We make services people love by the power of Gen AI.

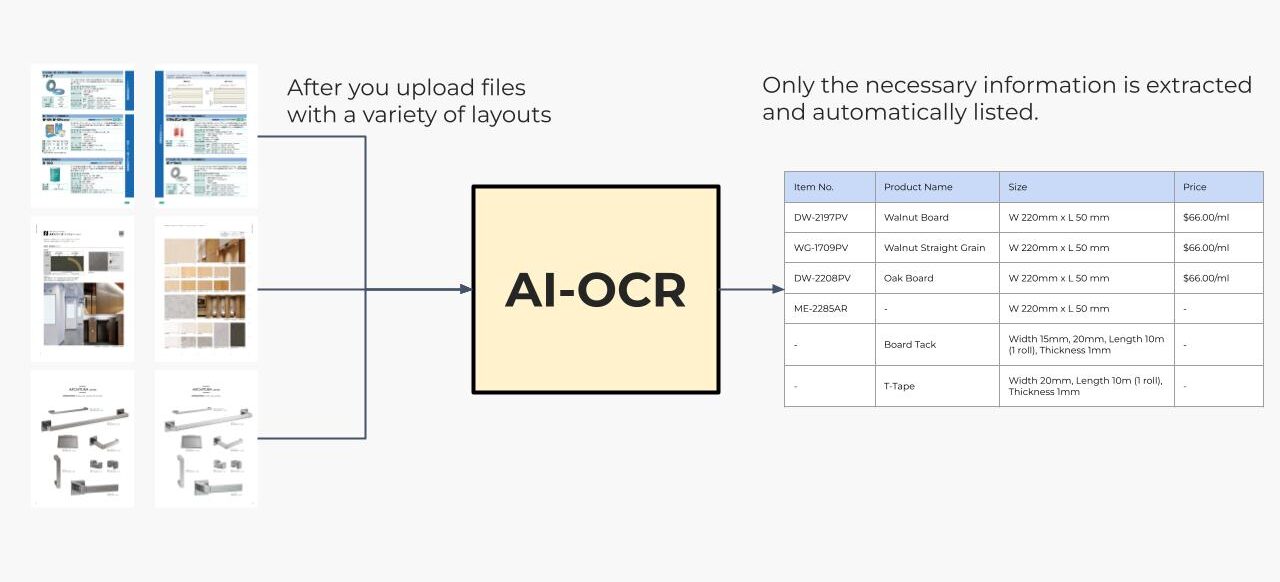
Manually copy and paste product information from the product catalog into Excel.
In manufacturing, trading, and e-commerce, many companies manually copy and paste data from supplier catalogs into one place. Is yours one of them?

Manually enter candidate information from handwritten resumes.
Many companies require candidates to submit handwritten resumes, but do you manually enter the candidate information from those resumes into Excel or a recruitment management system?

Manually inputting data from handwritten delivery notes sent by fax
How do you handle data on purchase orders and delivery notes sent by fax? Are you not digitizing it at all, or are you manually entering it into your company's system?
Automate Information Extraction
We can automate the task of extracting only the necessary information from a large volume of documents and listing or entering it into a system, which exists within your company or department. This will provide you with a clear cost-effectiveness in the form of reduced labor costs

Supports Multiple Formats, Including Handwriting
Unlike traditional OCR services, there’s no need to fix the document format in advance. Our solution can read and extract information from documents with flexible formats, making it easier to handle various real-world cases. It also supports handwritten documents, ensuring greater versatility.

You can build a system tailored to your actual operations.
The extracted data can be output in various formats, such as CSV, Excel, or API for linking with external systems. Furthermore, it is also possible to build management functions other than the reading function so that multiple employees can use it according to your company's operations