🧠 I Built a Real-Time Translator Web App Running a Local LLM on My Mac M1
Recently, I had a small idea: to create a real-time speech translation tool for meetings, but instead of relying on online APIs, I wanted everything to run completely local on my Mac M1.
The result is a web demo that lets users speak into the mic → transcribe speech → translate in real-time → display bilingual subtitles on screen.
The average response time is about 1 second, which is fast enough for real-time conversations or meetings.
🎙️ How the App Works
The app follows a simple pipeline:
-
SpeechRecognition in the browser converts voice into text.
-
The text is then sent to a local LLM hosted via LM Studio for translation (e.g., English ↔ Vietnamese).
-
The translated text is displayed instantly as subtitles on the screen.
My goal was to experiment with real-time translation for live meetings — for example, when someone speaks English, the listener can instantly see the Vietnamese subtitle (and vice versa).
⚙️ My Setup and Model Choice
I’m using a Mac mini M1 with 16GB RAM and 12GB of available VRAM via Metal GPU.
After testing many small models — from 1B to 7B — I found that google/gemma-3-4b provides the best balance between speed, accuracy, and context awareness.
Key highlights of google/gemma-3-4b:
-
⚡ Average response time: ~1 second on Mac M1
-
🧩 Context length: up to 131,072 tokens — allowing it to handle long conversations or paragraphs in a single prompt
-
💬 Translation quality: natural and faithful to meaning
-
🎯 Prompt obedience: follows structured prompts well, unlike smaller models that tend to drift off topic
I host the model using LM Studio, which makes running and managing local LLMs extremely simple.
With Metal GPU acceleration, the model runs smoothly without lag, even while the browser is processing audio in parallel.
🧰 LM Studio – Local LLMs Made Simple
One thing I really like about LM Studio is how simple it makes running local LLMs.
It’s a desktop app for macOS, Windows, and Linux that lets you download, run, and manage models without writing code, while still giving you powerful developer features.
Key features that made it perfect for my setup:
-
✅ Easy installation: download the
.dmg(for macOS) or installer for Windows/Linux and you’re ready in minutes. -
✅ Built-in model browser: browse models from sources like Hugging Face, choose quantization levels, and download directly inside the app.
-
✅ Local & public API: LM Studio can launch a local REST API server with OpenAI-compatible endpoints (
/v1/chat/completions,/v1/embeddings, etc.), which you can call from any app — including my translator web client. -
✅ Logs and performance monitoring: it displays live logs, token counts, generation speed, and resource usage (RAM, GPU VRAM, context window occupancy).
-
✅ No coding required: once the model is loaded, you can interact through the built-in console or external scripts using the API — perfect for prototyping.
-
✅ Ideal for local prototyping: for quick experiments like mine, LM Studio removes all setup friction — no Docker, no backend framework — just plug in your model and start testing.
Thanks to LM Studio, setting up the local LLM was nearly effortless.
🌐 About SpeechRecognition – It’s Still Cloud-Based
At first, I thought the SpeechRecognition API in browsers could work offline.
But in reality, it doesn’t:
On browsers like Chrome,
SpeechRecognition(orwebkitSpeechRecognition) sends the recorded audio to Google’s servers for processing.
As a result:
It can’t work offline
It depends on an internet connection
You don’t have control over the recognition engine
This means that while the translation part of my app runs entirely local, the speech recognition part still relies on an external service.
🧪 Real-World Test
To test the pipeline, I read a short passage from a fairy tale aloud.
The results were surprisingly good:
-
Subtitles appeared clearly, preserving the storytelling tone and rhythm of the original text.
-
No missing words as long as I spoke clearly and maintained a steady pace.
-
When I intentionally spoke too fast or slurred words, the system still kept up — but occasionally missed punctuation or merged phrases, something that could be improved with punctuation post-processing or a small buffering delay before sending text to the LLM.
Tips for smoother results:
-
Maintain a steady speaking rhythm, pausing naturally every 5–10 words.
-
Add punctuation normalization before rendering (or enable auto-punctuation when using Whisper).
-
Process short chunks (~2–3 seconds) and merge them for low latency and better context retention.
