Why Use Markdown?
1. Better AI Processing
- Semantic understanding: AI models process continuous text more effectively than fragmented cell data
- Context preservation: Paragraph-based content maintains relationships between information
- Effective retrieval: Vector embeddings capture meaning better from natural language text
- Natural chunking: Content splits logically by sections, preserving context in each chunk
2. Cost Efficiency
- Smaller storage: Plain text (5-10KB) vs Excel with formatting overhead (50-100KB+)
- Lower token usage: Markdown structure is simpler, reducing embedding and processing tokens
- Faster processing: Text parsing is significantly faster than Excel binary format
3. Operational Benefits
- Version control friendly: Git tracks line-by-line changes effectively
- Universal editing: Any text editor works, no proprietary software needed
- Better collaboration: Merge conflicts are easier to resolve in plain text
- Automation ready: Easily integrated into CI/CD and documentation workflows
4. When to Use Excel?
XLSX may be suitable when:
- You need structured tabular data with calculations/formulas
- Data is primarily numerical with specific formatting requirements
- Direct import/export with database systems or business intelligence tools
- Non-technical users need to edit data in familiar spreadsheet interface
However, for knowledge bases consumed by AI, converting to Markdown yields better results even for tabular data.
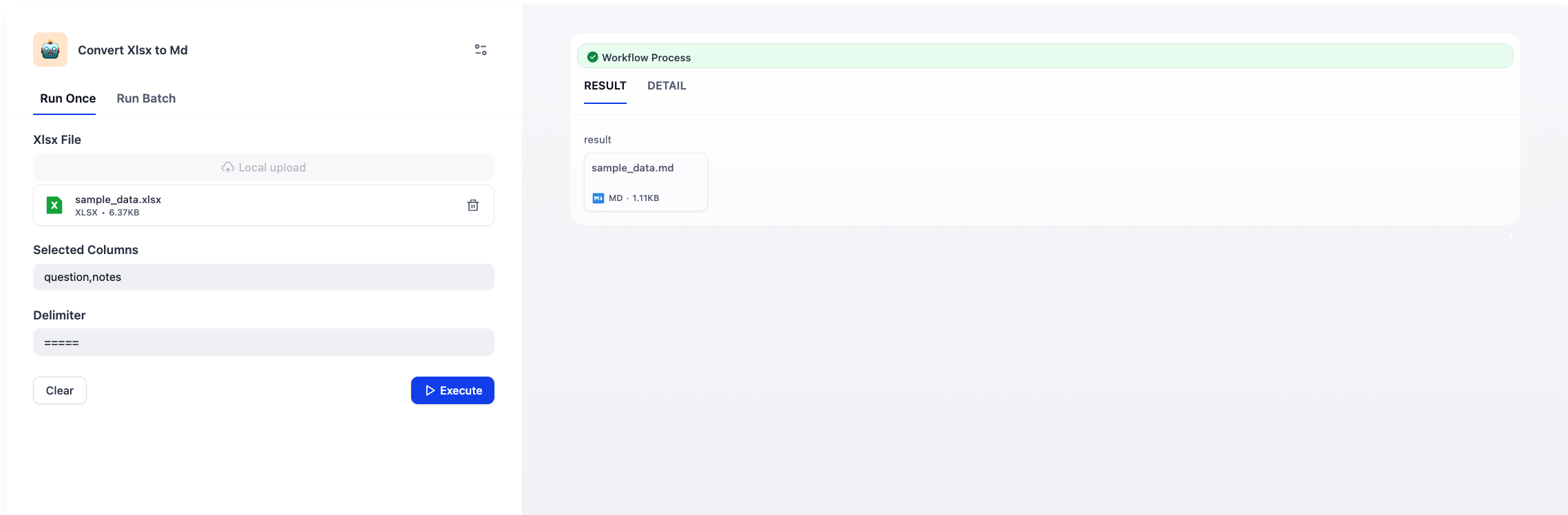
Demo: Converting XLSX to MD
You can create a custom plugin tool on Dify to convert Excel files to Markdown. Here’s how I built mine:
Implementation Steps
- Accept XLSX file input
- Require Xlsx File parameter and wrap its blob in a BytesIO stream
- Configure column selection
- Extract Selected Columns parameter (accepts list/JSON string/comma-separated string)
