
Are you familiar with RAG (Retrieval Augmented Generation), which is garnering attention in the field of generative AI? RAG is the latest technology designed to enhance the accuracy of responses from LLMs (Large Language Models), and major cloud vendors such as AWS and Azure are advancing its implementation. By understanding the mechanism of RAG, it is possible to generate high-quality answers that surpass those of ChatGPT. This article will provide a detailed explanation of RAG’s basic mechanisms, specific applications, and examples.
Overview of RAG

Basic Principles of RAG
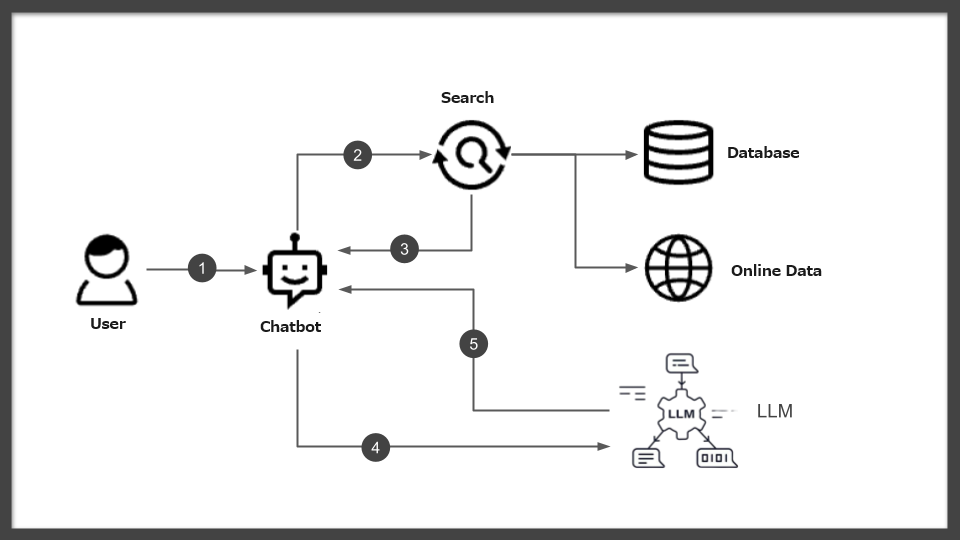
RAG (Retrieval Augmented Generation) is a groundbreaking technology that significantly enhances the accuracy of generative AI responses. This technology is based on a unique mechanism that improves the quality of answers provided by Large Language Models (LLMs) by skillfully incorporating information from external databases and knowledge bases.
Specifically, in response to user queries, RAG dynamically searches for relevant external information and restructures the answer based on this information. Through this process, generative AI can provide more accurate responses, sometimes based on the latest information.
For instance, AWS uses this innovative technology to base responses of models like ChatGPT on specific data and facts. In Azure’s services, RAG is used to generate customized responses based on specific corporate knowledge. Moreover, Oracle has also implemented RAG to significantly enhance the accuracy of responses to business-specific questions.
As these examples illustrate, RAG maximizes the potential of generative AI and LLMs, significantly expanding the scope and precision of their responses. Notably, RAG has become an accessible technology for a broader range of developers through major platforms like AWS and Azure. This makes RAG a promising and appealing technology for engineers with experience in developing with the ChatGPT API or Azure OpenAI Service.
Key Technical Elements and Functions of RAG
The core technological elements of RAG (Retrieval Augmented Generation) lie in the mechanisms for searching and integrating external information. This innovative technology significantly enhances the quality of responses generated by AI by identifying the most relevant information to a specific query and skillfully integrating it into the knowledge system of an LLM (Large Language Model). RAG’s functionality includes improving the precision and timeliness of information, which makes the responses it generates more specific and reliable.