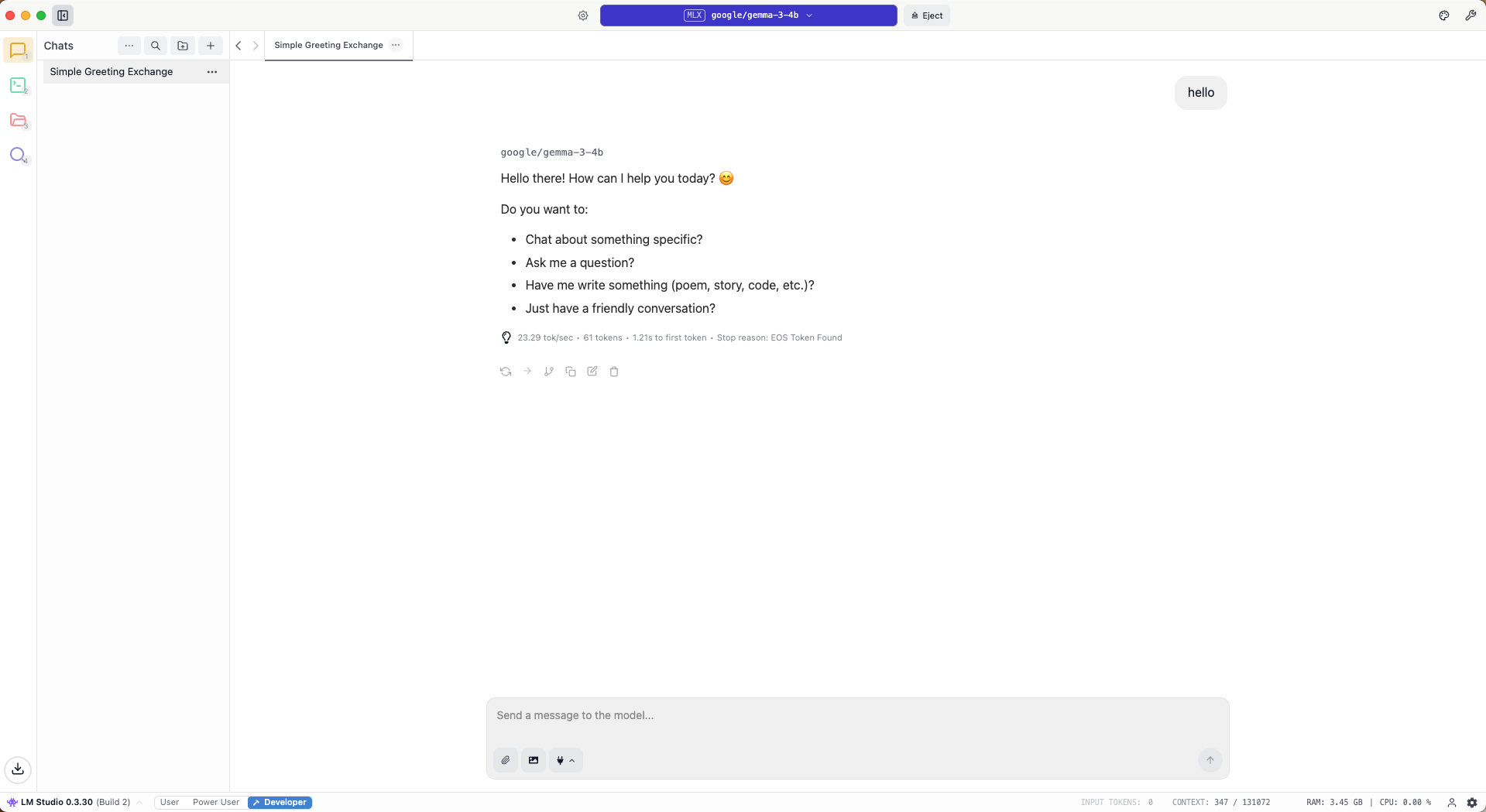
🧩 Some Demo Screenshots
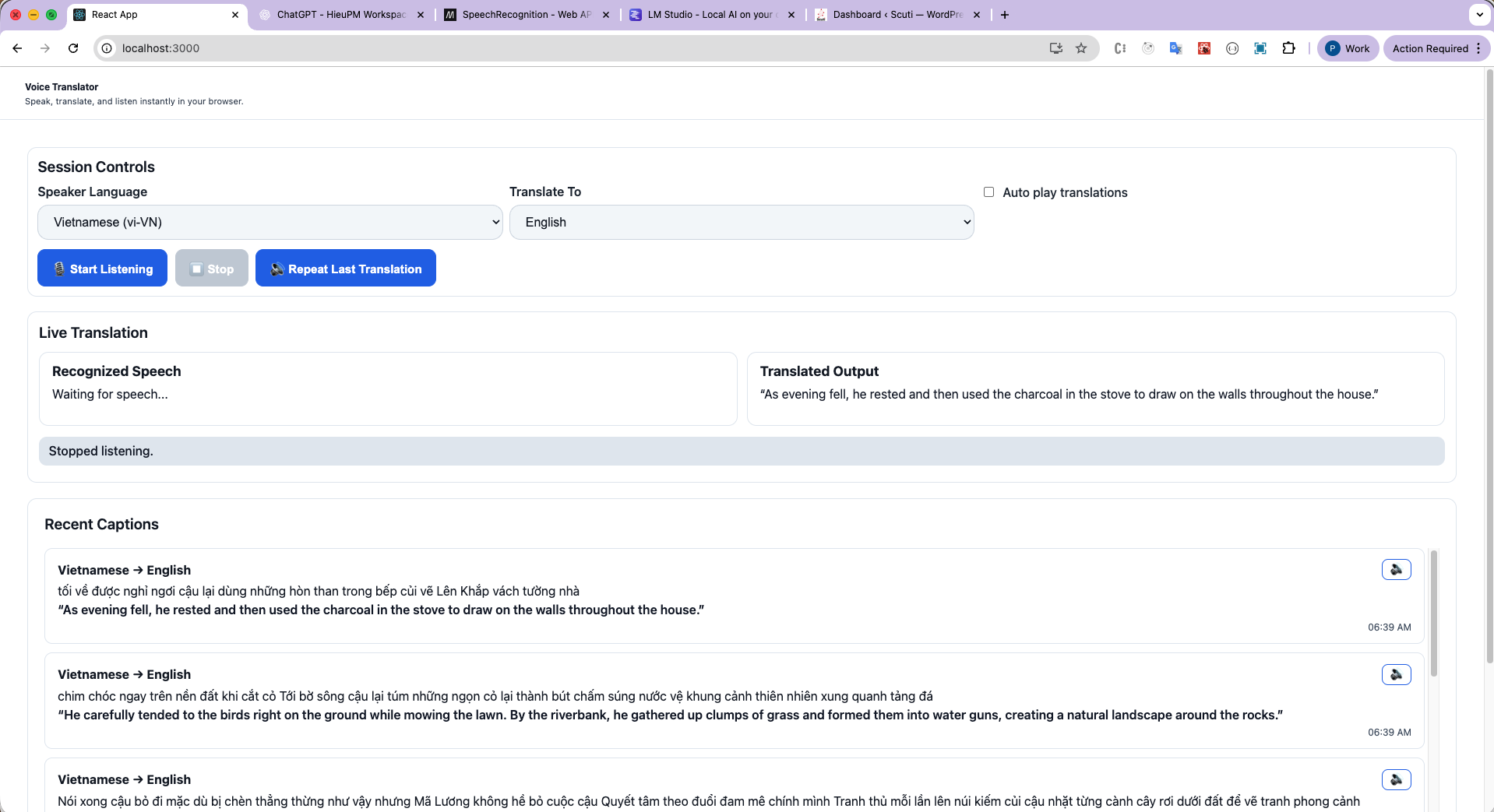
