
As organizations explore how to embed generative AI capabilities into their applications, many are leveraging large language models (LLMs) for tasks like content generation, summarization, or natural language interfaces. However, designing these systems for scalability, cost-efficiency, and agility can be challenging.
This blog post (Part 1 of a two-part series) introduces serverless architectural patterns for building real-time generative AI applications using AWS services. It provides guidance on design layers, execution models, and implementation considerations.
📐 Separation of Concerns: A 3-Tier Design
To manage complexity and improve maintainability, AWS recommends separating your application into three distinct layers:
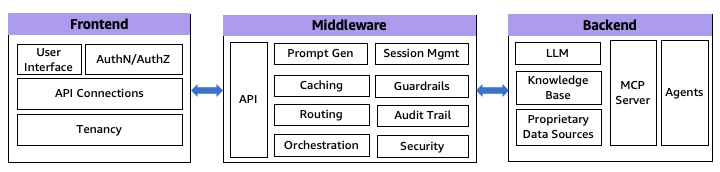
1. Frontend Layer – User Experience and Interaction
This layer manages user-facing interactions, including UI rendering, authentication, and client-to-server communication.
Tools and Services:
-
AWS Amplify: For rapid frontend development with built-in CI/CD.
-
Amazon CloudFront + S3: To host static sites securely and at scale.
-
Amazon Lex: To build conversational interfaces.
-
Amazon ECS/EKS: If using containerized web applications.
2. Middleware Layer – Integration and Control Logic
This is the central control hub and is subdivided into three critical sub-layers:
-
API Layer:
-
Interfaces via REST, GraphQL, or WebSockets.
-
Ensures secure, scalable access via API Gateway, AWS AppSync, or ALB.
-
Manages versioning, rate-limiting, authentication.
-
-
Prompt Engineering Layer:
-
Builds reusable prompt templates.
-
Handles prompt versioning, moderation, security, and caching.
-
Integrates with services like Amazon Bedrock, Amazon DynamoDB, and Amazon ElastiCache.
-
-
Orchestration Layer:
-
Manages session context, multi-step workflows, and agent-based processing.
-
Uses tools like AWS Step Functions, Amazon SQS, or event-driven orchestration frameworks such as LangChain or LlamaIndex.
-
3. Backend Layer – LLMs, Agents, and Data
This is where the actual generative AI models and enterprise data reside.
LLM Hosting Options:
-
Amazon Bedrock: Fully managed access to foundation models.
-
Amazon SageMaker: For training or hosting custom models.
-
Model Context Protocol (MCP): For containerized model servers.
For Retrieval Augmented Generation (RAG):
-
Amazon OpenSearch, Amazon Kendra, or Amazon Aurora PostgreSQL (pgVector) can index and retrieve relevant documents based on user queries.
⚡ Real-Time Execution Patterns
The article introduces three real-time architectural patterns to suit different UX and latency needs:
Pattern 1: Synchronous Request-Response
In this pattern, responses are generated and immediately delivered, while the client blocks/waits for response. Although this is simple to implement, has a predictable flow, and offers strong consistency, it suffers from blocking operations, high latency, and potential timeouts.
-
User sends a prompt, and the application returns a complete response.
-
Simple to implement and user-friendly for quick tasks.
-
Tradeoff: Limited by timeout constraints (e.g., API Gateway default 29s).
Use Cases:
-
Short-form responses
-
Structured data generation
-
Real-time form filling
This model can be implemented through several architectural approaches.
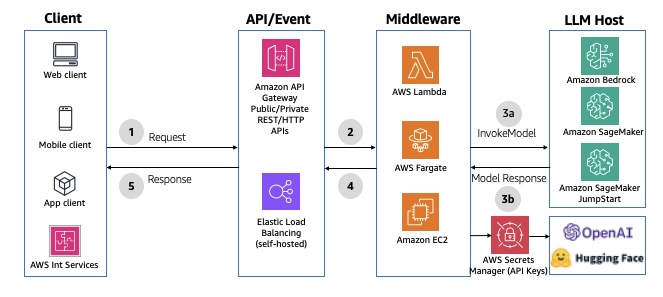
REST APIs
You can use RESTful APIs to communicate with your backend over HTTP requests. You can use REST or HTTP APIs in API Gateway or an Application Load Balancer for path-based routing to the middleware.
