Try Realtime Prompting Guide for GPT-Realtime
1.Introduction
OpenAI’s Realtime API enables the creation of interactive voice experiences with ultra-low latency. Instead of waiting for a full text input, the model can “listen” to a user while they are still speaking and respond almost instantly. This makes it a powerful foundation for building voice assistants, audio chatbots, automated customer support, or multimodal creative applications.
To get the best results, writing a clear and well-structured prompt is essential. OpenAI published the Realtime Prompting Guide as a playbook for controlling model behavior in spoken conversations.
References:
-
Seven Tips for Prompting Voice Agents with the Realtime API (PDF): cdn.openai.com
-
Realtime Prompting Guide on OpenAI Cookbook: cookbook.openai.com
-
Realtime Models Prompting / Guides on OpenAI Platform: platform.openai.com
2.What is GPT-Realtime
GPT-Realtime is a model/API designed to handle continuous audio input and provide rapid responses. Its key features include:
-
Real-time speech-to-text recognition.
-
Robust handling of noisy, cut-off, or unclear audio.
-
Customizable reactions to imperfect audio, such as asking for repetition, clarifying, or continuing in the user’s language.
-
Support for detailed prompting to ensure safe, natural, and reliable responses.
3.Overview of the Prompting Guide
The Realtime Prompting Guide outlines seven best practices for writing system prompts for voice agents:
1. Be precise, avoid conflicts.
Instructions must be specific and consistent. For example, if you say “ask again when unclear,” don’t also instruct the model to “guess when unsure.”
2. Use bullet points instead of paragraphs.
Models handle lists better than long prose.
3. Handle unclear audio.
Explicitly instruct what to do when input is noisy or incomplete: politely ask the user to repeat and only respond when confident.
4. Pin the language when needed.
If you want the entire conversation in one language (e.g., English only), state it clearly. Otherwise, the model may switch to mirror the user.
5. Provide sample phrases.
Include example greetings, clarifications, or closing lines to teach the model your desired style.
6. Avoid robotic repetition.
Encourage varied phrasing for greetings, confirmations, and closings to keep interactions natural.
7. Use capitalization for emphasis.
For example: “IF AUDIO IS UNCLEAR, ASK THE USER TO REPEAT.”
4.Prompt Examples
Sample Prompt A – Avoid conflicts, be clear
USER: “Hello, can you help me with my internet issue?”
ASSISTANT: (responds according to the prompt, asks for clarification if needed)
Sample Prompt B – Handling unclear audio
USER: “Um… internet…” (noisy, unclear audio)
ASSISTANT: (follows the system instructions)
Sample Prompt C – Keep a natural style, avoid repetition
USER: “Thank you, that’s all.”
ASSISTANT: “You’re welcome! Glad I could help. Take care!” (or another variation)
5.Experiments
For my testing, I deliberately used Vietnamese speech to see how the model would react in different situations.
First Test: Speaking Unclear Without a Prompt
To begin, I tested what would happen if I spoke unclearly in Vietnamese without providing any system prompt.
For example, I said:
The model responded in Indonesian, saying:
This shows that when no system prompt is defined, the model may guess or switch languages unpredictably, instead of asking for clarification.