One notable role of RAG is its ability to expand the existing knowledge base of an LLM and make new sources of information available. For example, AWS uses RAG to extract the latest information from cloud-based databases, and Azure utilizes it to generate customized responses in cooperation with company-specific knowledge bases. Moreover, Oracle uses RAG to provide answers specialized to certain industries or fields, thus greatly expanding the applicability of generative AI.
Furthermore, RAG possesses the ability to significantly improve key metrics for generative AI, such as the accuracy and relevance of responses. This is because generative AI actively utilizes external information, not only possessing extensive knowledge but also developing the ability to select and tailor the most appropriate responses to specific queries.
Thus, RAG provides innovative technical elements and functionalities for generative AI and LLMs, enabling more advanced natural language processing capabilities and flexible response generation tailored to individual needs. This allows engineers to develop more sophisticated systems while collaborating with existing APIs such as ChatGPT and Azure OpenAI Service.
Application Examples of RAG Technology

Introduction to Industry-Specific Applications
The application range of RAG (Retrieval Augmented Generation) technology is broad, and its benefits are increasingly recognized across various industries. This technology allows for the provision of customized answers tailored to specific industries and needs by combining the capabilities of generative AI and LLMs (Large Language Models). Incorporating industry-specific expertise and generating high-quality answers based on that information is a crucial function of RAG.
For example, in the healthcare industry, RAG is utilized to provide patients and medical professionals with information about the latest research findings and treatments. RAG can find relevant information from extensive medical databases and integrate it into LLMs to generate detailed and accurate answers about specific symptoms and diseases.
In the finance sector, RAG is used to provide customers with the latest information about market trends and financial products. It quickly incorporates specific market data and trends, allowing for timely and accurate responses to customer inquiries.
Furthermore, in the field of customer support, RAG is helpful in managing FAQs and troubleshooting information related to products and services, providing accurate responses to specific customer inquiries. This contributes to improved customer satisfaction and efficient support operations.
These examples show that RAG expands the potential applications of generative AI and serves as a valuable tool for providing solutions to specific industries and problems. Engineers are expected to build RAG mechanisms tailored to industry-specific needs using existing APIs like ChatGPT and Azure OpenAI Service, aiming to deliver higher quality services.
Successful Applications of RAG
The RAG (Retrieval-Augmented Generation) technology has significantly expanded the application range of generative AI with its unique approach. According to information from major technology companies like AWS, Microsoft Azure, and Oracle, RAG notably improves the accuracy and timeliness of information, greatly enhancing user experience. These platforms utilize RAG to optimize the outputs of large language models (LLMs), providing more relevant answers.
AWS reports that RAG enhances the relevance and accuracy of responses by referencing external, reliable knowledge bases. This process allows users to receive information based on the latest research and news, consequently increasing their trust and satisfaction.
At Microsoft Azure, the integration of RAG in Azure AI Search is emphasized for improving the precision of information retrieval in enterprise solutions. It is particularly noted for its ability to generate more accurate and specific responses to questions about internal content and documents. This directly contributes to the efficiency of business processes and ultimately leads to improved customer satisfaction.
Oracle mentions that RAG technology enhances chatbots and other conversational systems, enabling them to provide timely and context-appropriate responses to users. RAG facilitates the rapid extraction and search of data, significantly improving answer generation by LLMs.
From this information, it is evident that the implementation of RAG has achieved notable results in various fields such as customer support, enterprise search, and conversational AI. Although specific figures and data are not provided, the effects of RAG technology are transformative, redefining the use of generative AI and maximizing its potential.
Implementation and Operation of RAG Technology

RAG in Major Cloud Services
Amazon, Microsoft, and Oracle offer various services and tools to make the use of RAG (Retrieval-Augmented Generation) technology more accessible. These services aim to extend the capabilities of generative AI and allow engineers to customize it for specific applications and business needs.
