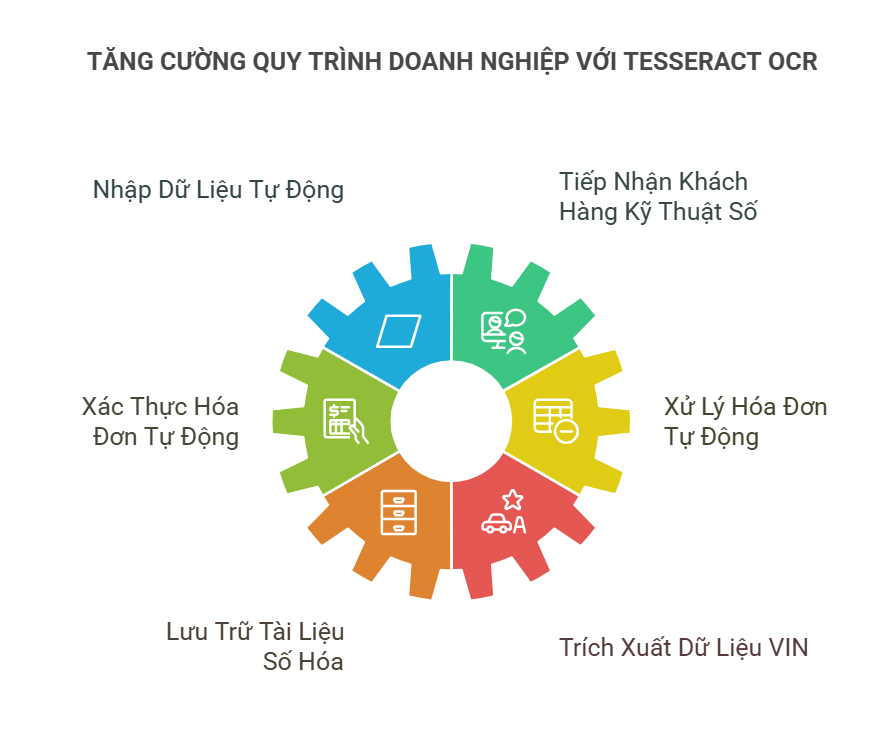
Tesseract OCR có thể được sử dụng để cải thiện quy trình xử lý tài liệu trong các doanh nghiệp xử lý tài liệu từ khách hàng, nhà cung cấp, đối tác hoặc nhân viên. Dưới đây là một số trường hợp sử dụng chính mà Python OCR có thể áp dụng:
- Nhập dữ liệu tự động: Các công việc nhập dữ liệu thủ công thường gây ra tắc nghẽn do tính chất lặp đi lặp lại. Bằng cách sử dụng OCR, doanh nghiệp có thể loại bỏ việc nhập dữ liệu thủ công, giúp giảm chi phí lên đến 70%.
- Tiếp nhận khách hàng kỹ thuật số: OCR giúp trích xuất thông tin cá nhân từ giấy tờ tùy thân, cho phép doanh nghiệp cung cấp giải pháp onboarding từ xa, loại bỏ quy trình tiếp nhận khách hàng tại quầy.
- Tự động xác thực hóa đơn cho chương trình khách hàng thân thiết: Nếu doanh nghiệp thực hiện các chiến dịch khách hàng thân thiết quy mô lớn, yêu cầu xác thực số lượng lớn hóa đơn, OCR có thể giúp trích xuất dữ liệu vào cơ sở dữ liệu trước khi xác thực. Đây là một trong những ứng dụng hữu ích của Tesseract OCR.
- Xử lý hóa đơn tự động cho tài khoản phải trả: Quy trình tài khoản phải trả thường bao gồm nhiều bước, thường bắt đầu bằng nhập dữ liệu thủ công. OCR giúp giảm thời gian xử lý và chi phí thông qua việc tự động trích xuất dữ liệu hóa đơn.
- Lưu trữ tài liệu số hóa: Việc tìm kiếm thông tin trong tài liệu giấy có thể tốn rất nhiều thời gian. Lưu trữ kỹ thuật số bằng OCR mang lại nhiều lợi ích như giảm chi phí, tuân thủ GDPR, và cải thiện khả năng truy cập dữ liệu.