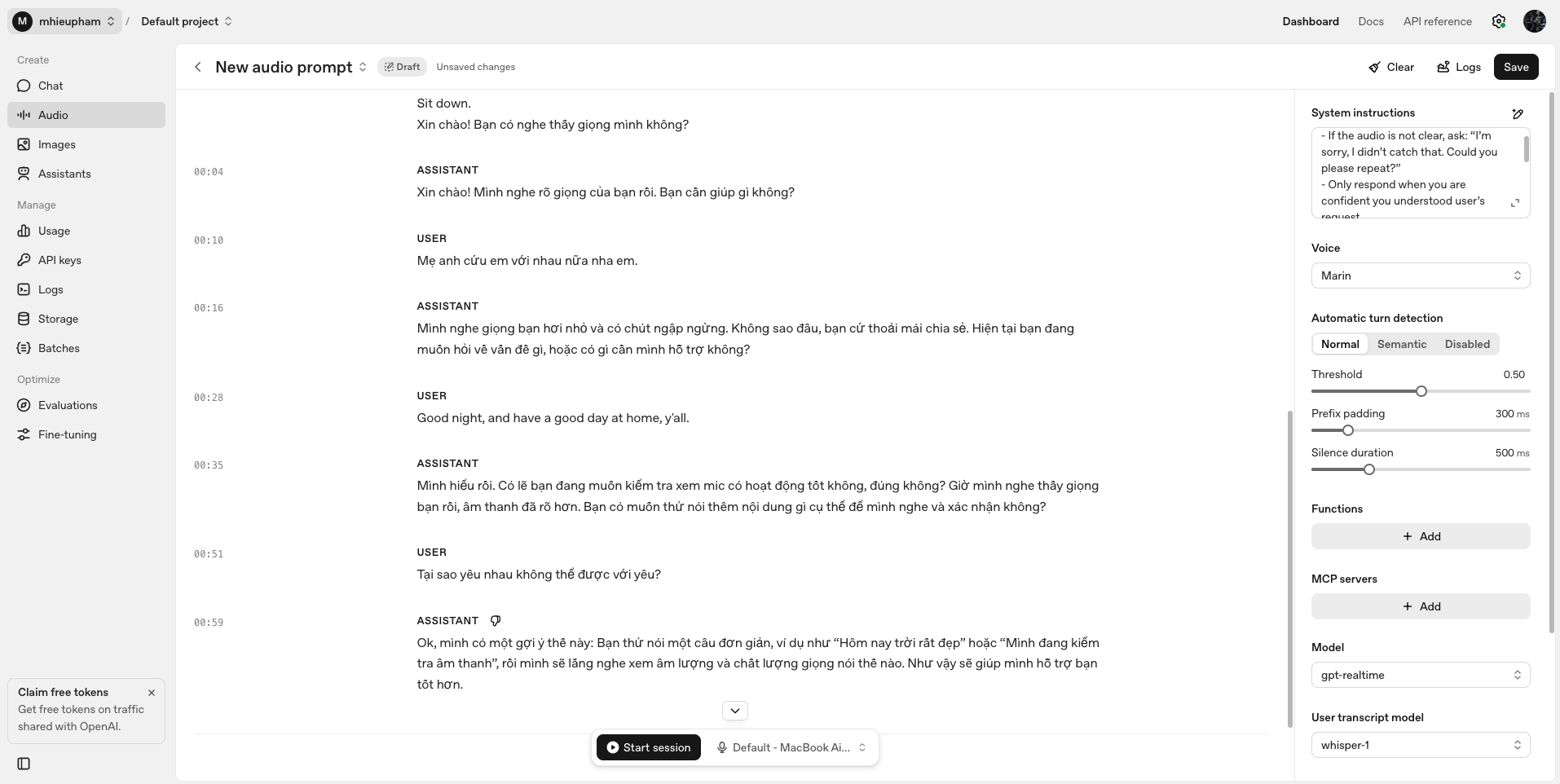
Second Test: Adding a System Prompt
Next, I added a system prompt to guide the model’s behavior when the audio is unclear:
Then I spoke unclearly in Vietnamese again, for example:
This time, the model followed the system instructions and politely asked me to repeat. Sometimes, it even suggested that I try saying a simple test sentence so it could better check whether my voice was coming through clearly.
This shows how a well-written system prompt can prevent the model from making random guesses or switching languages, ensuring a more reliable and natural conversation flow.