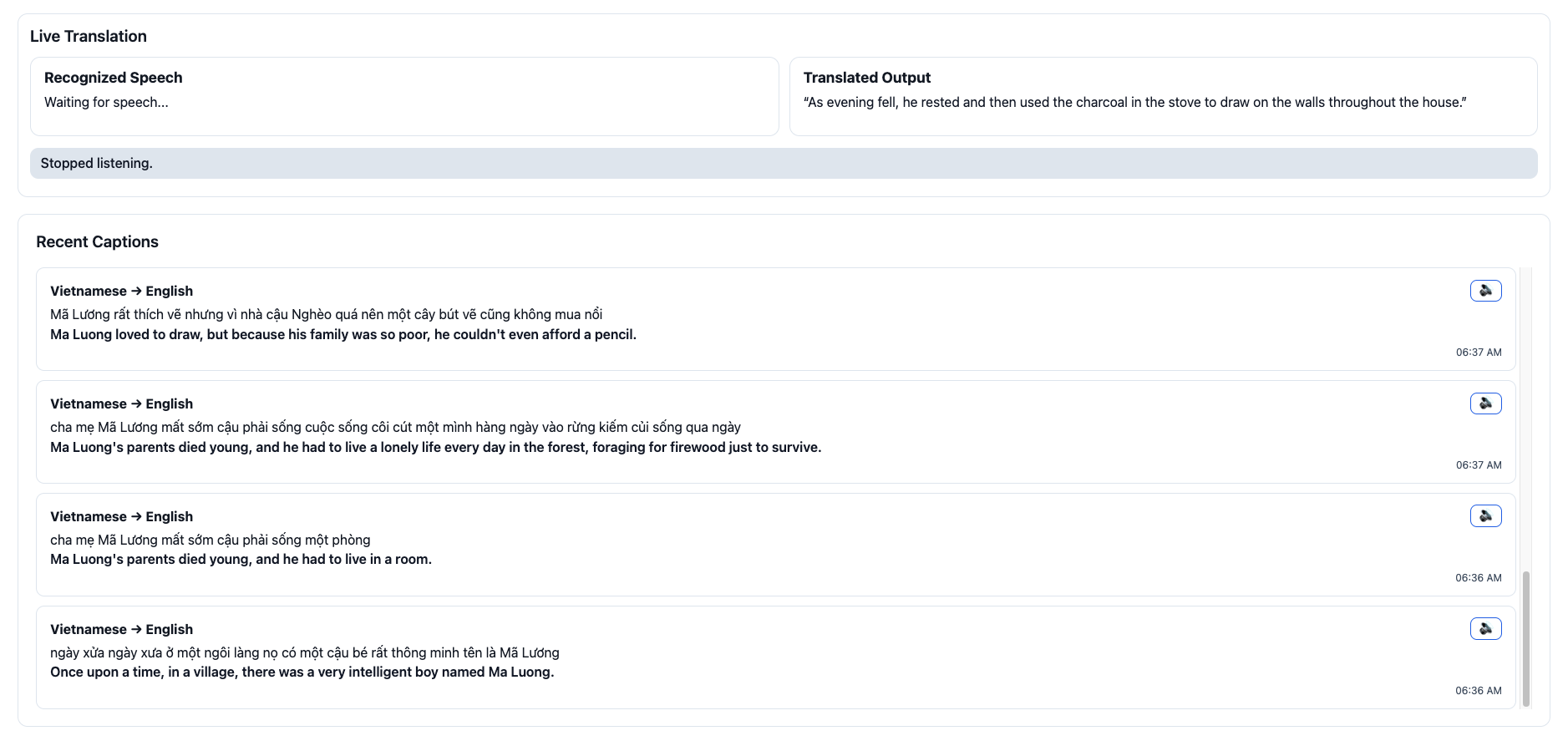
📷 Image 1 – Web Interface:
User speaks into the microphone; subtitles appear in real time below, showing both the original and translated text.
