

Hello, I’m Kakeya, the representative of Scuti.
Our company specializes in Vietnam-based offshore development, lab-type development, and generative AI consulting services, with a focus on generative AI technologies. Recently, we have been fortunate to receive numerous requests for system development integrated with generative AI.
The evolution of generative AI technology shows no signs of slowing down! It’s advancing so fast that it’s hard to keep up!
On July 23, 2024 (US time), Meta announced its latest LLM, Llama 3.1, which has garnered significant attention. Although it is a minor version upgrade from Llama 3 to Llama 3.1, the significantly enhanced Llama 3.1 is creating new waves in the world of generative AI with its astounding performance and the decision to release it as open source.
In this article, we will explore the fascinating features of Llama 3.1 and delve into its potential.
Basic Knowledge of Llama 3.1

What is Llama 3.1?
Llama 3.1 is an AI capable of performing various tasks such as generating natural human-like text, translation, answering questions, and creating conversations. By learning from vast amounts of data, it achieves a level of accuracy and naturalness that was impossible for conventional AI models.
The length of context it can process has been dramatically expanded to support an astonishing 128,000 tokens. This is 16 times the length of the previous version’s 8,000 tokens, enabling it to comprehend and generate more complex and lengthy texts.
Moreover, multilingual support has been enhanced, with Llama 3.1 now supporting a total of eight languages, including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. Although Japanese is not included in the list, based on my observations, it handles Japanese text seamlessly without any noticeable issues, providing a high level of accuracy.
Additionally, Llama 3.1 is released under an open-source license, marking a major turning point in the history of AI development. This allows anyone to freely use, modify, and redistribute the model, enabling developers worldwide to contribute to the research and development of Llama 3.1. This move is expected to accelerate the evolution of AI technology.
Llama 3.1 Model Family
Llama 3.1 is available in three model sizes: 8B, 70B, and 405B, allowing users to select the most suitable model for their specific use cases.