- Trích xuất dữ liệu VIN: Việc ghi số nhận dạng phương tiện (VIN) trên giấy hoặc biểu mẫu bằng tay không phải lúc nào cũng là phương pháp hiệu quả. Trích xuất VIN bằng Tesseract OCR giúp tối ưu hóa quy trình và nâng cao hiệu suất hoạt động.
Ngay cả khi trường hợp sử dụng cụ thể của bạn không được liệt kê ở đây, đừng lo lắng. Giống như các giải pháp Python OCR khác, Tesseract OCR có thể cải thiện nhiều quy trình làm việc liên quan đến tài liệu.
Tuy nhiên, cần lưu ý rằng Tesseract OCR không phải là một giải pháp có sẵn để sử dụng ngay. Đối với từng trường hợp sử dụng được đề cập ở trên, bạn cần kết hợp nhiều API và sử dụng các trình bao bọc (wrapper) Python cùng với các thư viện chức năng lập trình.
Hơn nữa, để hỗ trợ các trường hợp sử dụng cụ thể, công cụ OCR cần được huấn luyện với một lượng dữ liệu lớn. Điều này đòi hỏi nhiều tài nguyên về thời gian và chi phí. Mặc dù Tesseract OCR có thể giúp doanh nghiệp tăng hiệu suất làm việc và giảm chi phí, nhưng việc triển khai đòi hỏi sự chuẩn bị và kế hoạch cẩn thận.
Bằng cách tận dụng Tesseract OCR, các quy trình thủ công có thể được tự động hóa, giúp tăng đáng kể hiệu quả làm việc. Nhờ đó, doanh nghiệp có thể tập trung nguồn lực vào những nhiệm vụ quan trọng hơn, dẫn đến nâng cao năng suất tổng thể.
Huấn luyện Tesseract OCR

Hạn chế của Tesseract OCR
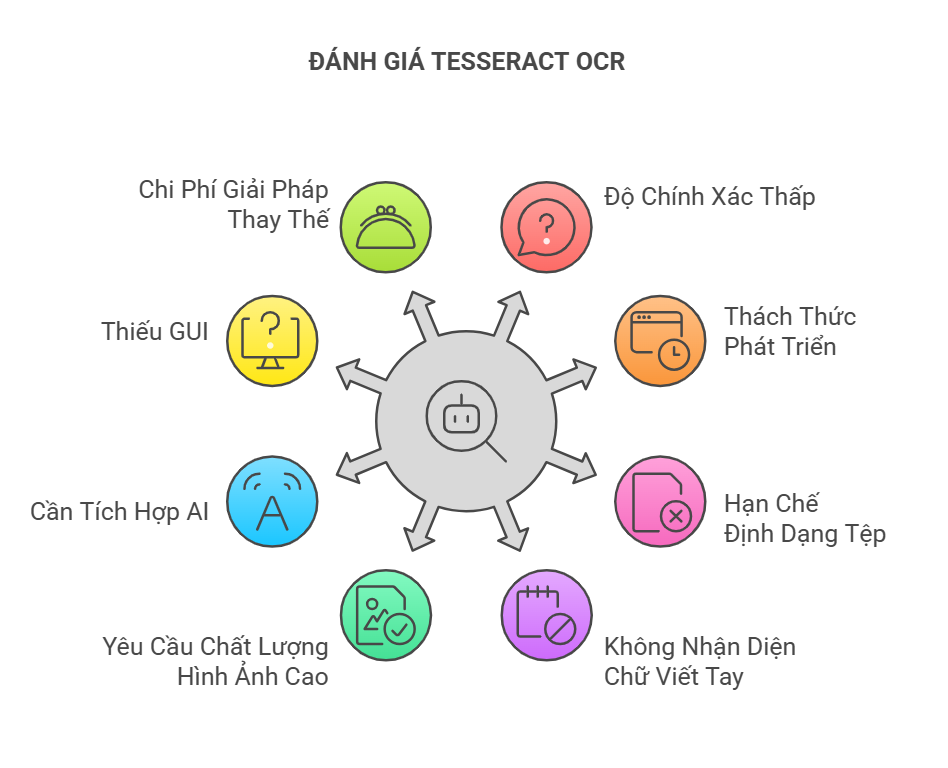
Tesseract OCR rất hữu ích trong nhiều trường hợp và tình huống sử dụng. Tuy nhiên, giống như các giải pháp mã nguồn mở khác, nó có một số hạn chế cần được cân nhắc. Dưới đây là từng hạn chế cụ thể:
- Tesseract OCR không chính xác bằng các giải pháp tiên tiến hơn có tích hợp AI.