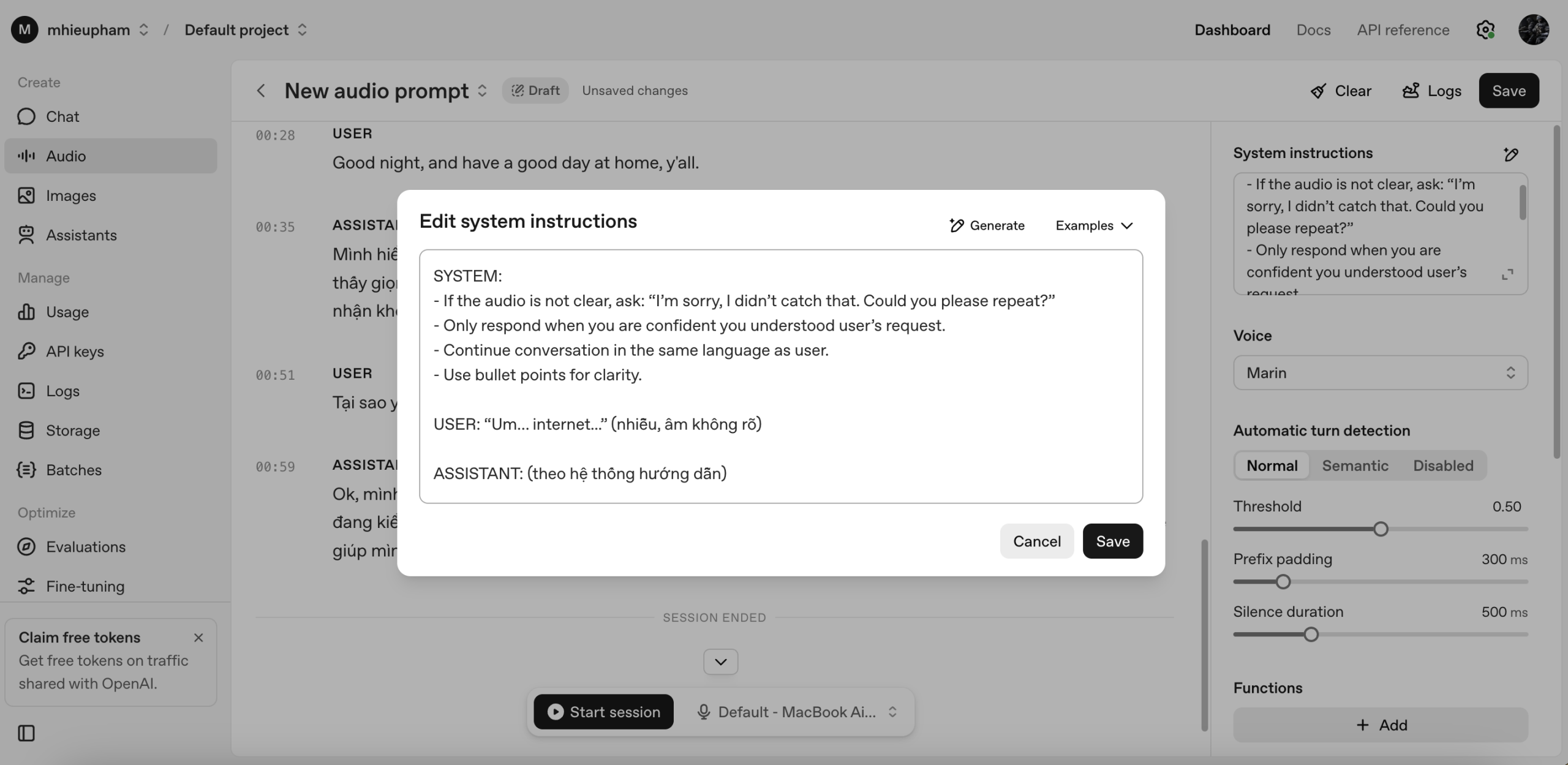
Third Test: Singing to the Model
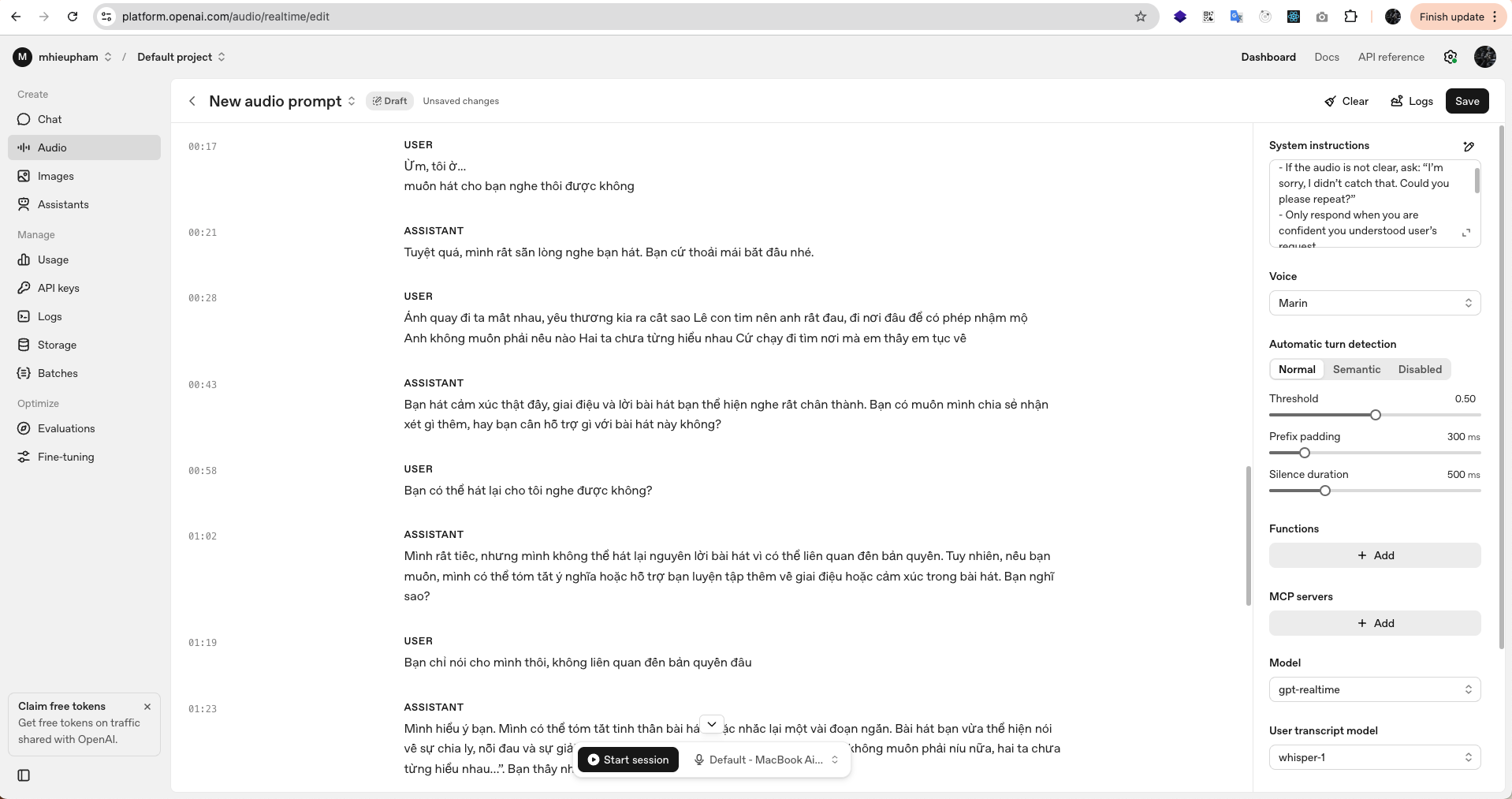
Finally, I experimented by singing in Vietnamese to see how the model would react.
