

Xin chào, tôi là Kakeya, đại diện của Scuti.
Công ty chúng tôi cung cấp các dịch vụ như phát triển offshore và phát triển theo mô hình phòng thí nghiệm tại Việt Nam, chuyên về AI tạo sinh, cũng như tư vấn liên quan đến AI tạo sinh. Gần đây, chúng tôi đã nhận được nhiều yêu cầu về phát triển hệ thống tích hợp với AI tạo sinh.
Anthropic đã công bố một phương pháp mới gọi là “Contextual Retrieval,” nhằm nâng cao độ chính xác của việc truy xuất thông tin trong Retrieval-Augmented Generation (RAG).
Contextual Retrieval không chỉ sử dụng đối sánh từ khóa truyền thống và tìm kiếm ngữ nghĩa, mà còn hiểu sâu sắc ngữ cảnh của truy vấn và nhiệm vụ của người dùng để cung cấp thông tin chính xác và phù hợp hơn. Đặc biệt hiệu quả đối với các nhiệm vụ yêu cầu hiểu biết ngữ cảnh, như lập trình và câu hỏi kỹ thuật.
Bài viết này sẽ giới thiệu tổng quan về Contextual Retrieval.
Trước khi vào chủ đề chính, đối với những ai muốn kiểm tra AI tạo sinh là gì hoặc ChatGPT là gì, vui lòng tham khảo các bài viết sau.
Contextual Retrieval là gì?
Contextual Retrieval là một phương pháp cải thiện độ chính xác của tìm kiếm RAG bằng cách thêm thông tin ngữ cảnh vào các mảnh thông tin (chunks) được truy xuất từ kho kiến thức trong quá trình RAG.
Trong RAG, các tài liệu được chia thành các mảnh nhỏ để tạo ra các embeddings. Tuy nhiên, nếu các mảnh thiếu thông tin ngữ cảnh đủ, độ chính xác của việc tìm kiếm có thể giảm.
Contextual Retrieval giải quyết vấn đề này bằng cách thêm thông tin ngữ cảnh vào các mảnh trước khi tạo embeddings. Cụ thể, nó sử dụng các mô hình ngôn ngữ lớn (LLM) để tạo ra các giải thích ngữ cảnh ngắn gọn cho từng mảnh và thêm vào đầu mỗi mảnh.
Cơ chế hoạt động của Contextual Retrieval
Contextual Retrieval bao gồm các quy trình sau:
- Chia tài liệu thành mảnh: Đầu tiên, tài liệu được chia thành các đơn vị có nghĩa (mảnh). Có nhiều phương pháp khác nhau để chia nhỏ, chẳng hạn như dựa trên số ký tự cố định, ranh giới câu, hoặc tiêu đề.
- Tạo thông tin ngữ cảnh: Sử dụng LLM để tạo thông tin ngữ cảnh cho từng mảnh dựa trên nội dung của toàn bộ tài liệu. Ví dụ, nếu một mảnh có nội dung “So với quý trước, doanh thu của công ty đã tăng 3%”, LLM sẽ phân tích tài liệu và tạo ra ngữ cảnh như “Mảnh này lấy từ hồ sơ SEC của ACME cho quý 2 năm 2023. Doanh thu quý trước là… và lợi nhuận hoạt động là…”.
- Thêm ngữ cảnh vào mảnh: Thông tin ngữ cảnh được tạo ra sẽ được thêm vào đầu của mỗi mảnh.
- Tạo embeddings: Sử dụng mô hình embeddings để tạo embeddings cho các mảnh đã được thêm thông tin ngữ cảnh.
Ví dụ về việc chia mảnh trong RAG thông thường so với Contextual Retrieval
Chia mảnh trong RAG thông thường: Tài liệu được chia thành các mảnh dựa trên số ký tự cố định.
Mảnh 1: “ACME đã công bố kết quả quý 2 năm 2023. Doanh thu tăng 10% so với cùng kỳ năm trước…”
Mảnh 2: “…So với quý trước, doanh thu của công ty đã tăng 3%. Đây là…”
Mảnh 3: “…Doanh số bán sản phẩm mới đã tăng mạnh.”
Chia mảnh với Contextual Retrieval: Tài liệu được chia thành các mảnh và thêm thông tin ngữ cảnh.