- Nếu độ tách biệt giữa tiền cảnh và hậu cảnh trong hình ảnh thấp, Tesseract OCR dễ gặp lỗi.
- Phát triển giải pháp tùy chỉnh bằng Tesseract OCR yêu cầu nhiều tài nguyên và thời gian.
- Tesseract OCR không tự hỗ trợ tất cả các định dạng tệp.
- Tesseract OCR không nhận diện chữ viết tay.
- Chất lượng hình ảnh phải đạt một ngưỡng DPI (dots per inch) nhất định để hoạt động hiệu quả.
- Tesseract OCR cần được phát triển thêm, bao gồm tích hợp AI để tự động hóa quy trình xử lý tài liệu (ví dụ: xác minh và kiểm tra chéo).
- Tesseract OCR không có giao diện đồ họa (GUI), do đó cần kết nối với một GUI hiện có hoặc phát triển GUI tùy chỉnh.
- Việc phát triển bổ sung yêu cầu cả thời gian và chi phí.
Nhìn chung, Tesseract OCR có thể là một giải pháp phù hợp nếu trường hợp sử dụng OCR đơn giản và doanh nghiệp có chuyên môn nội bộ về phát triển OCR trong Python. Tuy nhiên, nếu cần mở rộng quy mô, độ chính xác cao, hoặc một giải pháp có sẵn để sử dụng ngay, thì Tesseract OCR có thể không phải là lựa chọn tối ưu.
Mặc dù Tesseract OCR miễn phí, nhưng một số giải pháp trả phí có thể đơn giản hơn và tiết kiệm chi phí hơn so với triển khai Tesseract OCR. Một số lý do khác khiến Tesseract OCR có thể không phải là lựa chọn phù hợp bao gồm:
- Thời gian thiết lập lâu
- Cần thiết lập kết nối với hệ thống ERP hoặc kế toán
- Không hỗ trợ trường hợp sử dụng cụ thể
- Không có sẵn dữ liệu huấn luyện
- Thiếu chuyên môn nội bộ về OCR trong Python
Với những hạn chế này, cần đánh giá cẩn thận và lên kế hoạch kỹ lưỡng trước khi triển khai Tesseract OCR. Đặc biệt, nếu cần tùy chỉnh hoặc phát triển thêm để phù hợp với nhu cầu cụ thể, thì cũng nên cân nhắc các giải pháp OCR khác.
Các giải pháp thay thế cho Tesseract OCR: Klippa DocHorizon

LLMWhisperer: Công nghệ OCR mới nhất
LLMWhisperer là một công nghệ trình bày dữ liệu từ tài liệu phức tạp theo cách dễ hiểu nhất cho các mô hình ngôn ngữ lớn (LLM – Large Language Models). Trong khi các công cụ OCR truyền thống như Tesseract OCR chủ yếu dựa vào nhận diện mẫu (pattern recognition) và bộ dữ liệu được định nghĩa trước, LLMWhisperer kết hợp công nghệ học sâu (deep learning) và xử lý ngôn ngữ tự nhiên (NLP) để hiểu và diễn giải văn bản theo cách có ý thức về ngữ cảnh hơn.
LLMWhisperer được thiết kế để xử lý nhiều loại tài liệu khác nhau, bao gồm bố cục phức tạp, ghi chú viết tay và nội dung đa ngôn ngữ.