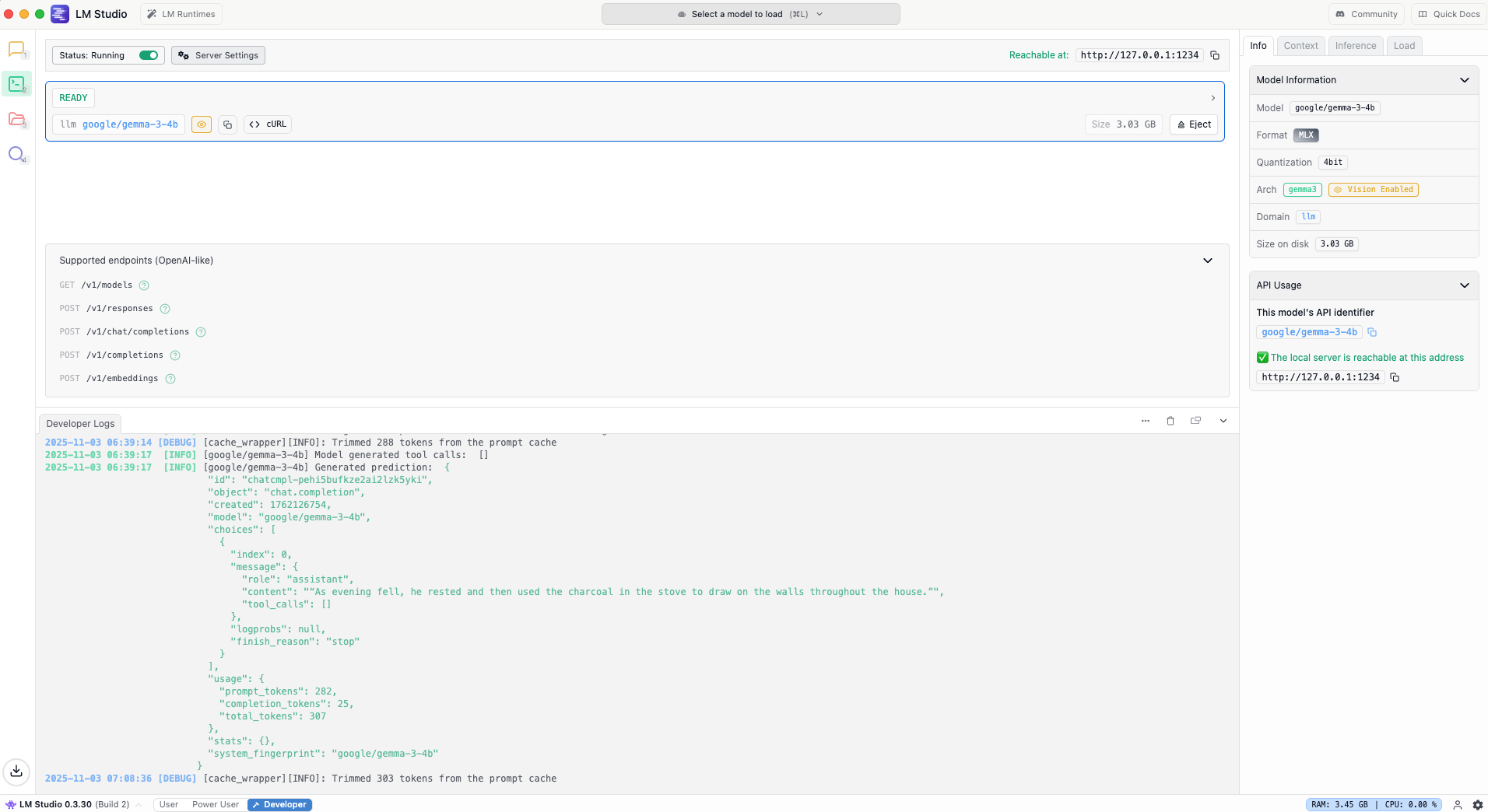
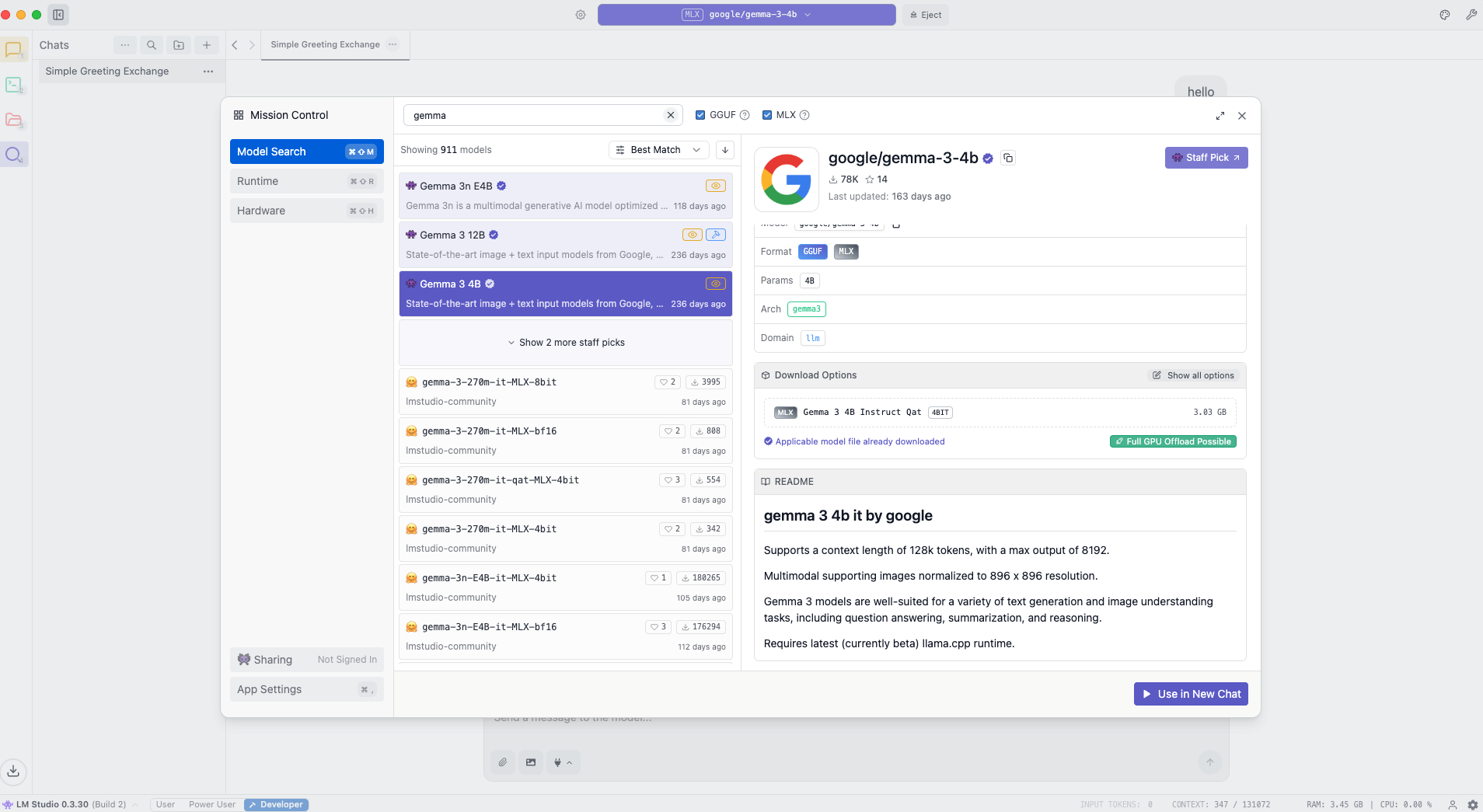
📷 Image 2 – LM Studio:google/gemma-3-4b running locally on Metal GPU inside LM Studio, showing logs and average response time.
🔭 Final Thoughts
This project is still a small experiment, but I’m truly impressed that a 4B parameter model running locally can handle real-time translation this well — especially with a 131K token context window, which allows it to keep track of long, coherent discussions.
With Whisper integrated locally, I believe it’s possible to build a fully offline real-time translation tool — useful for meetings, presentations, or any situation where data privacy matters.
✳️ In short:
If you’re looking for a small yet smart model that runs smoothly on a Mac M1 without a discrete GPU, I highly recommend trying google/gemma-3-4b with LM Studio.
Sometimes, a small but well-behaved model — with a huge context window — is all you need to unlock big ideas 🚀