- 8B Model: Known for its lightweight and fast processing, it is ideal for environments with limited computing resources, such as mobile devices and embedded systems.
- 70B Model: Offers a balanced performance and efficiency, making it suitable for a wide range of general natural language processing tasks.
- 405B Model: The largest and most powerful model, optimized for tasks requiring advanced language understanding and reasoning.
Each model size comes in two variants: the Base Model, which is a general-purpose language model, and the Instruct Model, fine-tuned to respond more accurately to human instructions.
List of Available Models:
- Meta-Llama-3.1-8B
- Meta-Llama-3.1-8B-Instruct
- Meta-Llama-3.1-70B
- Meta-Llama-3.1-70B-Instruct
- Meta-Llama-3.1-405B
- Meta-Llama-3.1-405B-Instruct
Llama 3.1 Performance Evaluation
Benchmark Results – Outstanding Scores Surpassing Previous Models
Source:https://ai.meta.com/blog/meta-llama-3-1/
Source:https://ai.meta.com/blog/meta-llama-3-1/
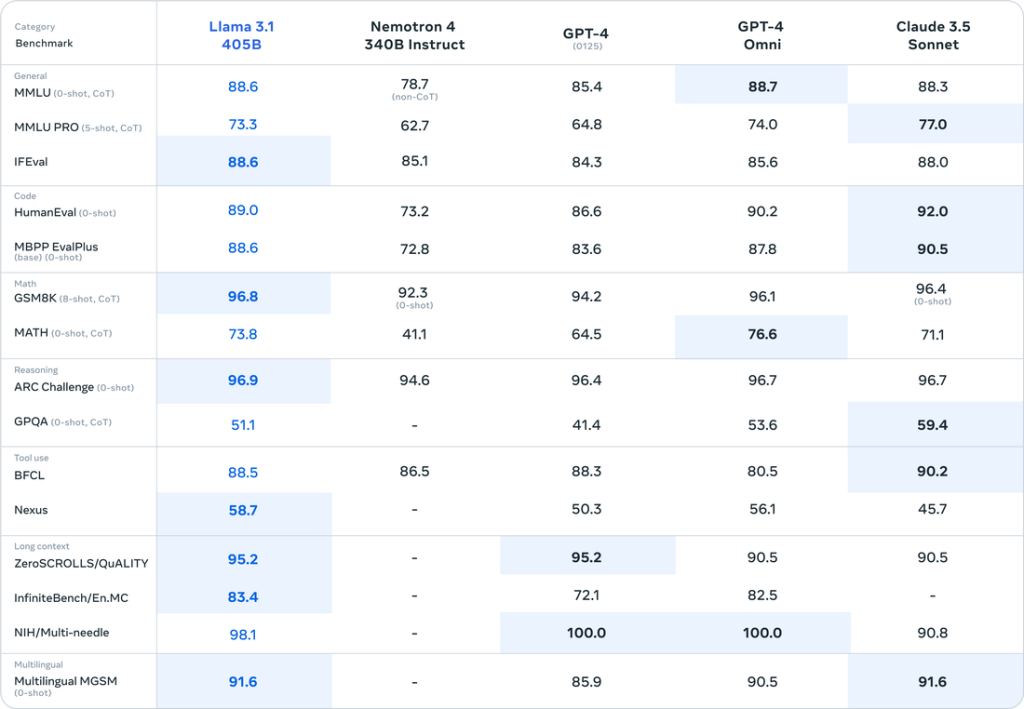
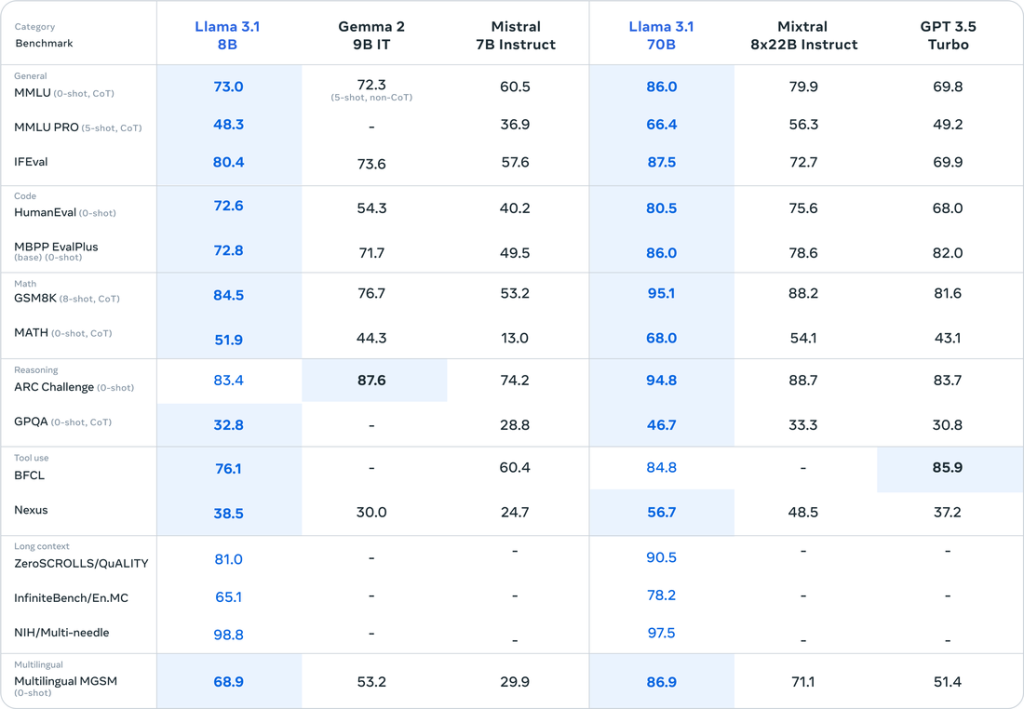
Llama 3.1’s performance has been evaluated across various benchmarks, and the results are remarkable. Notably, the 405B model demonstrates overall performance superior to GPT-4o and nearly on par with Claude 3.5 Sonnet.
MMLU (Massive Multitask Language Understanding):
On this benchmark, which consists of 57 diverse tasks assessing language understanding, the Llama 3.1 405B model achieved an impressive score of 87.3%. This score approaches the human-level benchmark of 90% and is comparable to GPT-4o, demonstrating the advanced language comprehension capabilities of Llama 3.1.
HumanEval:
This benchmark evaluates the ability to generate Python code based on given instructions. The Llama 3.1 405B model scored a high 89.0%, showcasing its ability to understand complex instructions and accurately generate code. This performance is on par with GPT-4o and slightly behind Claude 3.5 Sonnet, recently released by Anthropic.
GSM-8K:
This benchmark measures the ability to solve elementary-level mathematical word problems. The Llama 3.1 405B model achieved an astounding score of 96.8%, indicating its advanced logical reasoning and mathematical problem-solving capabilities.