Mảnh 1: “Mảnh này lấy từ hồ sơ SEC của ACME cho quý 2 năm 2023. Doanh thu quý trước là… và lợi nhuận hoạt động là… ACME đã công bố kết quả quý 2 năm 2023. Doanh thu tăng 10% so với cùng kỳ năm trước…”
Mảnh 2: “Mảnh này lấy từ hồ sơ SEC của ACME cho quý 2 năm 2023. Doanh thu quý trước là… và lợi nhuận hoạt động là… So với quý trước, doanh thu của công ty đã tăng 3%. Đây là…”
Mảnh 3: “Mảnh này lấy từ hồ sơ SEC của ACME cho quý 2 năm 2023. Doanh thu quý trước là… và lợi nhuận hoạt động là… Doanh số bán sản phẩm mới đã tăng mạnh.”
Bằng cách này, Contextual Retrieval làm rõ từng mảnh liên quan đến phần nào của tài liệu và cải thiện độ chính xác của việc tìm kiếm bằng cách làm nổi bật mối quan hệ của mảnh với nội dung xung quanh.
Sự khác biệt so với RAG thông thường
Trong RAG thông thường, embeddings được tạo ra chỉ từ văn bản của mảnh. Tuy nhiên, trong Contextual Retrieval, embeddings phản ánh cả văn bản của mảnh
Cơ Chế Tìm Kiếm Thông Tin Trong Contextual Retrieval
Contextual Embeddings và Contextual BM25
Trong Contextual Retrieval, quá trình tìm kiếm thông tin được thực hiện qua các bước sau để thu thập thông tin có liên quan cao một cách hiệu quả dựa trên truy vấn của người dùng:
- Phân Tích Truy Vấn: Truy vấn của người dùng được phân tích để trích xuất từ khóa, cụm từ và ý định tìm kiếm.
- Lấy Embedding: Dựa trên kết quả phân tích truy vấn, vector embedding tương ứng với truy vấn được tạo.
- Tính Toán Độ Tương Tự: Vector embedding của truy vấn được so sánh với các vector embedding của các mảnh (chunks) được lưu trữ trong cơ sở tri thức, và độ tương tự của chúng được tính toán.
- Chọn Lọc Các Mảnh: Dựa trên kết quả tính toán độ tương tự, các mảnh liên quan nhất được chọn từ những mảnh xếp hạng cao nhất.
- Trích Xuất Thông Tin: Thông tin phù hợp để trả lời truy vấn được trích xuất từ các mảnh đã chọn.
- Tạo Phản Hồi: Dựa trên thông tin đã trích xuất, phản hồi được tạo ra và gửi cho người dùng
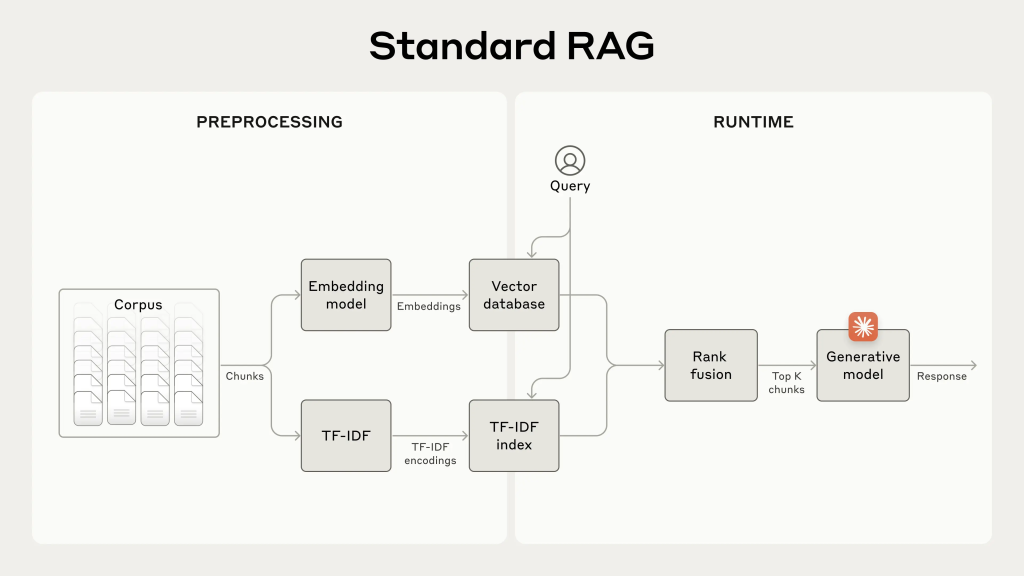
Cơ chế RAG Truyền Thống
Nguồn: Hình minh họa được biên tập bởi tác giả và công bố tại https://www.anthropic.com/news/contextual-retrieval.