Amazon Web Services (AWS) supports the implementation of RAG through an enterprise search service called Amazon Kendra. Amazon Kendra utilizes natural language processing (NLP) to extract meaningful information from unstructured text and incorporate it into the response generation process of a Large Language Model (LLM). This service enables direct integration with the knowledge bases and document repositories owned by businesses, allowing the search results to be used as inputs for generative AI.
Microsoft Azure provides a search service called Azure AI Search. This service supports vector and semantic searches, enabling engineers to index their company’s content in a searchable format and use it as part of the RAG pattern. Azure AI Search offers a valuable tool for integrating enterprise content into the generative AI response generation process, helping to produce more relevant answers.
Oracle supports RAG through the OCI Generative AI service running on Oracle Cloud Infrastructure (OCI). This service allows for the creation of customizable generative AI models and the utilization of company-specific datasets and knowledge bases. Engineers can use this service to develop generative AI applications tailored to business needs and incorporate specific information from within the organization into the response generation process.
From a technical perspective, these services provide a robust foundation for engineers to flexibly implement the RAG mechanism and optimize generative AI for specific purposes. By leveraging the unique features of each platform, engineers can unlock the potential of generative AI and deliver higher-quality information services.
Criteria for Selecting RAG Technology
The criteria for choosing RAG (Retrieval-Augmented Generation) technology are essential for engineers to identify the best solution for their projects or organizational needs. The selection process centers on technical aspects, cost efficiency, and ease of integration.
Firstly, from a technical perspective, it is crucial to evaluate whether the RAG solution offers flexibility and customization options to address specific applications or industry-specific challenges. Considerations should include the types and formats of data held by the company and how these can be integrated with generative AI. Additionally, the diversity of the information sources targeted, their update frequency, and the accuracy and relevance of the search results are factors that directly impact system performance.
Cost efficiency is another significant consideration when implementing RAG technology. Training and operating large language models (LLMs) often involve substantial costs, so choosing a solution that offers maximum value within the budget is essential. This includes considering the pricing of API access provided by the platform, the costs of the necessary infrastructure, and the long-term operational costs.
Lastly, ease of integration is a crucial criterion. Ensuring that the chosen RAG solution can be smoothly integrated into existing systems and workflows is directly linked to project success. This requires evaluating the comprehensiveness of API documentation, the support structure for developers, and compatibility with the existing technical stack.
Based on these criteria, the selection of RAG technology should be carefully made according to the specific requirements and goals of the project. Choosing the optimal solution enables the unlocking of the potential of generative AI and the realization of higher-quality information services.
Steps for Implementing RAG Technology
The implementation of RAG (Retrieval-Augmented Generation) technology is a critical step for companies to leverage generative AI to deliver more accurate information. The implementation process includes several key phases, from planning and execution to evaluation. Here, we outline the main steps for effectively deploying RAG technology.
The first step is to clarify the objectives. Clearly define the purpose of implementing RAG, the problems it aims to solve, and the value it is expected to provide. At this stage, consider in detail the needs of the target users and the specific processes you aim to improve.
Next, assess the technical requirements. The introduction of RAG technology involves a wide range of technical requirements, including selecting the appropriate data sources and integrating with existing systems. Evaluate the available cloud services, databases, and AI model capabilities to choose the technology stack that best fits the project’s goals.
The creation of an implementation plan follows. Based on the objectives and technical requirements, develop a detailed plan for deployment. This plan should include the implementation schedule, necessary resources, budget, and risk management plans. The roles and responsibilities of team members are also defined at this stage.
The RAG system will be constructed based on the plan during the implementation phase. This involves preparing the data, training the AI models, integrating the systems, and developing the user interface. Regular reviews and testing during the implementation process are crucial for early detection and resolution of any issues.
Finally, evaluation and optimization post-implementation take place. Once the system is deployed in a real-world environment, assess its performance and collect feedback from users. Based on this information, continuously improve and optimize the system.
Through these steps, companies can successfully implement RAG technology and unlock the potential of generative AI. The implementation process is complex and multifaceted, necessitating a planned and phased approach.