So sánh giữa LLMWhisperer và Tesseract OCR
Trong khi Tesseract OCR là công cụ phù hợp cho các tác vụ OCR cơ bản, nó phụ thuộc nhiều vào công nghệ xử lý hình ảnh truyền thống và mô hình được huấn luyện sẵn, điều này có thể khiến nó không hoạt động hiệu quả đối với tài liệu không chuẩn hoặc phức tạp. Ngược lại, LLMWhisperer sử dụng mô hình học sâu (deep learning) có khả năng thích nghi với nhiều kiểu chữ, ngôn ngữ và cấu trúc tài liệu khác nhau.
Hiểu ngữ cảnh:
Vì LLMWhisperer sử dụng mô hình LLM, nó có thể hiểu ngữ cảnh của văn bản được nhận diện, giúp giải thích các ký tự mơ hồ hoặc không rõ ràng một cách hiệu quả, đặc biệt là với tài liệu viết tay hoặc nội dung đa ngôn ngữ.Khả năng xử lý nhiều loại tài liệu:
LLMWhisperer vượt trội trong việc xử lý bố cục tài liệu phức tạp, chẳng hạn như bảng biểu, biểu mẫu và văn bản có nhiều cột, trong khi Tesseract OCR có thể gặp khó khăn nếu không có quá trình tiền xử lý hoặc hậu xử lý chuyên sâu.
LLMWhisperer có độ chính xác cao khi xử lý tài liệu phức tạp, vốn thường là thách thức đối với các công nghệ OCR truyền thống. Nhờ đó, LLMWhisperer có thể hỗ trợ nhiều trường hợp sử dụng hơn.
I like this site because so much utile material on here : D.
application melbet telecharger melbet apk
partenaires 1win 1win telecharger
Жалюзи от производителя https://balkon-pavilion.ru изготовление, продажа и профессиональная установка. Большой выбор дизайнов, точные размеры, надёжная фурнитура и комфортный сервис для квартир и офисов.
Производим пластиковые https://zavod-dimax.ru окна и выполняем профессиональную установку. Качественные материалы, точные размеры, быстрый монтаж и гарантийное обслуживание для комфорта и уюта в помещении.
Изделия из пластмасс https://ftk-plastik.ru собственного производства. Продажа оптом и в розницу, широкий ассортимент, надёжные материалы и стабильные сроки. Выполняем заказы любой сложности по техническому заданию клиента.
Производство оборудования https://repaircom.ru с предварительной разработкой и адаптацией под требования клиента. Качественные материалы, точные расчёты, соблюдение сроков и техническая поддержка.
Торговая мебель https://woodmarket-for-business.ru от производителя для бизнеса. Витрины, стеллажи, островные конструкции и кассовые модули. Индивидуальный подход, надёжные материалы и практичные решения для продаж.
Szukasz kasyna? kasyno internetowe w Polsce: wybor najlepszych stron do gry. Licencjonowane platformy, popularne sloty i kasyna na zywo, wygodne metody platnosci, uczciwe warunki i aktualne oferty.
Grasz w kasynie? internetowe kasyno w Polsce to najlepsze miejsca do gry w latach 2025–2026. Zaufane strony, sloty i gry na zywo, przejrzyste warunki, wygodne wplaty i wyplaty.
Ищешь блины для штанки? https://blin-na-shtangy.ru для эффективных силовых тренировок. Чугунные и резиновые диски, разные веса, долговечность и удобство использования. Решение для новичков и опытных спортсменов.
Производим торговую мебель https://woodmarket-for-business.ru для розничного бизнеса и сетевых магазинов. Функциональные конструкции, современный дизайн, точные размеры и полный цикл работ — от проекта до готового решения.
Оборудование для отопления https://thermostock.ru и водоснабжения: котлы, циркуляционные насосы, радиаторы, мембранные баки и комплектующие от ведущих производителей. Что вы получаете: сертифицированные товары, прозрачные цены, оперативную обработку заказа. Создайте комфортный микроклимат в доме — выбирайте профессионалов!
Нужен памятник? памятник уфа — гранитные и мраморные изделия. Индивидуальные проекты, точная обработка камня, оформление и монтаж. Надёжное качество и внимательное отношение к деталям.