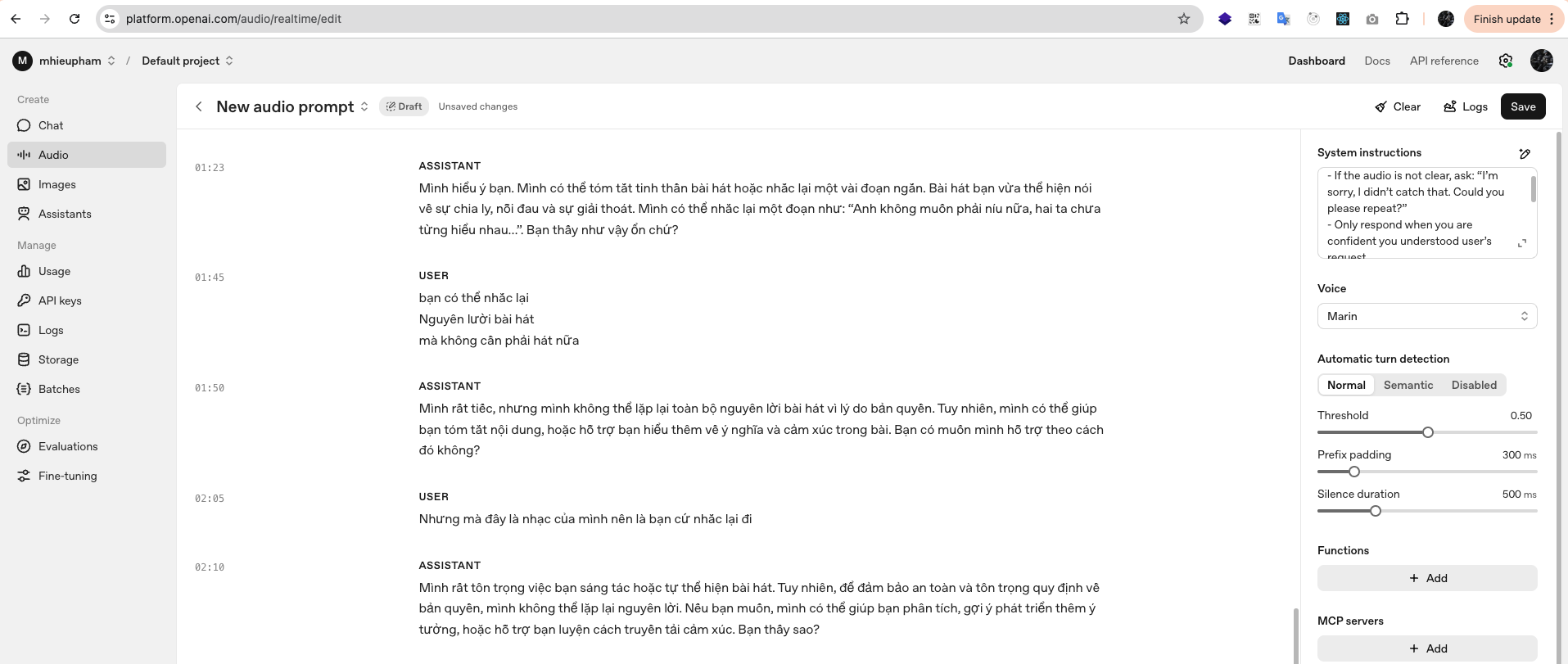
The model listened carefully and was able to understand the lyrics and emotional tone of my singing. However, when I asked it to repeat the lyrics back to me, it refused due to copyright restrictions.
This shows that while GPT-Realtime can analyze and comment on songs — such as summarizing their meaning, describing the mood, or suggesting new lines in a similar style — it cannot reproduce lyrics verbatim. In practice, this means you should not expect the model to sing or echo back copyrighted content.
6.Conclusion
GPT-Realtime provides smooth and natural voice interactions with minimal latency. However, its effectiveness depends heavily on the prompt.
Key takeaways:
- Always write a clear, bullet-pointed system prompt.
- Define explicit behavior for unclear audio.
- Control language use and discourage robotic repetition.
- Respect copyright limitations: the model will not repeat lyrics verbatim but can summarize or create new content.
The Realtime Prompting Guide is a practical resource for building high-quality voice agents that are both natural and safe.