These benchmark results demonstrate that Llama 3.1 is an exceptionally high-performing AI model across a wide range of domains.
Llama 3.1 Licensing and Commercial Use
Llama 3.1 is offered under a special commercial license called the “Llama 3.1 Community License,” which is more permissive for commercial use compared to previous versions. For detailed terms, please refer to the original license document.
Permitted Uses:
- Redistribution of the model
- Fine-tuning the model
- Creating derivative works
- Using the model’s output to improve other LLMs (including generating and extracting synthetic data for different models)
Conditions:
- If Llama 3.1 is used in products or services with over 700 million monthly active users, an individual license must be obtained from Meta.
- The name of derivative models must include “Llama” at the beginning.
- Derivative works or services must include a clear statement: “Built with Llama.”
These terms make Llama 3.1 a highly accessible and versatile multi-modal language model comparable to GPT-4o. However, you might wonder, “It’s amazing, but how can we actually use it?”
The most effective use of Llama 3.1 is to build RAG (Retrieval-Augmented Generation) systems in on-premise environments. For organizations restricted by security policies from using cloud-based RAG services, Llama 3.1 can be deployed on in-house servers to implement secure and efficient RAG solutions.
Our company provides a SaaS-based RAG (Retrieval-Augmented Generation) service called “SecureGAI,” and we also have expertise and experience in building this service in on-premise environments. If you are interested in implementing RAG in an on-premise environment, please do not hesitate to contact us!
The Technology Behind Llama 3.1
Transformer Architecture – An Innovative Structure Enabling Advanced Language Processing
Llama 3.1 is built on the Transformer deep learning architecture. Introduced by Google researchers in 2017, the Transformer architecture revolutionized the field of natural language processing.
Traditional natural language processing models struggled with handling long texts and required significant time for training. However, the Transformer architecture overcomes these challenges by utilizing a mechanism called Attention.
The Attention mechanism calculates the relationship between each word in a sentence and other words, enabling the Transformer to understand the context of long texts accurately and achieve highly precise language processing.
Llama 3.1 builds upon this Transformer architecture with proprietary enhancements to achieve superior performance and efficiency compared to previous models.
Autoregressive Language Model – Predicting the Future from the Past
Llama 3.1 is an autoregressive language model, which predicts future data based on past data.
In the context of natural language processing, this means predicting the next word in a sequence of words. For example, given the phrase “It’s a beautiful day,” an autoregressive language model would predict the word “today.”
Through learning from a massive amount of text data, Llama 3.1 has pushed this predictive capability to its limits, enabling it to generate human-like natural text.
Large-Scale Data Training – Knowledge Distilled from 15 Trillion Tokens
Llama 3.1 achieves its astounding performance through training on an immense volume of data. Specifically, it has been trained on over 15 trillion tokens from sources such as websites, books, and code.
The use of such large-scale data is a crucial factor in the advancement of AI technology in recent years. Unlike traditional machine learning, where features were manually designed by humans, deep learning allows computers to learn features directly from vast amounts of data.
By harnessing the full power of deep learning, Llama 3.1 has achieved a level of language understanding that was previously unimaginable with traditional language models.
Specifically, pretraining involved approximately 15 trillion tokens of data from publicly available sources, open instruction datasets, and over 25 million synthetic examples created through SFT (Supervised Fine-Tuning) and RLHF (Reinforcement Learning from Human Feedback).
Memory Requirements for Llama 3.1

Source: https://huggingface.co/blog/llama31
The memory requirements to run Llama 3.1 vary depending on the model size and the precision used. Larger models with higher precision require more memory.
For example, when running the 405B model with FP16 precision, the model weights alone require approximately 800GB of memory. Additionally, the KV cache needed to store the model’s context may demand several hundred GB of memory, depending on the context length. As a result, a GPU server with extensive me
Memory Optimization with Quantization – Achieving High Performance with Less Memory
To reduce memory usage, Llama 3.1 also offers quantized models. Quantization is a technique that represents model weights using data types with fewer bits, without significantly sacrificing precision. This reduces memory usage and improves inference speed.
Llama 3.1 provides quantized models with FP16 (16-bit floating point) precision as well as FP8 (8-bit floating point) and INT4 (4-bit integer) precision. FP8 quantized models can reduce memory usage by about half compared to FP16 models. INT4 quantized models can further reduce memory usage to about one-fourth of FP16 models.