Нужен памятник? заказать памятник в уфе — гранитные и мраморные изделия. Индивидуальные проекты, точная обработка камня, оформление и монтаж. Надёжное качество и внимательное отношение к деталям.
Нужно авто? авто под заказ из японии поиск, проверка, оформление и доставка авто из разных стран. Прозрачные условия, помощь на всех этапах и сопровождение сделки до получения автомобиля.
дизайн студия екатерины ремонт квартир под ключ
Нужен памятник? памятник уфа — гранитные и мраморные изделия. Индивидуальные проекты, точная обработка камня, оформление и монтаж. Надёжное качество и внимательное отношение к деталям.
Нужен проектор? https://projector24.ru большой выбор моделей для дома, офиса и бизнеса. Проекторы для кино, презентаций и обучения, официальная гарантия, консультации специалистов, гарантия качества и удобные условия покупки.
Do you need repairs? Philadelphia home repair professional help for apartments and private homes. Plumbing, electrical, minor and medium-sized repairs, finishing work, and equipment installation. High-quality, accurate, and on-time services.
Проблемы с авто? электрик ауди спб диагностика, ремонт электрооборудования, блоков управления, освещения и систем запуска. Опыт, современное оборудование и точное определение неисправностей.
Celebrity World Care https://celebrityworldcare.com интернет-магазин профессиональной медицинской и натуральной косметики для ухода за кожей при ихтиозе, дерматитах, псориазе и других дерматологических состояниях. Сертифицированные средства с мочевиной, без отдушек и парабенов. Доставка по России.
квартира в сочи жк светский лес сочи
химчистка обуви отзывы химчистка обуви
Модульные дома https://modulndom.ru под ключ: быстрый монтаж, продуманные планировки и высокое качество сборки. Подходят для круглогодичного проживания, отличаются энергоэффективностью, надежностью и возможностью расширения.
Нужна медсправка замены водительского удостоверения https://med-spravki-msk.ru
Специализированный коррекционно-речевой https://neyroangel.ru детский сад для детей с особенностями развития в Москве. Беремся за самые тяжелые случаи, от которых отказываются другие. Нейропсихолог, логопед, запуск речи. Государственная лицензия: Л035-01298-77/01604531 от 09.12.24
Рэмси Диагностика: https://remsi-med.ru Сеть высокотехнологичных диагностических центров (МРТ, КТ). Точные исследования на оборудовании экспертного класса и качественная расшифровка снимков.
Детский Доктор: https://kidsmedic.ru Специализированный медицинский центр для детей. Квалифицированная помощь педиатров и узких специалистов для здоровья вашего ребенка с первых дней жизни.
Полесская ЦРБ: https://polesskcrb.ru Официальный портал центральной районной больницы Калининградской области. Информация об услугах, расписание врачей и важные новости здравоохранения для жителей региона.
недорогой проектор интернет-магазин проекторов в Москве
АрсМед: https://arsmedclinic.ru Многопрофильная клиника, предлагающая широкий выбор медицинских услуг от диагностики до лечения. Современный подход и комфортные условия для пациентов всех возрастов.
Играешь в казино? up x официальный сайт простой вход, удобная регистрация и доступ ко всем возможностям платформы. Стабильная работа, адаптация под разные устройства и комфортный пользовательский опыт.
Любишь азарт? up x официальный сайт играть онлайн в популярные игры и режимы. Быстрый вход, удобная регистрация, стабильная работа платформы, понятный интерфейс и комфортные условия для игры в любое время на компьютере и мобильных устройствах.
Любишь азарт? t.me играть онлайн легко и удобно. Быстрый доступ к аккаунту, понятная навигация, корректная работа на любых устройствах и комфортный формат для пользователей.
химчистка обуви работа химчистка обуви цена
Play online puzzles https://www.forum-hausbau.de/index.php?topic=34955.0 anytime and train your logic and attention skills. Classic and themed puzzles, various sizes, simple gameplay, and comfortable play on computers and mobile devices.
купить люстру деревянная люстра
мужской костюм 2026 костюм мужской классический недорого
Электромонтажные работы https://electric-top.ru в Москве и области. Круглосуточный выезд электриков. Гарантия на работу. Аварийный электрик.