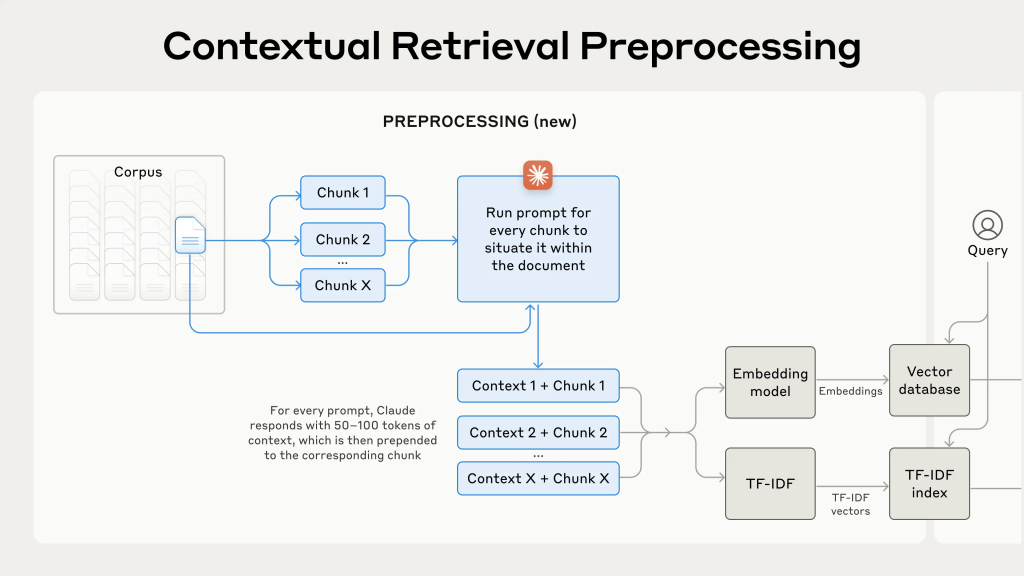
Tiền Xử Lý Trong Contextual Retrieval
Nguồn: Hình minh họa được biên tập bởi tác giả và công bố tại https://www.anthropic.com/news/contextual-retrieval.
Trong Contextual Retrieval, hai phương pháp—Contextual Embeddings và Contextual BM25—có thể được kết hợp để thực hiện việc tìm kiếm thông tin sử dụng ngữ cảnh.
- Contextual Embeddings: Các embedding được tạo ra cho các mảnh đã thêm thông tin ngữ cảnh, sử dụng mô hình embedding. Điều này cho phép tìm kiếm dựa trên sự tương đồng về ngữ nghĩa.
- Contextual BM25: BM25 là một phương pháp phổ biến trong việc tìm kiếm thông tin, chấm điểm mức độ liên quan của một tài liệu dựa trên sự trùng khớp giữa từ khóa của truy vấn và từ khóa trong tài liệu. Contextual BM25 áp dụng BM25 cho các mảnh có thêm thông tin ngữ cảnh, cho phép tìm kiếm không chỉ xét sự trùng khớp từ khóa mà còn xét đến thông tin ngữ cảnh.
Bằng cách kết hợp hai phương pháp này, cả sự tương đồng về ngữ nghĩa và sự trùng khớp từ khóa được đánh giá toàn diện để thu được kết quả tìm kiếm chính xác hơn.
Sự Kết Hợp Giữa Contextual Embeddings và Contextual BM25
Contextual Embeddings và Contextual BM25 phối hợp với nhau qua quy trình sau:
- Điểm số được tính toán cho truy vấn sử dụng cả Contextual Embeddings và Contextual BM25.