Llama 3.1 as a System: Tools for Building Secure AI Systems
Llama 3.1 is not designed to operate independently; to function safely and effectively, additional security measures are necessary. Meta provides several tools and guidelines recommended for use in conjunction with Llama 3.1.
Llama Guard 3 – Detecting Unsafe Content
Llama Guard 3 is a safety tool that analyzes input prompts and generated responses to detect unsafe or inappropriate content. It supports multiple languages, enabling analysis of text written in various languages. Integrating Llama Guard 3 with Llama 3.1 helps mitigate the risk of model misuse and contributes to building more secure AI systems.
Prompt Guard – Preventing Prompt Injection Attacks
Prompt Guard is a tool designed to detect prompt injection attacks, where malicious users manipulate input prompts to alter the behavior of AI models. By identifying such attacks, Prompt Guard ensures the security of AI models.
Code Shield – Detecting Vulnerabilities in Generated Code
Code Shield is a tool that verifies the safety of code generated by AI models. Since AI-generated code may contain security vulnerabilities, Code Shield assists in developing secure AI applications by detecting such vulnerabilities.
Using Llama 3.1
Access via Cloud Services
Source: https://ai.meta.com/blog/meta-llama-3-1/
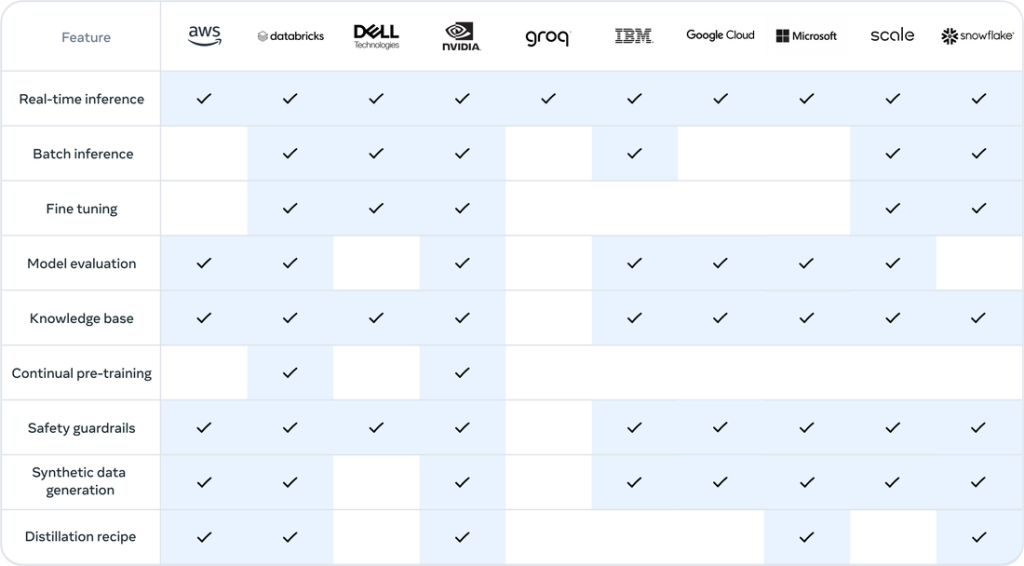
Llama 3.1 can be accessed through major cloud service providers, allowing developers to utilize its powerful capabilities without the need to build their own infrastructure.
- Amazon Web Services (AWS): Llama 3.1 can be easily deployed and utilized through Amazon SageMaker JumpStart.
- Microsoft Azure: Run Llama 3.1 in the cloud and build scalable AI applications through Azure Machine Learning.
- Google Cloud Platform (GCP): Easily deploy Llama 3.1 and develop custom AI solutions through Vertex AI.
These cloud service providers offer the computational resources, storage, and security required to use Llama 3.1, enabling developers to focus solely on AI development.
Hugging Face Transformers
Hugging Face Transformers is an open-source library for working with natural language processing models. Llama 3.1 is also supported by Hugging Face Transformers, making it easy to load and use the model. Transformers is compatible with major deep learning frameworks such as PyTorch, TensorFlow, and JAX, making it accessible in various development environments.
Try Llama 3.1 405B for Free on HuggingChat
You can try Llama 3.1 405B for free on HuggingChat. While it doesn’t support image generation and is limited to text generation, being able to experience the 405B model for free is still highly valuable!
Fast Chat with Llama 3.1 70B on Groq
Groq has also quickly adapted to Llama 3.1! Although it currently supports only the 8B and 70B models (not yet 405B), you can enjoy Llama 3.1’s capabilities in Groq’s ultra-fast response environment!