коррозия у авто? антикоррозийная обработка спб эффективная защита от влаги, соли и реагентов. Комплексная обработка кузова и днища, качественные составы и надёжный результат для новых и подержанных авто.
Коррозия на авто? антикоррозийная обработка днища автомобиля мы используем передовые шведские материалы Mercasol и Noxudol для качественной защиты днища и скрытых полостей кузова. На все работы предоставляется гарантия сроком 8 лет, а цены остаются доступными благодаря прямым поставкам материалов от производителя.
Планируете мероприятие? ai мастер-класс уникальные интерактивные форматы с нейросетями для бизнеса. Мы разрабатываем корпоративные мероприятия под ключ — будь то тимбилдинги, обучающие мастер?классы или иные активности с ИИ, — с учётом ваших целей. Работаем в Москве, Санкт?Петербурге и регионах. AI?Event специализируется на организации корпоративных мероприятий с применением технологий искусственного интеллекта.
Украшения для пирсинга https://piercing-opt.ru купить оптом украшения для пирсинга. Напрямую от производителя, выгодные цены, доставка. Отличное качество.
Ищешь сокращатель сылок? https://l1l.kz надежный сокращатель ссылок в Казахстане, рекомендуем заглянуть на сайт, где весь функционал доступен бесплатно и без регистрации
Противопожарные двери https://bastion52.ru купить для защиты помещений от огня и дыма. Большой выбор моделей, классы огнестойкости EI30, EI60, EI90, качественная фурнитура и соответствие действующим стандартам.
Нужны цветы? хризантем воронеж закажите цветы с доставкой на дом или в офис. Большой выбор букетов, свежие цветы, стильное оформление и точная доставка. Подойдёт для праздников, сюрпризов и важных событий.
O’zbekiston uchun https://uzresearch.uz iqtisodiyot, moliya, ijtimoiy jarayonlar, bozorlar va mintaqaviy rivojlanish kabi asosiy sohalarda tadqiqotlar olib boradigan analitik platforma. Strukturaviy ma’lumotlar va professional tahlil.
Savdo va biznes https://infinitytrade.uz uchun xalqaro platforma. Bozor tahlili, xalqaro savdo, eksport va import, logistika, moliya va biznes yangiliklari. Tadbirkorlar va kompaniyalar uchun foydali materiallar, sharhlar va ma’lumotlar.
Ijtimoiy rivojlanish https://ijtimoiy.uz va jamoat hayoti uchun portal. Yangiliklar, tahlillar, tashabbuslar, loyihalar va ekspert fikrlari. Ijtimoiy jarayonlar, fuqarolik ishtiroki, ta’lim va jamiyatni rivojlantirish bo’yicha materiallar.
Foydali maslahatlar https://grillades.uz va g’oyalar bilan panjara va barbekyu haqida loyiha. Retseptlar, panjara qilish texnikasi va jihozlar va aksessuarlarni tanlash. Mukammal ta’m va muvaffaqiyatli ochiq havoda uchrashuvlar uchun hamma narsa.
Qurilish materiallari https://emtb.uz turar-joy va sanoat qurilishi uchun beton va temir-beton. Poydevorlar, pollar va inshootlar uchun ishonchli yechimlar, standartlarga muvofiqlik, izchil sifat va loyihaga xos yetkazib berish.
Ijtimoiy jarayonlar https://qqatx.uz va jamiyat taraqqiyoti bo’yicha onlayn axborot platformasi. Tegishli materiallar, tahliliy sharhlar, tadqiqotlar va murakkab mavzularning tushuntirishlari aniq va tuzilgan formatda.
Любишь азарт? комета казино официальное зеркало современные слоты, live-форматы, понятные правила и удобный доступ с ПК и смартфонов. Играйте онлайн в удобное время.
Лучшее казино up x казино играйте в слоты и live-казино без лишних сложностей. Простой вход, удобный интерфейс, стабильная платформа и широкий выбор игр для отдыха и развлечения.