- Ensure it is non-empty
- Set delimiter
- Resolve Delimiter parameter for separating entries
- Parse Excel file
- Read the first worksheet into a DataFrame using pandas
- Verify all requested columns exist in the DataFrame header
- Subset DataFrame to selected columns only
- Normalize NaN values to
None
- Transform to structured data
- Convert each row into a dictionary keyed by selected column names
- If no rows remain, emit message indicating no data and stop
- Generate Markdown
- Build content by writing
column: valuelines per row - Append delimiter between entries
- Join all blocks into final Markdown
- Build content by writing
- Output file
- Derive filename from uploaded file metadata
- Emit blob message with Markdown bytes and metadata
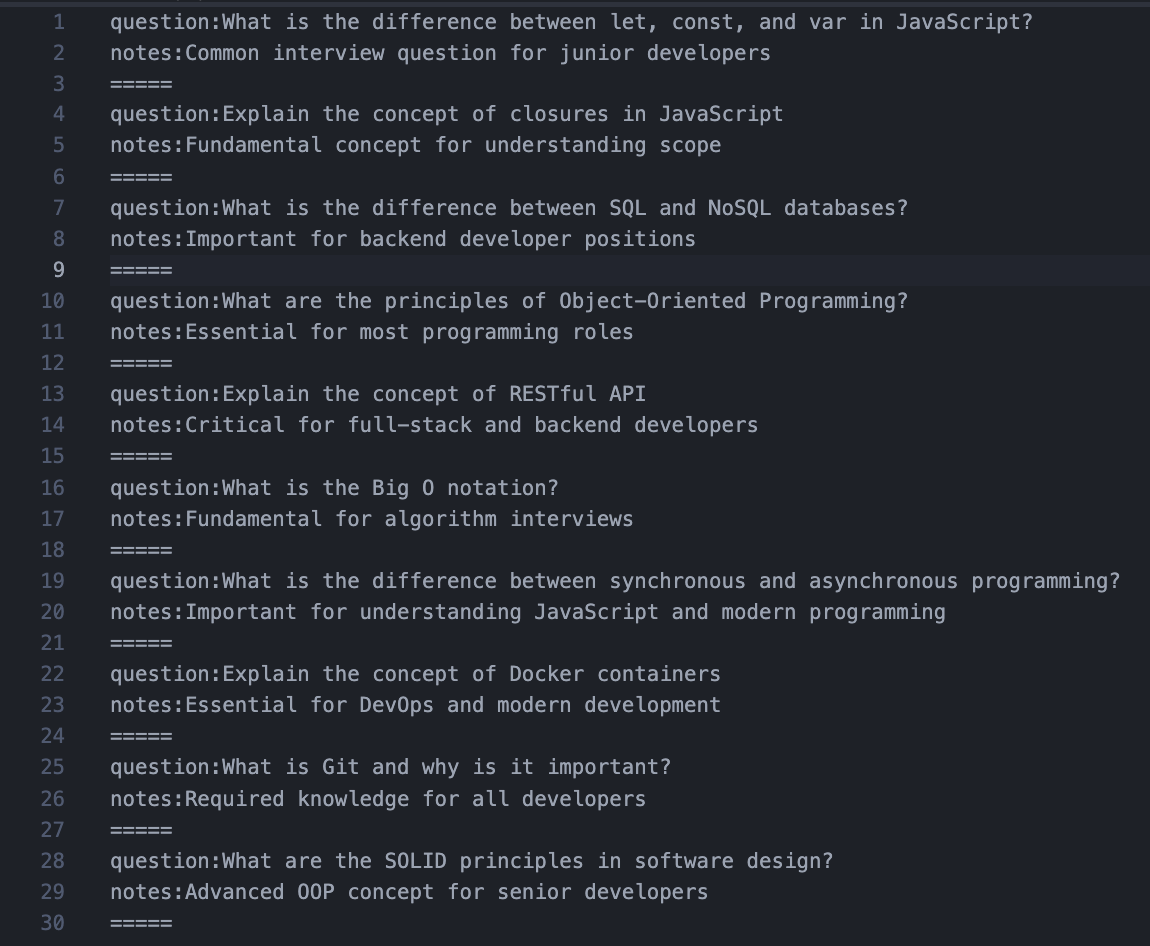
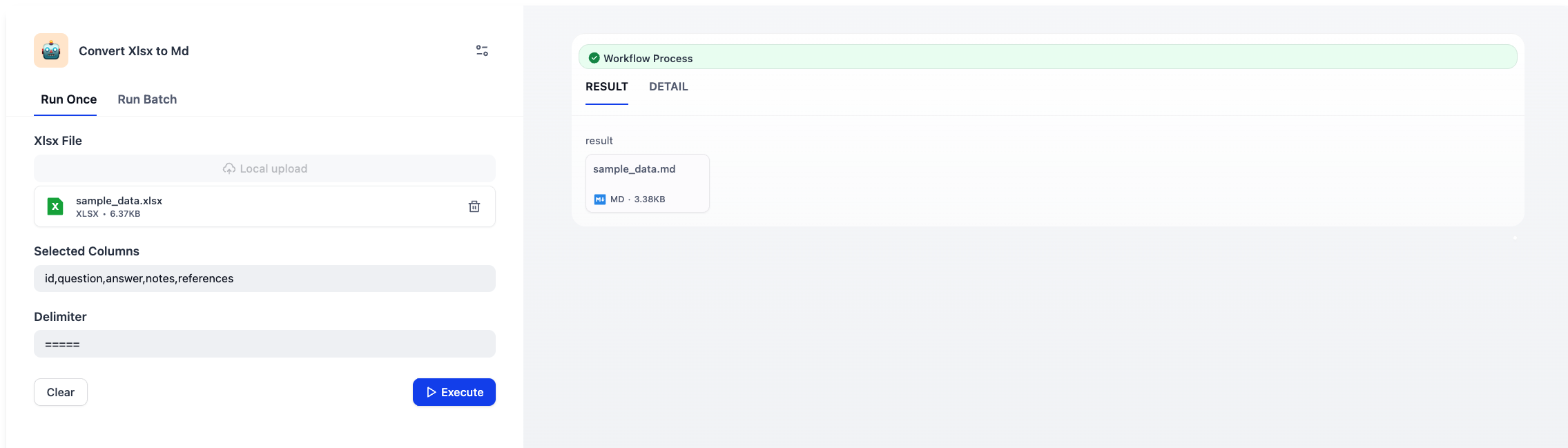
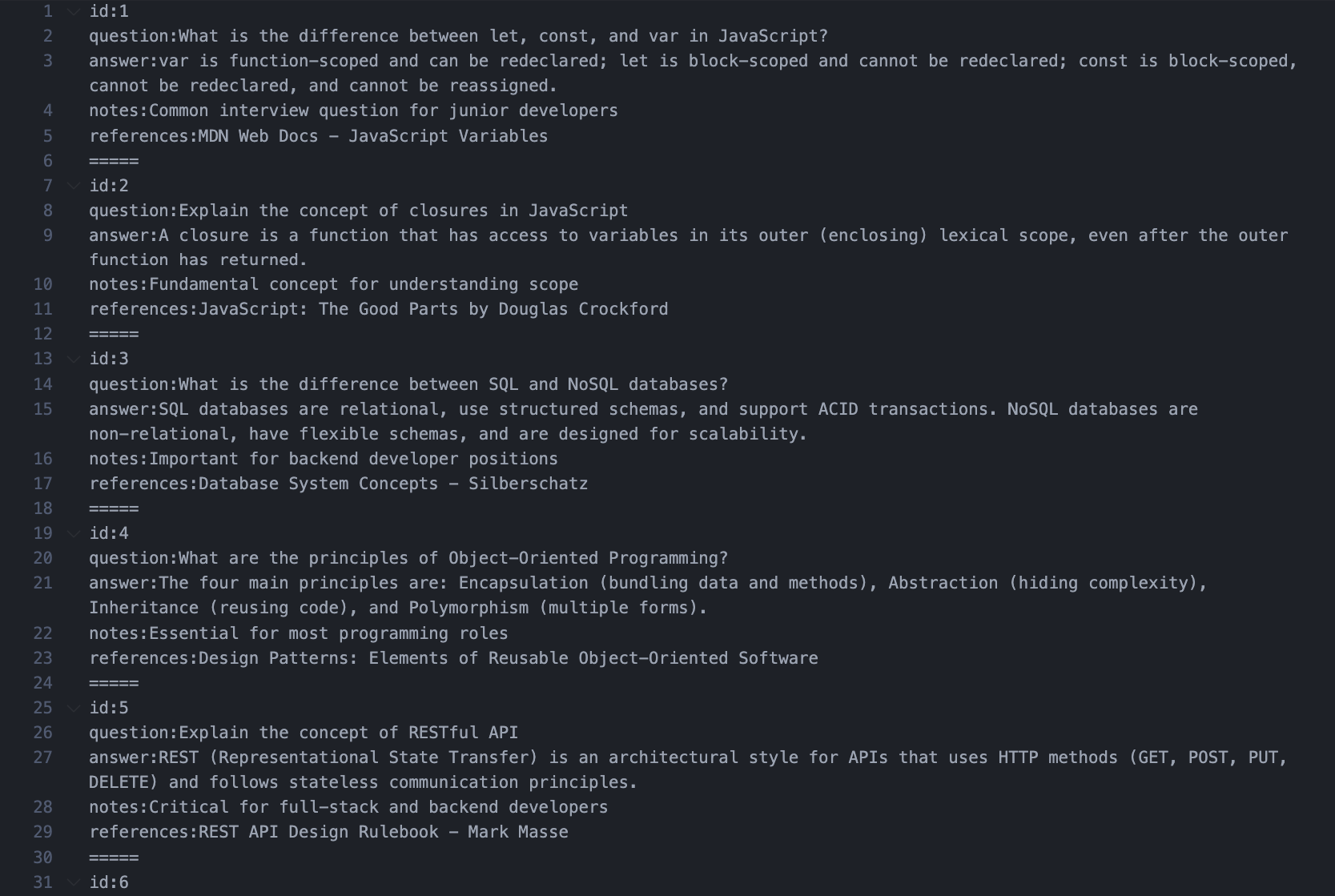
Sample
Input

Output