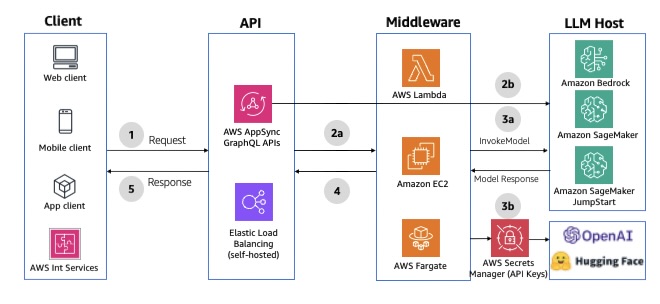
GraphQL HTTP APIs
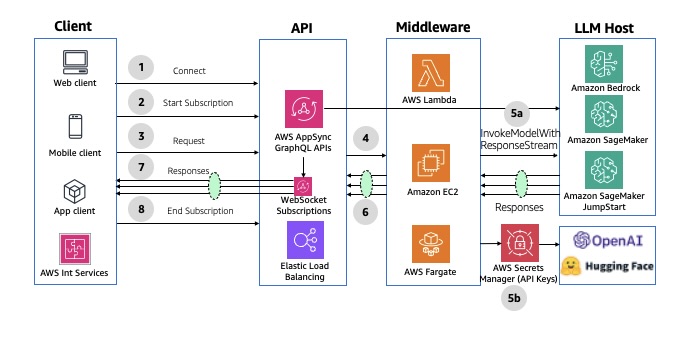
You can use AWS AppSync as the API layer to take advantage of the benefits of GraphQL APIs. GraphQL APIs offer declarative and efficient data fetching using a typed schema definition, serverless data caching, offline data synchronization, security, and fine-grained access control.
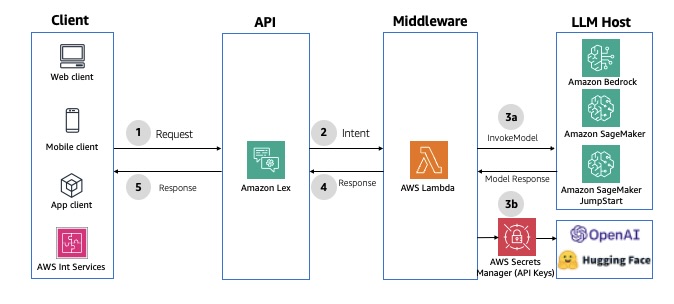
Conversational chatbot interface
Amazon Lex is a service for building conversational interfaces with voice and text, offering speech recognition and language understanding capabilities. It simplifies multimodal development and enables publication of chatbots to various chat services and mobile devices.
Model invocation using orchestration
AWS Step Functions enables orchestration and coordination of multiple tasks, with native integrations across AWS services like Amazon API Gateway, AWS Lambda, and Amazon DynamoDB.
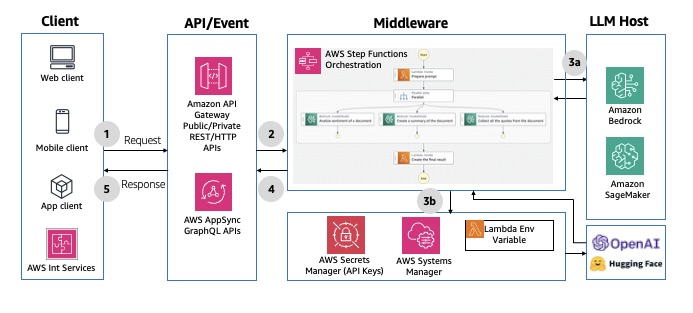
Pattern 2: Asynchronous Request-Response
This pattern provides a full-duplex, bidirectional communication channel between the client and server without clients having to wait for updates. The biggest advantages is its non-blocking nature that can handle long-running operations. However, they are more complex to implement because they require channel, message, and state management.
-
The request is submitted, and the response is delivered via polling or a callback.
-
Allows long-running operations without blocking client.
Implementation:
-
Uses services like Amazon SQS, SNS, or EventBridge.
-
Clients can poll or subscribe to notification mechanisms.
Use Cases:
-
Background processing
-
Multi-document summarization
-
Secure, queue-based workloads
This model can be implemented through two architectural approaches.
WebSocket APIs
The WebSocket protocol enables real-time, synchronous communication between the frontend and middleware, allowing for bidirectional, full-duplex messaging over a persistent TCP connection.