Играешь в казино? ап икс казино Слоты, рулетка, покер и live-дилеры, простой интерфейс, стабильная работа сайта и возможность играть онлайн без сложных настроек.
Лучшее казино ап икс играйте в слоты и live-казино без лишних сложностей. Простой вход, удобный интерфейс, стабильная платформа и широкий выбор игр для отдыха и развлечения.
Играешь в казино? ап икс скачать Слоты, рулетка, покер и live-дилеры, простой интерфейс, стабильная работа сайта и возможность играть онлайн без сложных настроек.
Descubre aqui Resena Fortune of Aztec las emocionantes ofertas de juegos en linea que transforman la experiencia del usuario y brindan entretenimiento sin igual. Los casinos virtuales estan revolucionando la forma en que jugamos, ofreciendo una variedad de tragamonedas y juegos de mesa que se pueden disfrutar desde la comodidad del hogar.
Русские подарки и сувениры купить в широком ассортименте. Классические и современные изделия, национальные символы, качественные материалы и оригинальные идеи для памятных и душевных подарков.
Нужно казино? ап икс современные игры, простой вход, понятный интерфейс и стабильная работа платформы. Играйте с компьютера и мобильных устройств в любое время без лишних сложностей.
магазин ремней ремни.рф оригинальные модели из натуральной кожи для мужчин и женщин. Классические и современные дизайны, высокое качество материалов, аккуратная фурнитура и удобный выбор для любого стиля.
Самые качественные разноцветные блины для штанги широкий выбор весов и форматов. Надёжные материалы, удобная посадка на гриф, долговечное покрытие. Подходят для фитнеса, пауэрлифтинга и регулярных тренировок.
Нужна топливная карта? топливные карты для юридических лиц удобный контроль расходов на ГСМ, безналичная оплата топлива, отчетность для бухгалтерии и снижение затрат автопарка. Подключение по договору, выгодные условия для бизнеса.
Хочешь контролировать ГСМ https://bts-oil.ru экономия на топливе, контроль заправок, детальная аналитика и закрывающие документы. Решение для компаний с собственным или арендованным автопарком.
Топливный контроль https://avtomateriali.ru эффективное решение для бизнеса с транспортом. Безналичная заправка, учет топлива, детальные отчеты и удобное управление расходами по каждому автомобилю.
Контроль топлива топливные карты для юридических лиц удобный способ учета и оплаты топлива без наличных. Контроль заправок, лимиты по авто и водителям, отчетность для бухгалтерии и снижение затрат на содержание автопарка.
Топливные карты для юр лиц https://mazdacenter.ru контроль топлива, прозрачная отчетность, удобство для бухгалтерии и безопасность расчетов. Экономия времени и средств при управлении корпоративным транспортом.
Онлайн-казино Mostbet — слоты, настольные игры и live-дилеры в одном аккаунте. Удобные депозиты, оперативный вывод средств, бонусные предложения и игра с любого устройства.
Details on the page: https://www.myvipon.com/post/1655607/bonus-promos-comment-maximiser-vos-gains-amazon-coupons
Today’s highlights are here: you can look here
A sports portal sbs-sport.com.az with breaking news, statistics, and expert commentary. Match schedules, transfers, interviews, and competition results are available in real time.
Live match https://sporx.com.az results, the latest sports news, transfers, and today’s TV schedule. Live updates, key events, and all sports information in one portal.
Учишься в МТИ? мти помощь в сдаче: консультации, разъяснение сложных тем, подготовка к тестированию и экзаменам. Удобный формат, быстрые ответы и поддержка на всех этапах обучения.
Zinedine Zidane https://zidan.com.az biography, football career, achievements, and coaching successes. Details on his matches, titles, the French national team, and his time at the top clubs in world football.
Нужна курсовая? написание курсовой работы Подготовка работ по заданию, методическим указаниям и теме преподавателя. Сроки, правки и сопровождение до сдачи включены.
Авиабилеты по низким ценам https://tutvot.com посуточная аренда квартир, вакансии без опыта работы и займы онлайн. Актуальные предложения, простой поиск и удобный выбор решений для путешествий, работы и финансов.