- Các điểm số này được tích hợp dựa trên trọng số được thiết lập trước.
- Dựa trên điểm số tích hợp, bảng xếp hạng các mảnh được tạo ra.
BM25 và TF-IDF
BM25 là phiên bản mở rộng của TF-IDF (Term Frequency-Inverse Document Frequency). TF-IDF tính toán tầm quan trọng của một từ trong tài liệu dựa trên tần suất xuất hiện của từ đó trong tài liệu (Tần Suất Xuất Hiện Từ) và nghịch đảo tần suất xuất hiện của từ đó trong các tài liệu khác (Tần Suất Xuất Hiện Từ Nghịch Đảo). BM25 cải tiến TF-IDF bằng cách xem xét thêm các yếu tố như độ dài của tài liệu và số từ trong truy vấn, giúp đạt được độ chính xác cao hơn khi chấm điểm.
Kết Quả Đánh Giá Hiệu Suất (Benchmark Results)
Anthropic đã đánh giá hiệu suất của Contextual Retrieval trên nhiều bộ dữ liệu khác nhau, bao gồm các cơ sở mã nguồn, tiểu thuyết, bài báo ArXiv, và các bài báo khoa học. Chỉ số đánh giá được sử dụng là recall@20, đo lường xem trong 20 mảnh hàng đầu có chứa tài liệu liên quan hay không.
Kết quả cho thấy Contextual Retrieval đã cải thiện độ chính xác của việc tìm kiếm so với RAG truyền thống:
- Khi chỉ sử dụng Contextual Embeddings, tỷ lệ thất bại khi tìm kiếm 20 mảnh hàng đầu giảm 35% (từ 5.7% xuống 3.7%).
- Khi kết hợp Contextual Embeddings và Contextual BM25, tỷ lệ thất bại giảm 49% (từ 5.7% xuống 2.9%).
- Thêm vào đó, khi bổ sung một bước xếp hạng lại bằng mô hình của Cohere, tỷ lệ thất bại khi tìm kiếm 20 mảnh hàng đầu giảm 67% (từ 5.7% xuống 1.9%).
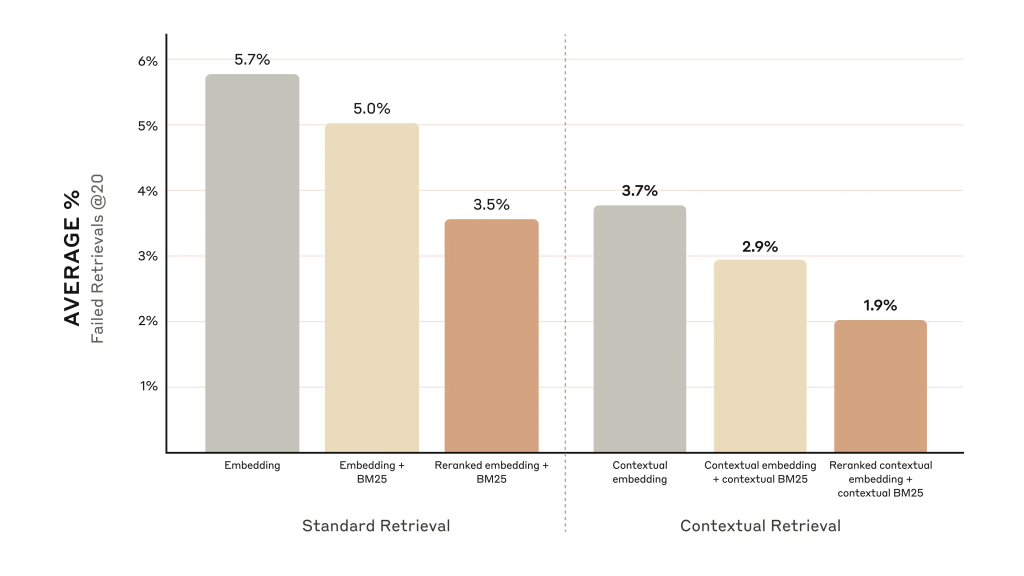
So sánh tỷ lệ thất bại của việc tìm kiếm khi chỉ sử dụng Contextual Embeddings và khi kết hợp với Contextual BM25.