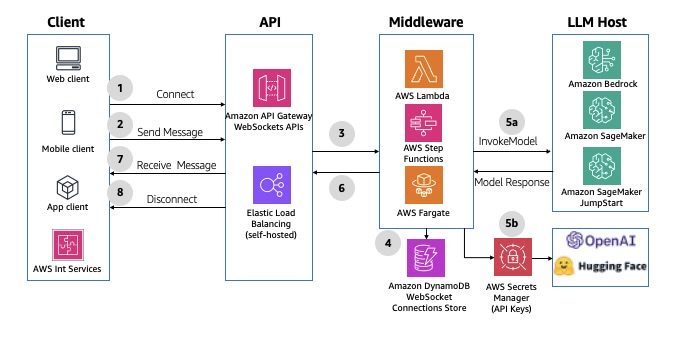
GraphQL WebSocket APIs
AWS AppSync can establish and maintain secure WebSocket connections for GraphQL subscription operations, enabling middleware applications to distribute data in real time from data sources to subscribers. It also supports a simple publish-subscribe model, where client frontends can listen to specific channels or topics
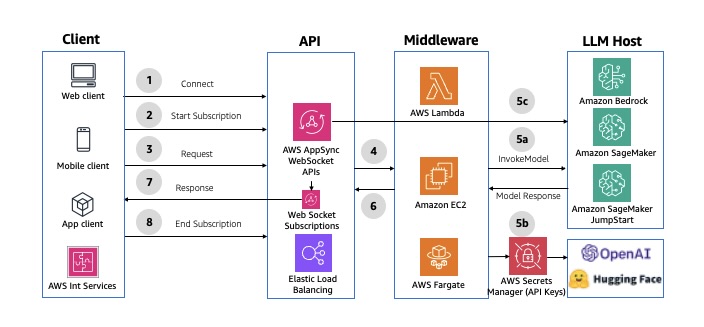
Pattern 3: Asynchronous Streaming Response
This streaming pattern enables real-time response flow to clients in chunks, enhancing the user experience and minimizing first response latency. This pattern uses built-in streaming capabilities in services like Amazon Bedrock
-
The client receives partial results as the model generates them.
-
Enhances user experience for chat interfaces and long-form text.
Implementation:
-
WebSocket APIs via API Gateway
-
Streaming through Amazon Bedrock
-
Lambda for function execution and streaming buffers
Use Cases:
-
Conversational AI
-
Live text generation
-
Code assistant interfaces
The following diagram illustrates the architecture of asynchronous streaming using API Gateway WebSocket APIs.
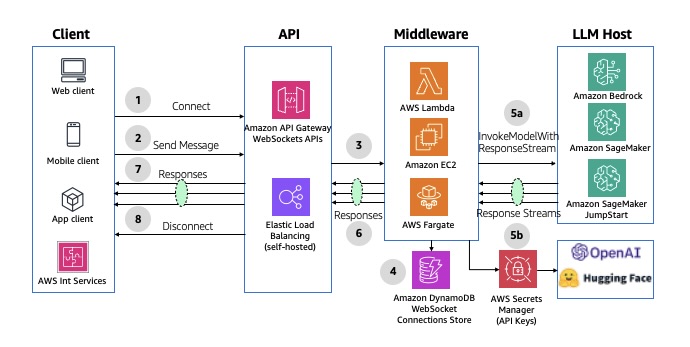
The following diagram illustrates the architecture of asynchronous streaming using AWS AppSync WebSocket APIs.
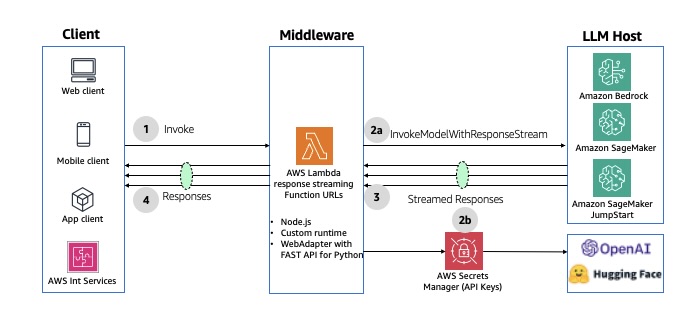
If you don’t need an API layer, Lambda response streaming lets a Lambda function progressively stream response payloads back to clients.
🧠 Choosing the Right Pattern
Each pattern serves different needs. When designing your system, consider:
-
Desired user experience (interactive vs. delayed)
-
Model latency and runtime
-
Infrastructure constraints (timeouts, resource limits)
-
API Gateway and Lambda service quotas
-
Security and compliance needs
🔜 What’s Next?
This article focused on real-time interactions. Part 2 will explore batch-oriented generative AI patterns—suitable for scenarios like document processing, analytics generation, and large-scale content creation.