In this document, we will explore how to install and run GPT-OSS 20B — a powerful open-weight language model released by OpenAI — locally, with detailed instructions for using it on a Tesla P40 GPU.
1. Quick Introduction to GPT-OSS 20B
-
GPT-OSS 20B is an open-weight language model from OpenAI, released in August 2025—the first since GPT-2—under the Apache 2.0 license, allowing free download, execution, and modification.
-
The model has about 21 billion parameters and can run efficiently on consumer machines with at least 16 GB of RAM or GPU VRAM.
-
GPT-OSS 20B uses a Mixture-of-Experts (MoE) architecture, activating only a subset of parameters (~3.6B) at each step, saving resources and energy.
-
The model supports chain-of-thought reasoning, enabling it to understand and explain reasoning processes step by step.
2. Hardware & Software Preparation
Hardware requirements:
-
RAM or VRAM: minimum 16 GB (can be system RAM or GPU VRAM).
-
Storage: around 12–20 GB for the model and data.
-
Operating system: macOS 11+, Windows, or Ubuntu are supported.
-
GPU (if available): Nvidia or AMD for acceleration. Without a GPU, the model still runs on CPU but very slowly.
Software options:
-
Ollama: the simplest method; quick installation with a convenient CLI.
-
LM Studio: a graphical interface, suitable for beginners.
-
Transformers + vLLM (Python): flexible for developers, integrates well into open-source pipelines.
3. How to Run GPT-OSS 20B with Ollama (GPU Tesla P40)
3.1 Goal and Timeline
-
Goal: successfully run GPT-OSS 20B locally using Ollama, leveraging the Tesla P40 GPU (24GB VRAM).
-
Timeline: the first setup takes about 15–20 minutes to download the model. After that, launching the model takes only a few seconds.
3.2 Environment Preparation
-
GPU: Tesla P40 with 24GB VRAM, sufficient for GPT-OSS 20B.
-
NVIDIA Driver: version 525 or higher recommended. In the sample logs, CUDA 12.0 works fine.
-
RAM: minimum 16GB.
-
Storage: at least 20GB free space; the model itself takes ~13GB plus cache.
-
Operating system: Linux (Ubuntu), macOS, or Windows. The following example uses Ubuntu.
3.3 Install Ollama
The fastest way:
Or manually (Linux):
Start the Ollama service:
OLLAMA_HOST=0.0.0.0:8888 ollama serve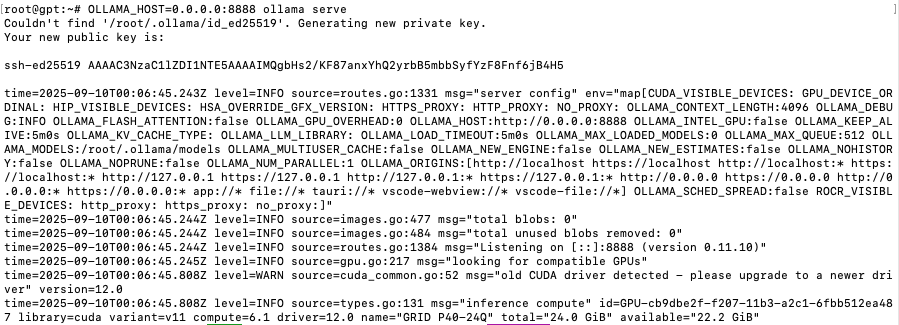
When the log shows listening on [::]:8888, the server is ready.
3.4 Download GPT-OSS 20B
Open a new terminal and run:
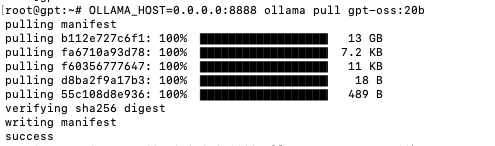
The first download is about 13GB. When the log shows success, the model is ready.