Nguồn: https://www.anthropic.com/news/contextual-retrieval
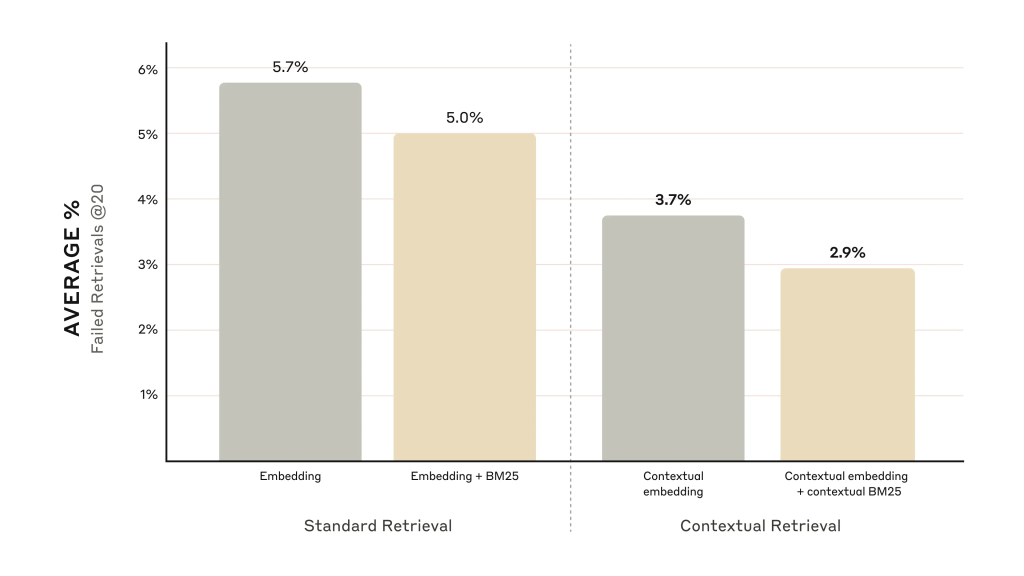
So sánh tỷ lệ thất bại khi có xếp hạng lại.
Nguồn: https://www.anthropic.com/news/contextual-retrieval
Ví Dụ Về Việc Thực Hiện Contextual Retrieval
Ví dụ về thiết kế lời nhắc (Prompt Design Example)
<document>
{{Nội dung của toàn bộ tài liệu}}
</document>
Dưới đây là các mảnh cần được đặt trong tài liệu.
<chunk>
{{Nội dung của mảnh}}
</chunk>
Hãy mô tả ngắn gọn ngữ cảnh để định vị mảnh này trong toàn bộ tài liệu nhằm cải thiện khả năng tìm kiếm của nó. Chỉ cung cấp ngữ cảnh ngắn gọn, không gì khác.
Lời nhắc này hướng dẫn LLM phân tích nội dung của cả tài liệu và mảnh, tạo ra ngữ cảnh để giải thích phần nào của tài liệu mà mảnh đó đề cập đến.
Ví dụ, nếu toàn bộ tài liệu là báo cáo hiệu suất hàng năm của một công ty và mảnh chứa nội dung “Doanh thu của quý 2 đã tăng 10% so với cùng kỳ năm trước”, LLM sẽ tạo ngữ cảnh như, “Mảnh này đề cập đến phần trong báo cáo hiệu suất hàng năm của công ty về kết quả quý 2.”
Ví Dụ Về Việc Thực Hiện Contextual Retrieval
Dưới đây là một ví dụ thực hiện đơn giản về Contextual Retrieval sử dụng Python và LangChain. Để biết thêm chi tiết, vui lòng tham khảo ví dụ được công bố bởi Anthropic.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# Đặt khóa API của OpenAI
import os
os.environ[“OPENAI_API_KEY”] = “YOUR_OPENAI_API_KEY”
# Khởi tạo mô hình embedding và LLM
embeddings = OpenAIEmbeddings()
llm = OpenAI(temperature=0)
# Tải tài liệu và chia thành các mảnh
with open(“document.txt”, “r”) as f:
document = f.read()
chunks = document.split(“\n\n”) # Chia thành các mảnh dựa trên dòng trống
# Tạo thông tin ngữ cảnh cho mỗi mảnh
contextualized_chunks = []
for chunk in chunks:
context = llm(f”””
<document>
{{Nội dung của toàn bộ tài liệu}}
</document>
Đây là mảnh cần được đặt trong toàn bộ tài liệu.
<chunk>
{{Nội dung của mảnh}}
</chunk>
Hãy mô tả một ngữ cảnh ngắn gọn để định vị mảnh này trong toàn bộ tài liệu nhằm cải thiện khả năng tìm kiếm của nó. Chỉ cung cấp ngữ cảnh ngắn gọn.
“””)
contextualized_chunks.append(f”{context} {chunk}”)
# Lưu các mảnh đã có ngữ cảnh vào cơ sở dữ liệu vector
db = Chroma.from_texts(contextualized_chunks, embeddings)
# Tạo chuỗi RetrievalQA
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=llm, chain_type=”stuff”, retriever=retriever)
# Nhập truy vấn và lấy câu trả lời
query = “Kết quả quý 2 của công ty như thế nào?”
answer = qa.run(query)
# Xuất câu trả lời
print(answer)
Giải Thích Mã
- Các thư viện cần thiết được nhập.
- Đặt khóa API của OpenAI.
- Khởi tạo mô hình embedding và LLM.
- Tài liệu được tải và chia thành các mảnh.
- Thông tin ngữ cảnh được tạo cho mỗi mảnh.
- Các mảnh có thông tin ngữ cảnh được lưu vào cơ sở dữ liệu vector.
- Chuỗi RetrievalQA được tạo.
- Nhập truy vấn và lấy câu trả lời tương ứng.
- Xuất câu trả lời.
Các Ứng Dụng và Triển Vọng Tương Lai của Contextual Retrieval
Contextual Retrieval là một phương pháp hiệu quả để giải quyết các vấn đề mà RAG truyền thống gặp phải, nhưng nó cũng đặt ra một số thách thức:
- Chi Phí Tính Toán: Do sử dụng LLM để tạo ra thông tin ngữ cảnh, chi phí tính toán có thể cao hơn so với RAG truyền thống.
- Độ Trễ: Việc bổ sung xử lý tạo thông tin ngữ cảnh có thể làm chậm thời gian phản hồi.
- Kỹ Thuật Thiết Kế Lời Nhắc (Prompt Engineering): Chất lượng của thông tin ngữ cảnh do LLM tạo ra phụ thuộc nhiều vào thiết kế của lời nhắc. Việc thiết kế lời nhắc hiệu quả là rất cần thiết để tạo ra thông tin ngữ cảnh phù hợp.
Mặc dù là một công nghệ còn tương đối mới, Contextual Retrieval đã thu hút sự chú ý của nhiều công ty và tổ chức nghiên cứu. Ví dụ, Google đang xem xét việc tích hợp công nghệ này vào các thuật toán xếp hạng của công cụ tìm kiếm, và Microsoft đang đưa công nghệ này vào công cụ tìm kiếm Bing.
Trong tương lai, Contextual Retrieval dự kiến sẽ được áp dụng trong nhiều lĩnh vực khác nhau, bao gồm chatbot AI, hệ thống hỏi đáp, và dịch máy. Hơn nữa, khi các mô hình ngôn ngữ lớn (LLM) tiếp tục phát triển, độ chính xác của Contextual Retrieval sẽ ngày càng được nâng cao nhờ khả năng hiểu ngữ cảnh sâu sắc hơn.

Tác Giả Bài Viết: Tomohide Kakeya
Giám Đốc Điều Hành Công Ty Cổ Phần Scuti.
Sau khi làm việc trong lĩnh vực phát triển firmware cho máy ảnh DSLR và thiết kế, triển khai, quản lý các hệ thống quảng cáo, Tomohide Kakeya đã chuyển đến Việt Nam vào năm 2012.
Năm 2015, ông thành lập Công ty Cổ phần Scootie và bắt đầu phát triển hoạt động kinh doanh offshore tại Việt Nam.
Gần đây, ông tập trung vào tích hợp hệ thống với ChatGPT và phát triển sản phẩm sử dụng AI sinh tạo. Ngoài ra, ông còn phát triển ứng dụng sử dụng OpenAI API và Dify như một sở thích cá nhân.