3.5 Run the Model
Start the model and try chatting:
Example:
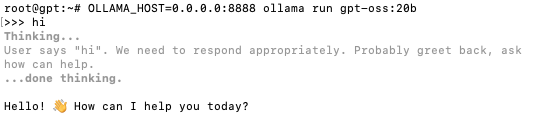
3.6 Verify GPU Usage
Run:
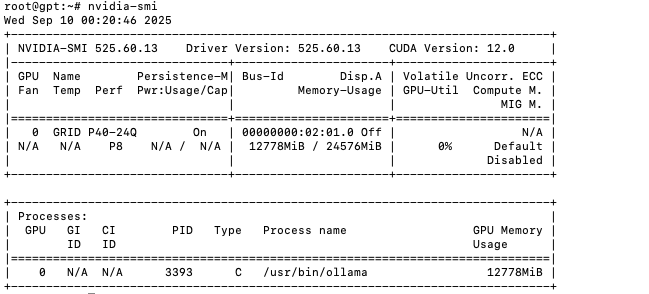
Result: the Tesla P40 (24GB) consumes around 12–13GB VRAM for the process /usr/bin/ollama. The Ollama log also shows “offloading output layer to GPU” and “llama runner started in 8.05 seconds”, proving the model is running on GPU, not CPU.
3.7 Monitor API and Performance
Ollama exposes a REST API at http://127.0.0.1:8888.
Common endpoints include /api/chat and /api/generate.

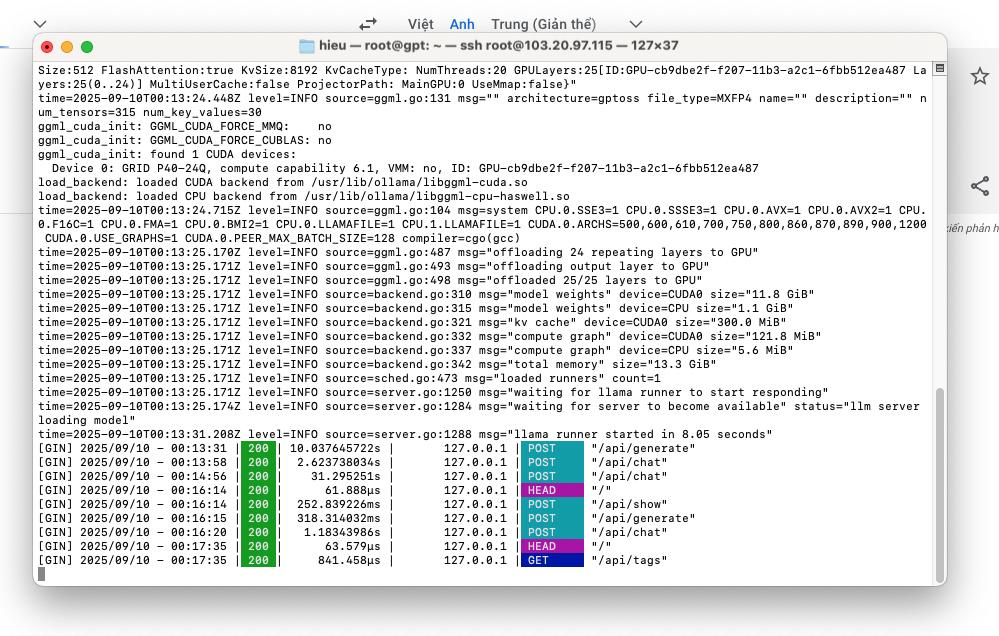
Response times:
-
Short prompts: about 2–10 seconds.
-
Long or complex prompts: may take tens of seconds to a few minutes.
4. Conclusion
You have successfully run GPT-OSS 20B on a Tesla P40. The initial model download takes some time, but afterward it launches quickly and runs stably. With 24GB VRAM, the GPU can handle the large model without overload. While long prompts may still be slow, it is fully usable for real-world experiments and local project integration.